PrometheusReporter error


|
Hi,
First of all, thanks to Maximilian Bode for a Prometheus reporter. Thanks to it, now I can count entirely on Prometheus to collect metrics from various sources including Flink as shown below: 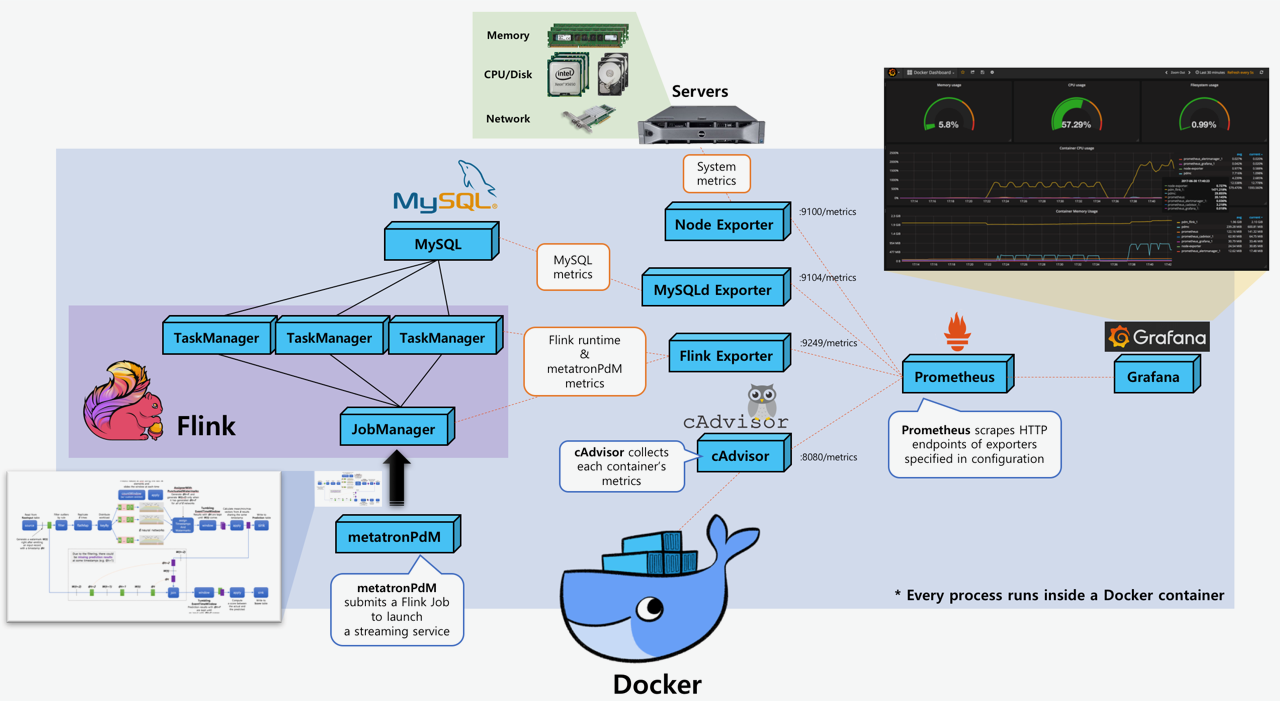 To test it, I took the following steps
While JobManager works okay with Prometheus reporter (I found that Prometheus scraped it successfully every 5 sec as expected), TaskManager complains as follows when it boots up: --------------------------------- 2017-07-03 18:07:00,734 INFO org.apache.flink.runtime.taskmanager.TaskManager - Starting TaskManager actor at <a href="akka://flink/user/taskmanager#-21882459" class="">akka://flink/user/taskmanager#-21882459. 2017-07-03 18:07:00,735 INFO org.apache.flink.runtime.taskmanager.TaskManager - TaskManager data connection information: 96fee790eabe7df19322147f7d8634b5 @ DNN-G08-235 (dataPort=46188) 2017-07-03 18:07:00,735 INFO org.apache.flink.runtime.taskmanager.TaskManager - TaskManager has 1 task slot(s). 2017-07-03 18:07:00,737 INFO org.apache.flink.runtime.taskmanager.TaskManager - Memory usage stats: [HEAP: 113/1024/1024 MB, NON HEAP: 36/37/-1 MB (used/committed/max)] 2017-07-03 18:07:00,741 INFO org.apache.flink.runtime.taskmanager.TaskManager - Trying to register at JobManager <a href="akka.tcp://flink@pdm4:6123/user/jobmanager" class="">akka.tcp://flink@pdm4:6123/user/jobmanager (attempt 1, timeout: 500 milliseconds) 2017-07-03 18:07:00,885 INFO org.apache.flink.runtime.taskmanager.TaskManager - Successful registration at JobManager (<a href="akka.tcp://flink@pdm4:6123/user/jobmanager" class="">akka.tcp://flink@pdm4:6123/user/jobmanager), starting network stack and library cache. 2017-07-03 18:07:00,892 INFO org.apache.flink.runtime.taskmanager.TaskManager - Determined BLOB server address to be pdm4/50.1.100.234:41010. Starting BLOB cache. 2017-07-03 18:07:00,896 INFO org.apache.flink.runtime.blob.BlobCache - Created BLOB cache storage directory /tmp/blobStore-bad71755-c7a3-4179-8e70-ea42ff73cdde 2017-07-03 18:07:00,902 ERROR org.apache.flink.runtime.metrics.MetricRegistry - Error while registering metric. java.lang.IllegalArgumentException: Collector already registered that provides name: flink_taskmanager_Status_JVM_ClassLoader_ClassesLoaded at org.apache.flink.shaded.io.prometheus.client.CollectorRegistry.register(CollectorRegistry.java:54) at org.apache.flink.shaded.io.prometheus.client.Collector.register(Collector.java:128) at