Possible bug clean up savepoint dump into filesystem and low network IO starting from savepoint

Possible bug clean up savepoint dump into filesystem and low network IO starting from savepoint

|
Hi, yesterday when I was creating a savepoint (to S3, around 8GB of state) using 2 TaskManager (8 GB) and it failed because one of the task managers fill up the disk (probably didn't have enough RAM to save the state into S3 directly,I don't know what was the disk space, and reached 100% usage space and the other one reached 99%).
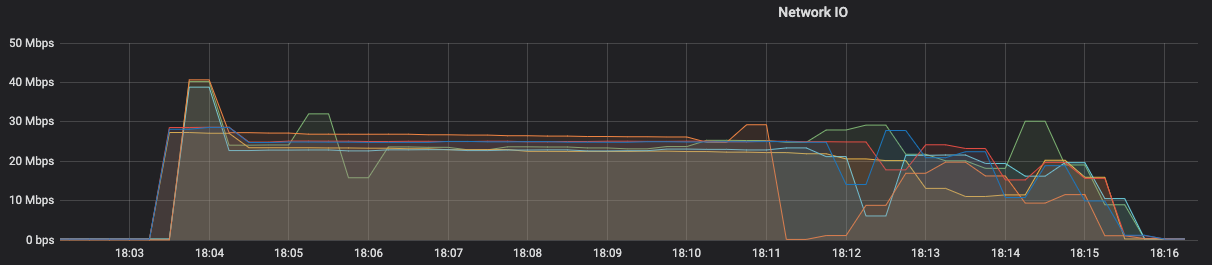
After the crash, the task manager that reach 100% deleted the "failed savepoint" from the local disk but the other one that reached 99% kept it. Shouldn't this task manager also clean up the failed state? After cleaning up the disk of that task manager, I've increased the parallelism to 6, created a new state of 8GB and all went smoothly, but it took 8 minutes to start processing in the new job created with the previous savepoint. 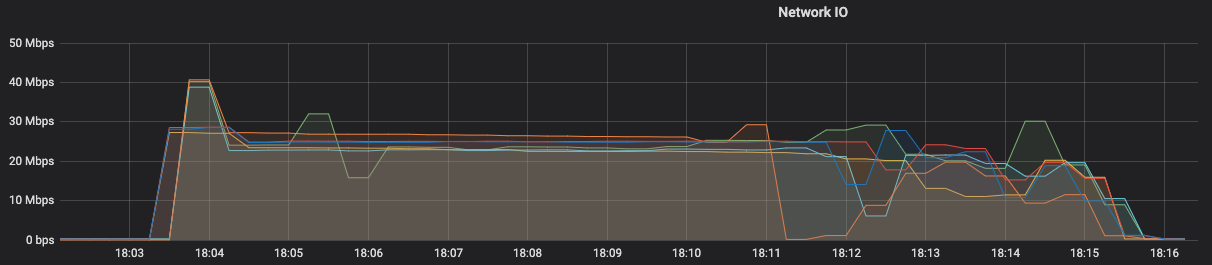 Here is the network IO from the 6 task managers used and I have a few questions: - Isn't 25 Mbps of average speed a bit low? What could be the limitation? - For 8 GB of state, gives around 7 minutes to download it [ 8000 MB /(25Mbps/8*6 task managers)/60 seconds ], that should match the consistent part of 7/8 minute graph, and then started reading from Kafka topic. - Can I mitigate this with task local recovery [1]? Or is this only for a checkpoint ? - We are using m5.xlarge (4 vcpu, 16GB RAM) with 2 slots per TM. Thanks, |
Re: Possible bug clean up savepoint dump into filesystem and low network IO starting from savepoint
|
|
Hi David As you say the savepoint use local disk, I assume that you use RocksDBStateBackend. What's the flink version are you using now? What do you mean "The task manager did not clean up the state"?, does that mean the local disk space did not clean up, do the task encounter failover in this period? The snapshot speed will be limited by the network bandwidth and the local io performance. IIUC, currently only checkpoint support local recovery PS: If you want the snapshot complete quickly, maybe you can try retained checkpoint[1], and multiple threads uploads[2] Best, Congxian David Magalhães <[hidden email]> 于2020年7月10日周五 下午7:37写道:
|
Re: Possible bug clean up savepoint dump into filesystem and low network IO starting from savepoint
|
|
Hi Congxian, sorry for the late reply. I'm using the filesystem with an S3 path as the default state backend in flink-conf.yml (state.backend: filesystem). The Flink version I'm using is 1.10.1. By "The task manager did not clean up the state", I mean what the taskmanager was writing on disk the savepoint file, but it didn't delete it after the other taskmanager had an issue with the disk being full. The expected scenario would be both taskmanagers remove the savepoint they were trying to do from the disk, but only the one that reached 100% disk space use did it. For my scenario, I'm using the Flink REST API to start/deploy jobs. A retained checkpoint isn't supported in REST API and even if it was, I think it doesn't fit my scenario (stop a job, and start the new one from the saved state). Thanks, David On Sat, Jul 11, 2020 at 8:14 AM Congxian Qiu <[hidden email]> wrote:
|
Re: Possible bug clean up savepoint dump into filesystem and low network IO starting from savepoint
|
|
Hi David, which S3 file system implementation are you using? If I'm not mistaken, then the state backend should try to directly write to the target file system. If this should result in temporary files on your TM, then this might be a problem of the file system implementation. Having access to the logs could also help to better understand whats going on. Cheers, Till On Tue, Jul 14, 2020 at 11:57 AM David Magalhães <[hidden email]> wrote:
|
Re: Possible bug clean up savepoint dump into filesystem and low network IO starting from savepoint
|
|
Hi Till, I'm using s3:// schema, but not sure what was the default used if s3a or s3p. then the state backend should try to directly write to the target file system That was the behaviour that I saw the second time I've run this with more slots. Does the savepoint write directly to S3 via streaming or write the savepoint to memory first before sending to S3? Thanks, David On Tue, Jul 21, 2020 at 7:42 AM Till Rohrmann <[hidden email]> wrote:
|
Re: Possible bug clean up savepoint dump into filesystem and low network IO starting from savepoint
|
|
Hi David Sorry for the late reply, seems I missed your previous email. I'm not sure I fully understand here, do the leftover files on s3 filesystem or the local disk of Taskmanager?. Currently, the savepoint data will directly write to output stream of the underlying file(here is s3 file), you can have a look at the code here[1]. Best, Congxian David Magalhães <[hidden email]> 于2020年7月21日周二 下午4:10写道:
|
Re: Possible bug clean up savepoint dump into filesystem and low network IO starting from savepoint
|
|
Hi Congxian, the leftover files were on the local disk of the TaskManager. But looking better into the issue, I think the issue was the "logs". The sink, in this case, was writing one line into the logger (I was writing 8 GB in total), and that makes more sense. So nothing wrong with the Flink/Savepoint behaviour. Thanks, David On Tue, Jul 21, 2020 at 12:37 PM Congxian Qiu <[hidden email]> wrote:
|
Re: Possible bug clean up savepoint dump into filesystem and low network IO starting from savepoint
|
|
Hi David thanks for the confirmation, good to know that. Best, Congxian David Magalhães <[hidden email]> 于2020年7月21日周二 下午11:42写道:
|
«
Return to (DEPRECATED) Apache Flink User Mailing List archive.
|
1 view|%1 views
| Free forum by Nabble | Edit this page |