|
|
Awesome, thanks!
Hi, This problem has been fixed[1] in 1.12.0,1.10.3,1.11.3, but release-1.11.3 and release-1.12.0 have not been released yet (VOTE has been passed). I run your job in release-1.12, and the plan is correct. [1] https://issues.apache.org/jira/browse/FLINK-19675Best, Xingbo
Hello, I am trying to use Flink v1.11.2 with Python and the Table API to read and write back messages to kafka topics. I am trying to filter messages based on the output of a udf which returns a boolean. It seems that Flink ignores the WHERE clause in my queries and every input message is received in the output topic. The input table is declared in SQL: --sql
CREATE TABLE teams_event (
`payload` ROW(
`createdDateTime` STRING,
`body` ROW(
`content` STRING
),
`from` ROW(
`user` ROW(
`displayName` STRING
)
),
`channelIdentity` ROW(
`channelId` STRING
)
)
) WITH (
'connector' = 'kafka',
'topic' = 'xdr.ms_teams2.events.messages',
'properties.bootstrap.servers' = 'senso-kafka.solexdc01.bitdefender.biz:29030',
'properties.group.id' = 'teams_profanity_filter',
'format' = 'json',
'scan.startup.mode' = 'earliest-offset',
'json.fail-on-missing-field' = 'false',
'json.timestamp-format.standard' = 'ISO-8601'
)
""" The output table is also declared in sql: --sql
CREATE TABLE teams_profanity_event (
`createdAt` STRING,
`censoredMessage` STRING,
`username` STRING,
`channelId` STRING
) WITH (
'connector' = 'kafka',
'topic' = 'internal.alerts.teams.rude_employees2',
'properties.bootstrap.servers' = 'senso-kafka.solexdc01.bitdefender.biz:29030',
'format' = 'json'
) I have declared two udfs and registered them in the table environment @udf(input_types=[
DataTypes.ROW([
DataTypes.FIELD("createdDateTime", DataTypes.STRING()),
DataTypes.FIELD("body", DataTypes.ROW([
DataTypes.FIELD("content", DataTypes.STRING())
])),
DataTypes.FIELD("from", DataTypes.ROW([
DataTypes.FIELD("user", DataTypes.ROW([
DataTypes.FIELD("displayName", DataTypes.STRING())
]))
])),
DataTypes.FIELD("channelIdentity", DataTypes.ROW([
DataTypes.FIELD("channelId", DataTypes.STRING())
]))
])],
result_type=DataTypes.BOOLEAN())
def contains_profanity(payload):
message_content = payload[1][0]
found_profanity = profanity.contains_profanity(message_content)
logger.info(f'Message "{message_content}" contains profanity: {found_profanity}')
return found_profanity
@udf(input_types=[
DataTypes.ROW([
DataTypes.FIELD("createdDateTime", DataTypes.STRING()),
DataTypes.FIELD("body", DataTypes.ROW([
DataTypes.FIELD("content", DataTypes.STRING())
])),
DataTypes.FIELD("from", DataTypes.ROW([
DataTypes.FIELD("user", DataTypes.ROW([
DataTypes.FIELD("displayName", DataTypes.STRING())
]))
])),
DataTypes.FIELD("channelIdentity", DataTypes.ROW([
DataTypes.FIELD("channelId", DataTypes.STRING())
]))
])],
result_type=DataTypes.STRING())
def censor_profanity(payload):
message_content = payload[1][0]
censored_message = profanity.censor(message_content)
logger.info(f'Censored message: "{censored_message}"')
return censored_message The filtering of the messages and insertion into the sink is declared with SQL: --sql
INSERT INTO teams_profanity_event (
SELECT `payload`.`createdDateTime`,
censor_profanity(`payload`),
`payload`.`from`.`user`.`displayName`,
`payload`.`channelIdentity`.`channelId`
FROM teams_event
WHERE contains_profanity(`payload`)
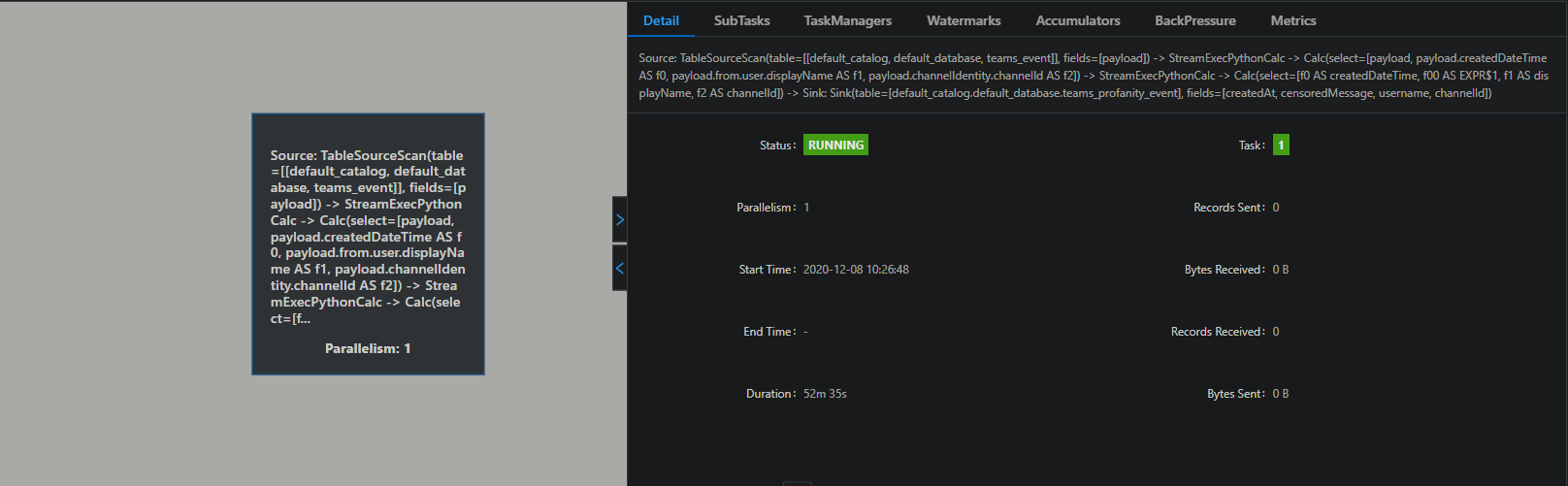
) Am I doing something wrong? It seems that the contains_profanity udf is not used in the pipeline:  Thank you in advance!
|