org.apache.flink.shaded.io.prometheus.client.Collector.register(Collector.java:121) at org.apache.flink.metrics.prometheus.PrometheusReporter.notifyOfAddedMetric(PrometheusReporter.java:133) at org.apache.flink.runtime.metrics.MetricRegistry.register(MetricRegistry.java:296) at org.apache.flink.runtime.metrics.groups.AbstractMetricGroup.addMetric(AbstractMetricGroup.java:370) at org.apache.flink.runtime.metrics.groups.AbstractMetricGroup.gauge(AbstractMetricGroup.java:314) at org.apache.flink.runtime.metrics.util.MetricUtils.instantiateClassLoaderMetrics(MetricUtils.java:90) at org.apache.flink.runtime.metrics.util.MetricUtils.instantiateStatusMetrics(MetricUtils.java:80) at org.apache.flink.runtime.taskmanager.TaskManager.associateWithJobManager(TaskManager.scala:989) at org.apache.flink.runtime.taskmanager.TaskManager.org$apache$flink$runtime$taskmanager$TaskManager$$handleRegistrationMessage(TaskManager.scala:627) at org.apache.flink.runtime.taskmanager.TaskManager$$anonfun$handleMessage$1.applyOrElse(TaskManager.scala:287) at scala.runtime.AbstractPartialFunction.apply(AbstractPartialFunction.scala:36) at org.apache.flink.runtime.LeaderSessionMessageFilter$$anonfun$receive$1.applyOrElse(LeaderSessionMessageFilter.scala:38) at scala.runtime.AbstractPartialFunction.apply(AbstractPartialFunction.scala:36) at org.apache.flink.runtime.LogMessages$$anon$1.apply(LogMessages.scala:33) at org.apache.flink.runtime.LogMessages$$anon$1.apply(LogMessages.scala:28) at scala.PartialFunction$class.applyOrElse(PartialFunction.scala:123) at org.apache.flink.runtime.LogMessages$$anon$1.applyOrElse(LogMessages.scala:28) at akka.actor.Actor$class.aroundReceive(Actor.scala:467) at org.apache.flink.runtime.taskmanager.TaskManager.aroundReceive(TaskManager.scala:121) at akka.actor.ActorCell.receiveMessage(ActorCell.scala:516) at akka.actor.ActorCell.invoke(ActorCell.scala:487) at akka.dispatch.Mailbox.processMailbox(Mailbox.scala:238) at akka.dispatch.Mailbox.run(Mailbox.scala:220) at akka.dispatch.ForkJoinExecutorConfigurator$AkkaForkJoinTask.exec(AbstractDispatcher.scala:397) at scala.concurrent.forkjoin.ForkJoinTask.doExec(ForkJoinTask.java:260) at scala.concurrent.forkjoin.ForkJoinPool$WorkQueue.runTask(ForkJoinPool.java:1339) at scala.concurrent.forkjoin.ForkJoinPool.runWorker(ForkJoinPool.java:1979) at scala.concurrent.forkjoin.ForkJoinWorkerThread.run(ForkJoinWorkerThread.java:107) --------------------------------- The error message is repeated for the other metrics:
What's going wrong with it?
