Performance test Flink vs Storm

Performance test Flink vs Storm

|
Hi, We are testing flink and storm for our streaming pipelines on various features. In terms of Latency,i see the flink comes up short on storm even if more CPU is given to it. Will Explain in detail. Machine. t2.large 4 core 16 gb. is used for Used for flink task manager and storm supervisor node. Kafka Partitions 4 Messages tested: 1million Load : 50k/sec Scenario: Read from Kafka -> Transform (Map to a different JSON format) - > Write to a Kafka topic. Test 1 Storm Parallelism is set as 1. There are four processes. 1 Spout (Read from Kafka) and 3 bolts (Transformation and sink) . Flink. Operator level parallelism not set. Task Parallelism is set as 1. Task slot is 1 per core. Storm was 130 milliseconds faster in 1st record. Storm was 20 seconds faster in 1 millionth record. Test 2 Storm Parallelism is set as 1. There are four processes. 1 Spout (Read from Kafka) and 3 bolts (Transformation and sink) Flink. Operator level parallelism not set. Task Parallelism is set as 4. Task slot is 1 per core. So all cores is used. Storm was 180 milliseconds faster in 1st record. Storm was 25 seconds faster in 1 millionth record. Observations here 1) Increasing Parallelism did not increase the performance in Flink rather it became 50ms to 5s slower. 2) Flink is slower in Reading from Kafka compared to storm. Thats where the bulk of the latency is. for the millionth record its 19-24 seconds slower. 