Thanks, - Dongwon Kim |
Re: PrometheusReporter error
|
|
Hello,
Are the metrics for which the error occurs still reported correctly? If you submit a job does this also happens for job metrics? I haven't looked into it in detail yet, but I would assume that this is not an issue of the reporter, but something deeper in Flink (like that TM metrics are registered multiple times). On 03.07.2017 12:35, 김동원 wrote: Hi,
|
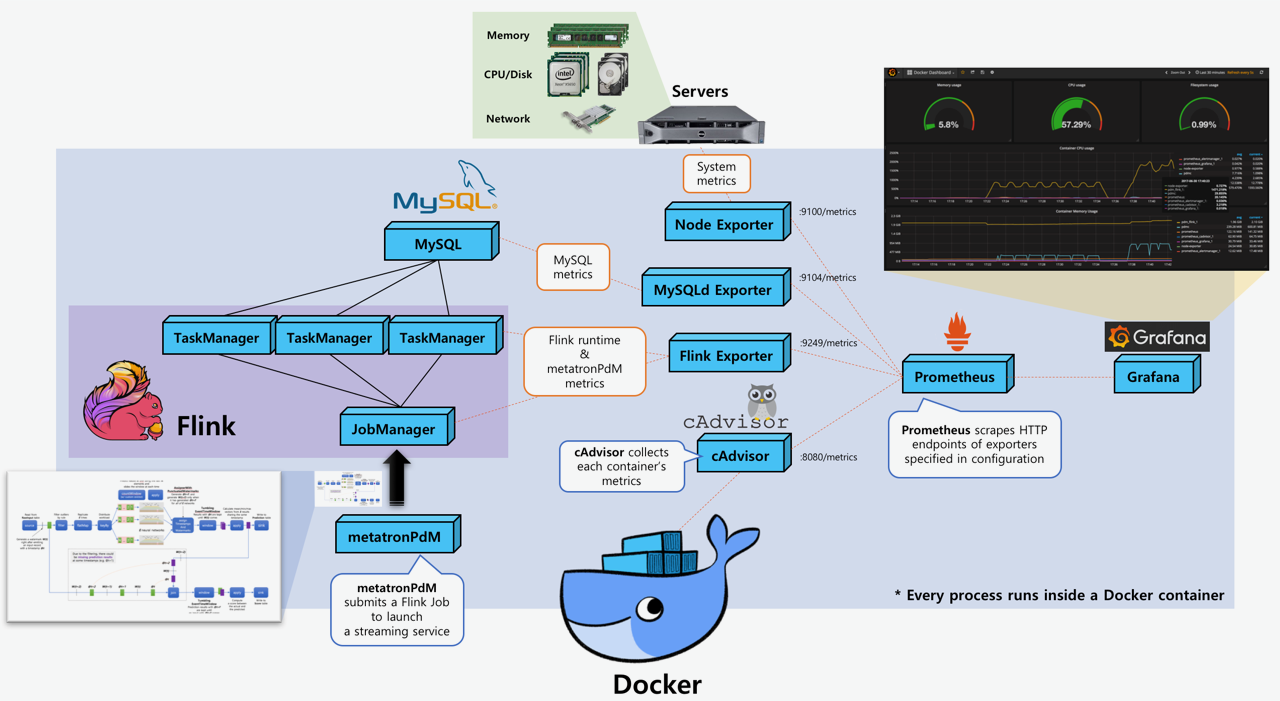
|
|
Let me summarize what happens before submitting a job, which I think will give you enough information :-) To cut a long story short, when I enable PrometheusReporter, TaskManager's metric system seems collapsed during the initialization. before1.png shows that {{ metrics.metrics.directCount | toLocaleString }} and other templates are not substituted by real values. Chrome's inspect pane (right pane) in before2.png shows that a JSON object received from a TM does not have a metrics field. When I disable PrometheusReporter, TaskManager works okay as shown in noprom1.png and noprom2.png. noprom1.png shows that actual values are inside table cells. noprom2.png shows that a JSON object contains a metrics field. The most obvious evidence is that my web browser can connect to JobManager's endpoint (masternode:9249/metrics) but cannot connect to TaskManager's endpoint (workernode:9249/metrics), which means TaskManager's endpoint is not initialized at all and it is totally pointless to test whether it works after submitting a job. Unfortunately there's no other error messages indicating the metric system got collapsed. And the error messages is reproduced every time I start a TaskManager with PrometheusReporter enabled. I also suspect multiple registration but there's no clue. I checked that TaskManager is registered to JobManager only once. I'll try what happens after submitting a job soon and let you know. Thanks, On Mon, Jul 3, 2017 at 9:07 PM, Chesnay Schepler <[hidden email]> wrote:
|
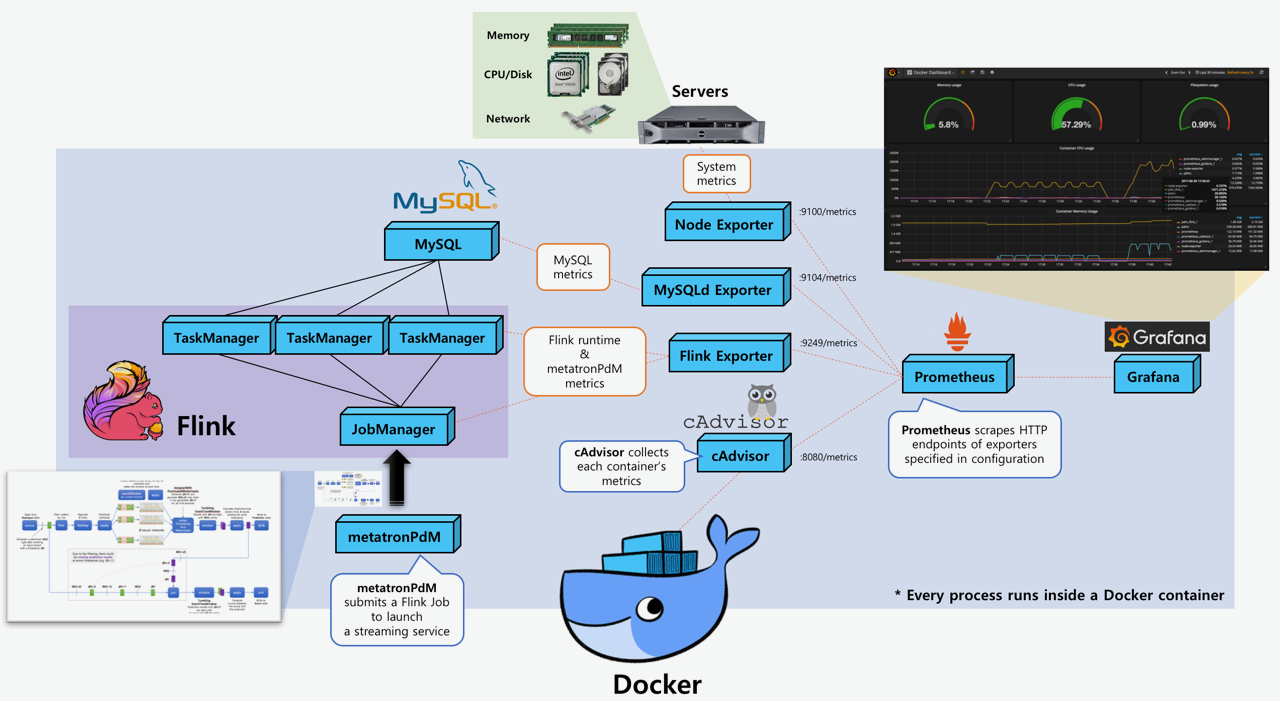
Re: PrometheusReporter error
|
|
When debugging metric issues make sure
to set the logging level to warn or even debug.
Ha, looking through the code it is in fact possible for a single reporter to effectively disable the entire metric system by throwing an exception for every registered metric. On 03.07.2017 15:15, Dongwon Kim wrote:
|

|
|
I attached to a running TaskManager using IntelliJ's remote debugger. As you said, a metric is registered twice to Prometheus's registry. The sequence of metrics passed to io.prometheus.client.CollectorRegistry is as follows: ---- flink_taskmanager_Status_Network_TotalMemorySegments flink_taskmanager_Status_Network_AvailableMemorySegments flink_taskmanager_Status_JVM_ClassLoader_ClassesLoaded <= (A) where ClassesLoaded is registered for the first time flink_taskmanager_Status_JVM_ClassLoader_ClassesUnloaded flink_taskmanager_Status_JVM_ClassLoader_GarbageCollector_PS_Scavenge_Count flink_taskmanager_Status_JVM_ClassLoader_GarbageCollector_PS_Scavenge_Time flink_taskmanager_Status_JVM_ClassLoader_GarbageCollector_PS_MarkSweep_Count flink_taskmanager_Status_JVM_ClassLoader_GarbageCollector_PS_MarkSweep_Time flink_taskmanager_Status_JVM_Memory_Heap_Used flink_taskmanager_Status_JVM_Memory_Heap_Committed flink_taskmanager_Status_JVM_Memory_Heap_Max flink_taskmanager_Status_JVM_Memory_NonHeap_Used flink_taskmanager_Status_JVM_Memory_NonHeap_Committed flink_taskmanager_Status_JVM_Memory_NonHeap_Max flink_taskmanager_Status_JVM_Memory_Direct_Count flink_taskmanager_Status_JVM_Memory_Direct_MemoryUsed flink_taskmanager_Status_JVM_Memory_Direct_TotalCapacity flink_taskmanager_Status_JVM_Memory_Mapped_Count flink_taskmanager_Status_JVM_Memory_Mapped_MemoryUsed flink_taskmanager_Status_JVM_Memory_Mapped_TotalCapacity flink_taskmanager_Status_JVM_Threads_Count flink_taskmanager_Status_JVM_CPU_Load flink_taskmanager_Status_JVM_CPU_Time flink_taskmanager_Status_JVM_ClassLoader_ClassesLoaded <= (B) which causes the first IllegalArgumentException as ClassesLoaded is registered before flink_taskmanager_Status_JVM_ClassLoader_ClassesUnloaded flink_taskmanager_Status_JVM_GarbageCollector_G1_Young_Generation_Count flink_taskmanager_Status_JVM_GarbageCollector_G1_Young_Generation_Time flink_taskmanager_Status_JVM_GarbageCollector_G1_Old_Generation_Count flink_taskmanager_Status_JVM_GarbageCollector_G1_Old_Generation_Time flink_taskmanager_Status_JVM_Memory_Heap_Used flink_taskmanager_Status_JVM_Memory_Heap_Committed flink_taskmanager_Status_JVM_Memory_Heap_Max flink_taskmanager_Status_JVM_Memory_NonHeap_Used flink_taskmanager_Status_JVM_Memory_NonHeap_Committed flink_taskmanager_Status_JVM_Memory_NonHeap_Max flink_taskmanager_Status_JVM_Memory_Direct_Count flink_taskmanager_Status_JVM_Memory_Direct_MemoryUsed flink_taskmanager_Status_JVM_Memory_Direct_TotalCapacity flink_taskmanager_Status_JVM_Memory_Mapped_Count flink_taskmanager_Status_JVM_Memory_Mapped_MemoryUsed flink_taskmanager_Status_JVM_Memory_Mapped_TotalCapacity flink_taskmanager_Status_JVM_Threads_Count flink_taskmanager_Status_JVM_CPU_Load flink_taskmanager_Status_JVM_CPU_Time flink_taskmanager_Status_Network_TotalMemorySegments flink_taskmanager_Status_Network_AvailableMemorySegments ---- I found that (A) and (B) are passed to Prometheus from different places; see Callstack_A.png and Callstack_B.png. (I rebuild flink-metrics-prometheus-1.4- TaskManager seems to initialize the metrics before and after registration to JobManager. If this duplicate registration is intended, PrometheusReporter should be cope with it. For the moment, I have to depend on JobManager metrics until it is figured out. On Mon, Jul 3, 2017 at 10:46 PM, Chesnay Schepler <[hidden email]> wrote:
|

|
|
Now everything works okay.
The attached file is a screenshot of my Grafana dashboard in which TaskManager-related metrics are collected to Prometheus by Flink PrometheusReporter. When is flink-1.3.2 released? Hope I can get a new version which contains a fix to FLINK-7069. And no plan to include FLINK-6221 (Prometheus Reporter) in flink-1.3.2? Thanks, On Tue, Jul 4, 2017 at 10:15 PM, Chesnay Schepler <[hidden email]> wrote:
|

|
|
Hello 김동원,
We are experiencing the same issue you were when trying to use the 1.4 prometheus reporter with 1.3: ---- [...] Error while registering metric. java.lang.IllegalArgumentException: Collector already registered that provides name: flink_taskmanager_Status_JVM_CPU_Load [...] ----- The jira bug associated with this remain open, how were you able to stop flink from loading the taskmanager metrics multiple times? -- Sent from: http://apache-flink-user-mailing-list-archive.2336050.n4.nabble.com/ |
|
|
Hi, there is PR open for fixing the multiple TM metrics registration [1]. We hope to get it merged in the next days such that it will be part of the upcoming 1.4 release. Cheers, Till On Thu, Oct 26, 2017 at 5:21 PM, cslotterback <[hidden email]> wrote: Hello 김동원, |
|
|
In reply to this post by cslotterback
Hi, Two Jira issues are mentioned in this thread: - [FLINK-7069] Catch exceptions for each reporter separately : Fixed - [FLINK-7100] TaskManager metrics are registered twice : Unresolved I guess your error message is just an warning message. You can safely ignore it if you are using 1.3.2 or 1.3.3 because FLINK-7069 is included in 1.3.2 release (https://flink.apache.org/news/2017/08/05/release-1.3.2.html). FYI, FLINK-7069 prevents the metric system of JM and TM from being collapsed when a reporter throws an exception by ignoring them. In this case, the exception is thrown because TaskManager tries to register a set of its metrics twice during initialization. I'm still seeing your error messages because FLINK-7100 is not resolved yet. But, again, the error message is just an warning message; just ignore it. It is unavoidable even if FLINK-7100 is resolved because concurrent tasks from a TM also cause similar warning messages for other task-related metrics; each of concurrent tasks tries to register a metric with the same name. If you really do not want to see such warnings, how about adding the following line to your conf/log4j.properties (or log4j-console.properties if you're seeing the error message from console): - log4j.logger.org.apache.flink.runtime.metrics.MetricRegistry=ERROR, file (or ERROR, console in log4j-console.properties) Chesnay: I guess the warning message is quite confusing as it contains a word "Error". - Dongwon On Fri, Oct 27, 2017 at 12:21 AM, cslotterback <[hidden email]> wrote: Hello 김동원, |
«
Return to (DEPRECATED) Apache Flink User Mailing List archive.
|
1 view|%1 views
| Free forum by Nabble | Edit this page |