3) Once message is read, flink takes lesser time to transform and write to kafka compared to storm. Other Flink Config jobmanager.heap.size: 1024m taskmanager.memory.process.size: 1568m How do we improve the latency ? Why does latency becomes worse when parallelism is increased and matched to partitions? Thanks, Prasanna. |
Re: Performance test Flink vs Storm
|
|
Xintong Song,
Between i did some latest test only on t2.medium machine with 2 slots per core. 1million records with 10k/s ingestion rate. Parallelism was 1. I added rebalance to the inputstream. ex: inputStream.rebalance().map() I was able to get latency in the range 130ms - 2sec. Let me also know if there are more things to consider here. Thanks Prasanna. On Thu, Jul 16, 2020 at 4:04 PM Xintong Song <[hidden email]> wrote:
|
Re: Performance test Flink vs Storm
|
|
I had set Checkpoint to use the Job manager backend. Jobmanager backend also runs in JVM heap space and does not use managed memory. Setting managed memory fraction to 0 will give you larger JVM heap space, thus lesser GC pressure. Thank you~ Xintong Song On Thu, Jul 16, 2020 at 10:38 PM Prasanna kumar <[hidden email]> wrote:
|
Re: Performance test Flink vs Storm
|
|
Hi, After making the task.managed. Memory. fraction as 0 , i see that JVM heap memory increased from 512 mb to 1 GB. Earlier I was getting a maximum of 4-6k per second throughput on Kafka source for ingestion rate of 12k+/second. Now I see that improved to 11k per task(parallelism of 1) and 16.5k+ second when run with parallelism of 2. (8.25k per task).. The maximum memory used during the run was 500 mb of heap space. From this exercise , I understand that increasing JVM memory would directly support/increase throughout. Am i correct? Our goal is to test for 100k ingestion per second and try to calculate cost for 1 million per second ( hope it's linear relation) I also saw the CPU utilisation peaked to 50% during the same. 1) Let me know what you think of the same, as I would continue to test. 2) Is there a benchmark for number of records handled per Kafka connector task for a particular JVM heap number. Thanks, Prasanna On Fri 17 Jul, 2020, 06:18 Xintong Song, <[hidden email]> wrote:
|
Re: Performance test Flink vs Storm
|
|
From this exercise , I understand that increasing JVM memory would directly support/increase throughout. Am i correct? It depends. Smaller heap space means more frequent GCs, which occupies the cpu processing time and also introduces more pauses to your program. If you already have large enough heap space, then you can hardly benefit from further increasing it. I'm not aware of any benchmark for Kafka connectors. You can check flink-benchmarks[1], and maybe fork the repository and develop your own Kafka connector benchmark based on it. Thank you~ Xintong Song On Fri, Jul 17, 2020 at 10:54 AM Prasanna kumar <[hidden email]> wrote:
|
|
|
Hi Prasanna, From my experience, there is a ton of stuff which can slow down even a simple pipeline heavily. One thing directly coming to my mind: "object reuse" is not enabled. Even if you have a very simple pipeline with just 2 map steps or so, this can lead to a ton of unneceesary deep copies and GC activities. For a benchmark/idea of performance on a cloud vm setup, I would probably start off with the highest level API of Flink to work on, i.e. Flink SQL CLI. The most automatic optimizations can be expected from this. Having that, you know you can tweak your manually programmed pipeline to be at least as fast as that. You probably also want to share the code of your POC so that others can check whether there are other potential problems. Best regards Theo Von: "Xintong Song" <[hidden email]> An: "Prasanna kumar" <[hidden email]> CC: "user" <[hidden email]> Gesendet: Freitag, 17. Juli 2020 05:41:23 Betreff: Re: Performance test Flink vs Storm From this exercise , I understand that increasing JVM memory would directly support/increase throughout. Am i correct? It depends. Smaller heap space means more frequent GCs, which occupies the cpu processing time and also introduces more pauses to your program. If you already have large enough heap space, then you can hardly benefit from further increasing it. I'm not aware of any benchmark for Kafka connectors. You can check flink-benchmarks[1], and maybe fork the repository and develop your own Kafka connector benchmark based on it. Thank you~ Xintong Song On Fri, Jul 17, 2020 at 10:54 AM Prasanna kumar <[hidden email]> wrote:
|
Re: Performance test Flink vs Storm
|
|
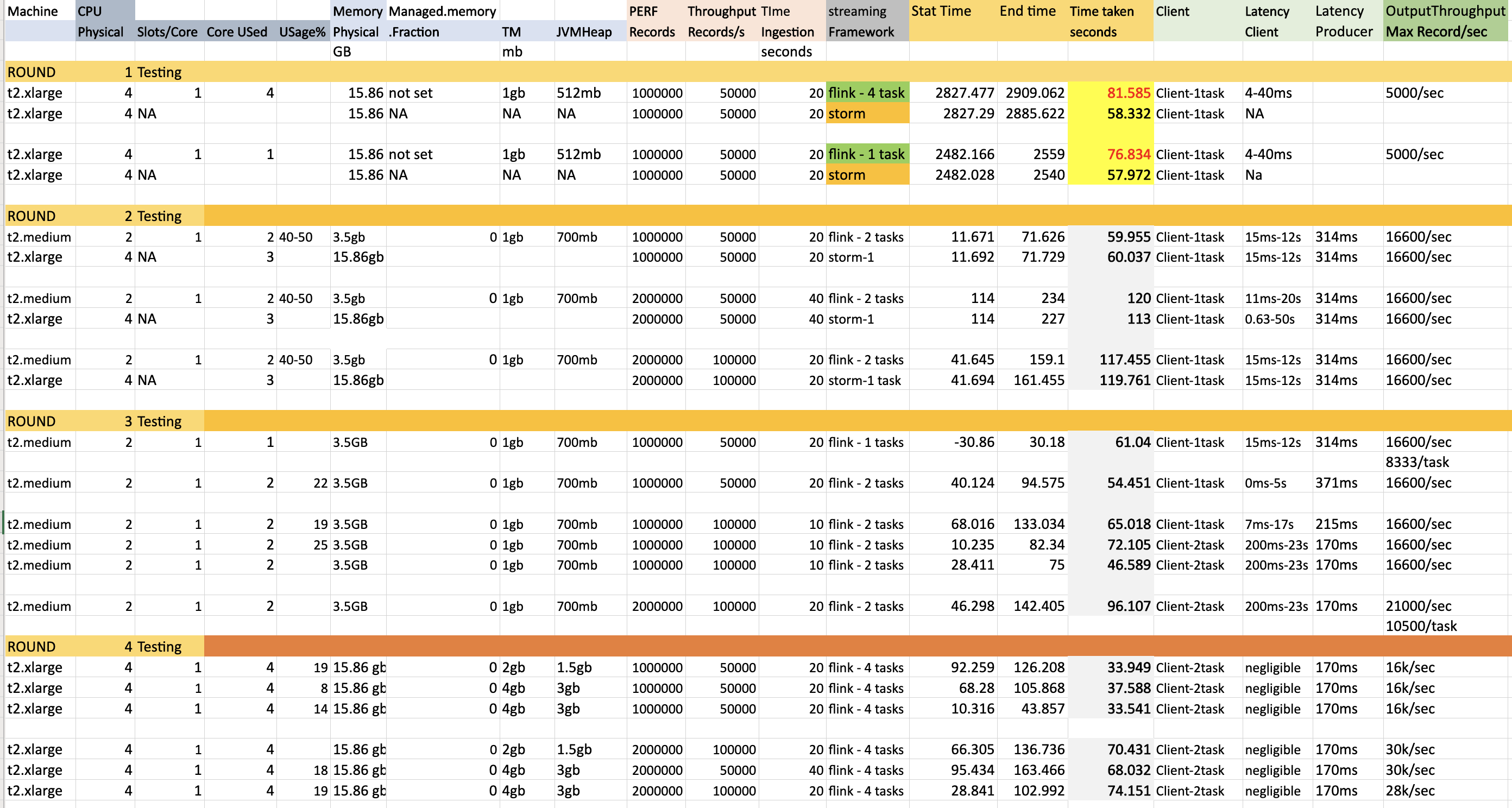
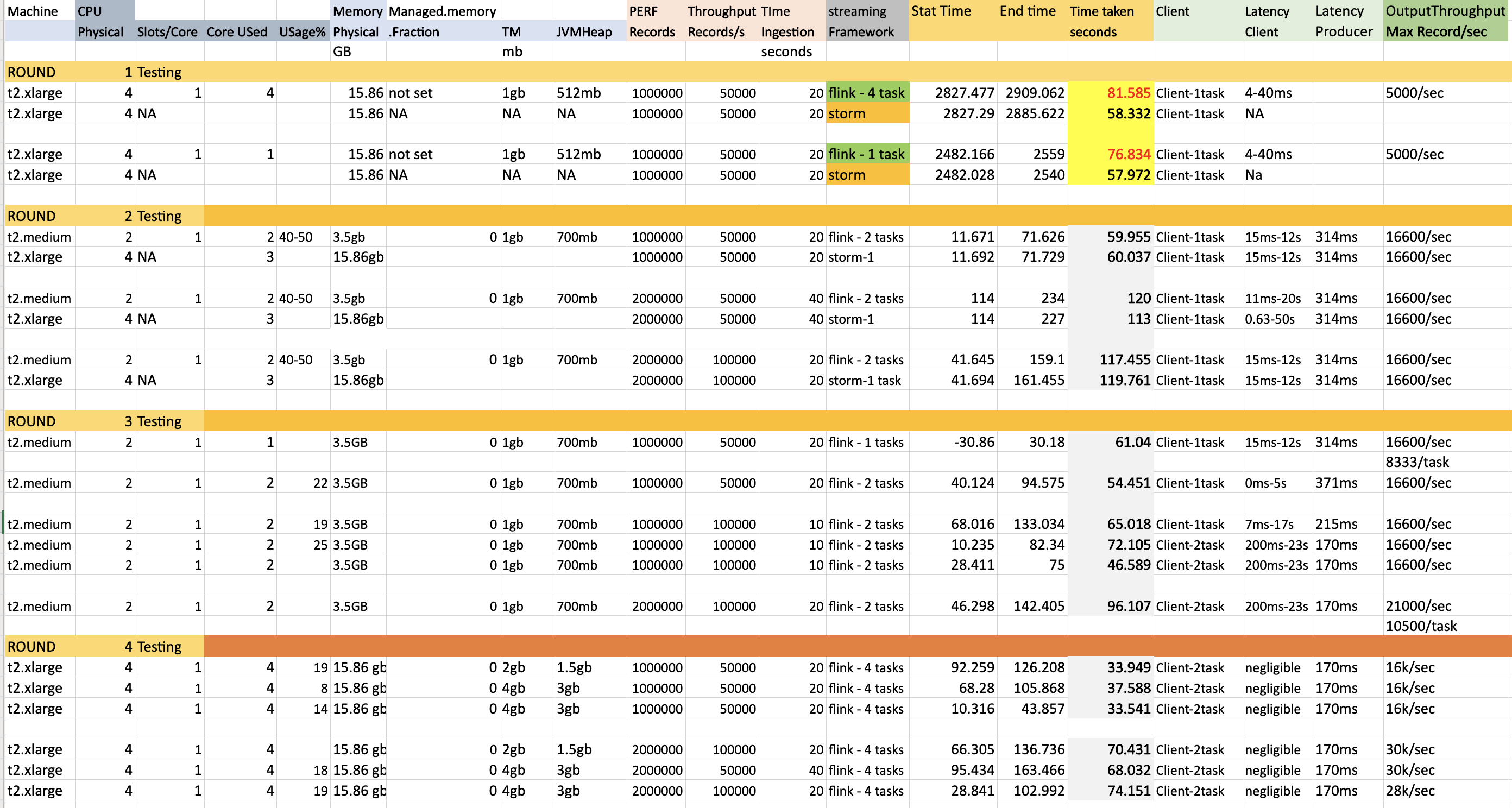
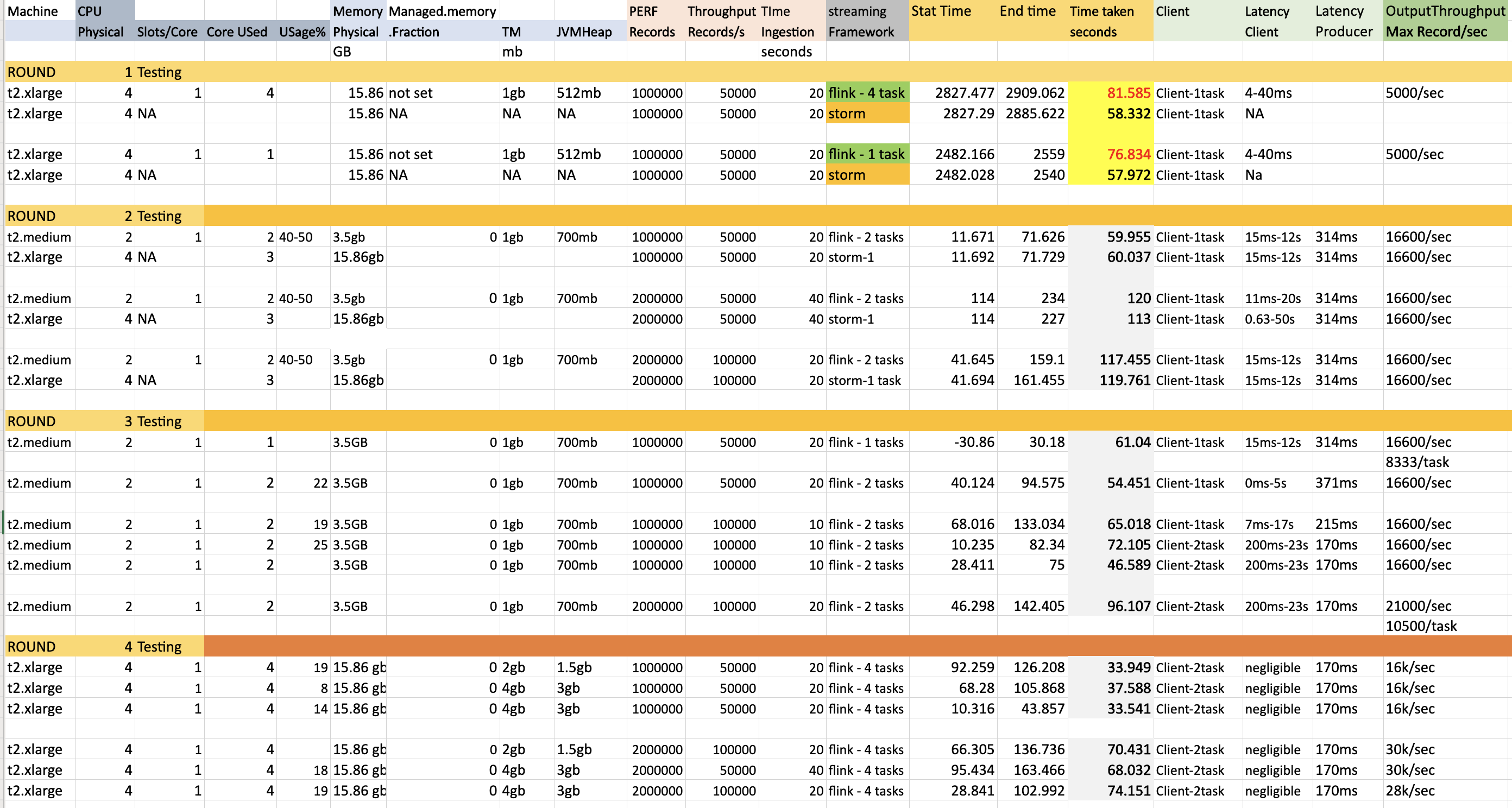
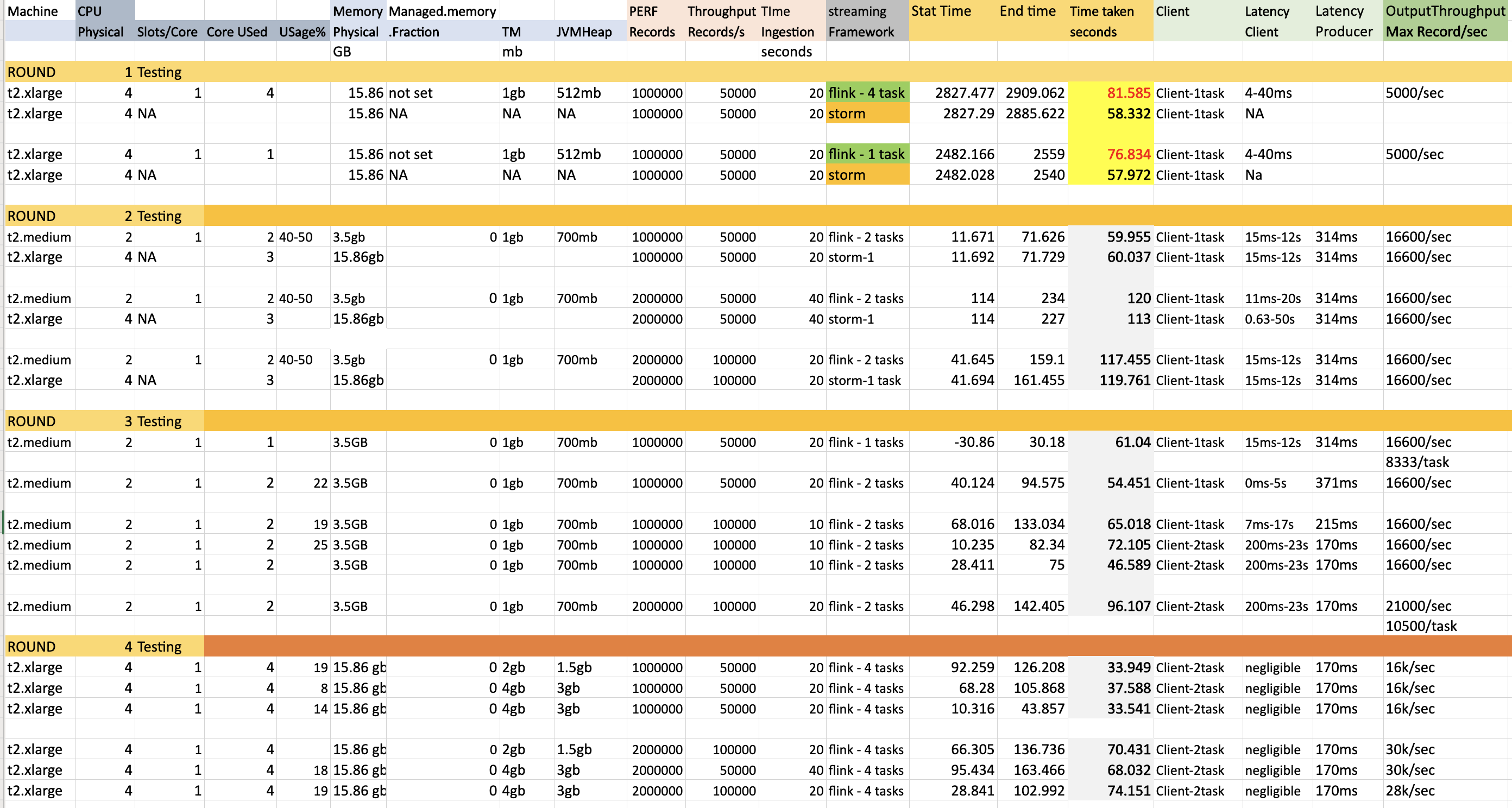
Thanks for various suggestions. Object Reuse is False and Execution mode is Pipeline. I have done 4 rounds of testing. Used following kafka performance script to ingest records to topic having 4 partitions. bin/kafka-producer-perf-test.sh --topic inputtopic --num-records 2000000 --throughput 50000 --producer.config config/sasl.properties --payload-file /home/ubuntu/kafka_2.12-2.5.0/eventLoad.json --producer-props bootstrap.servers=kafka.amazonaws.com:9092 buffer.memory=67108864 compression.type=gzip buffer.memory=6710886456 batch.size=3000000 request.timeout.ms=600000 linger.ms=1000 Round 1 testing Initially flink could not match latency performance of storm ( Same machine ). Round 2 testing Changes made: Added rebalance while reading from kafka and set managed.memory.fraction to 0 Here i ran flink job in t2.medium machine compared to storm t2.large machine and still achieved similar/better latency. (Column Time taken seconds). Here still flink was using 1 core less than storm. Round 3 testing This is similar to the Round2 testing but only with flink and i see that the performance is consistent. But we see when the input ingestion rate is 50/100k per second , the maximum output throughput (to kafka) is only 16.6k/sec or 8.3kper task . Only once the max output throughput came to 21k/sec but still way less than the input throughput of 100k. Round 4 testing To get better max output throughput, here i tested with larger machine 4 Core 15gb machine t2.large. I tested with both Task manager process memory of 2 ang 4 gb resulting in 1.5 and 3gb for heap respectively. But the throughput increased partially to 30k/sec but but still way less than the input throughput of 100k. Few Observations and questions. 1) I see that TM memory of 3gb itself gives the peak performance of (16-30)k/s o.p for. (50-100)k/s. Increasing memory post this doesnot alter performance. 2) The pipeline takes time to get to the maximum throughput from 100->1000->5000->peak performance. By the time it reaches i see that pipeline could not match the ingestion rate. What needs to be done here so that it shoots to peak performance faster. 3) I see maximum CPU usage is only 20-25% even when all slots are used. So Is it better to have 2 slots per core rather than 1 slot per core. Apart from this what other improvements could be done to improve the same. I have attached both the metrics and code. Code is simple and straightforward. Transform is very lightweight. 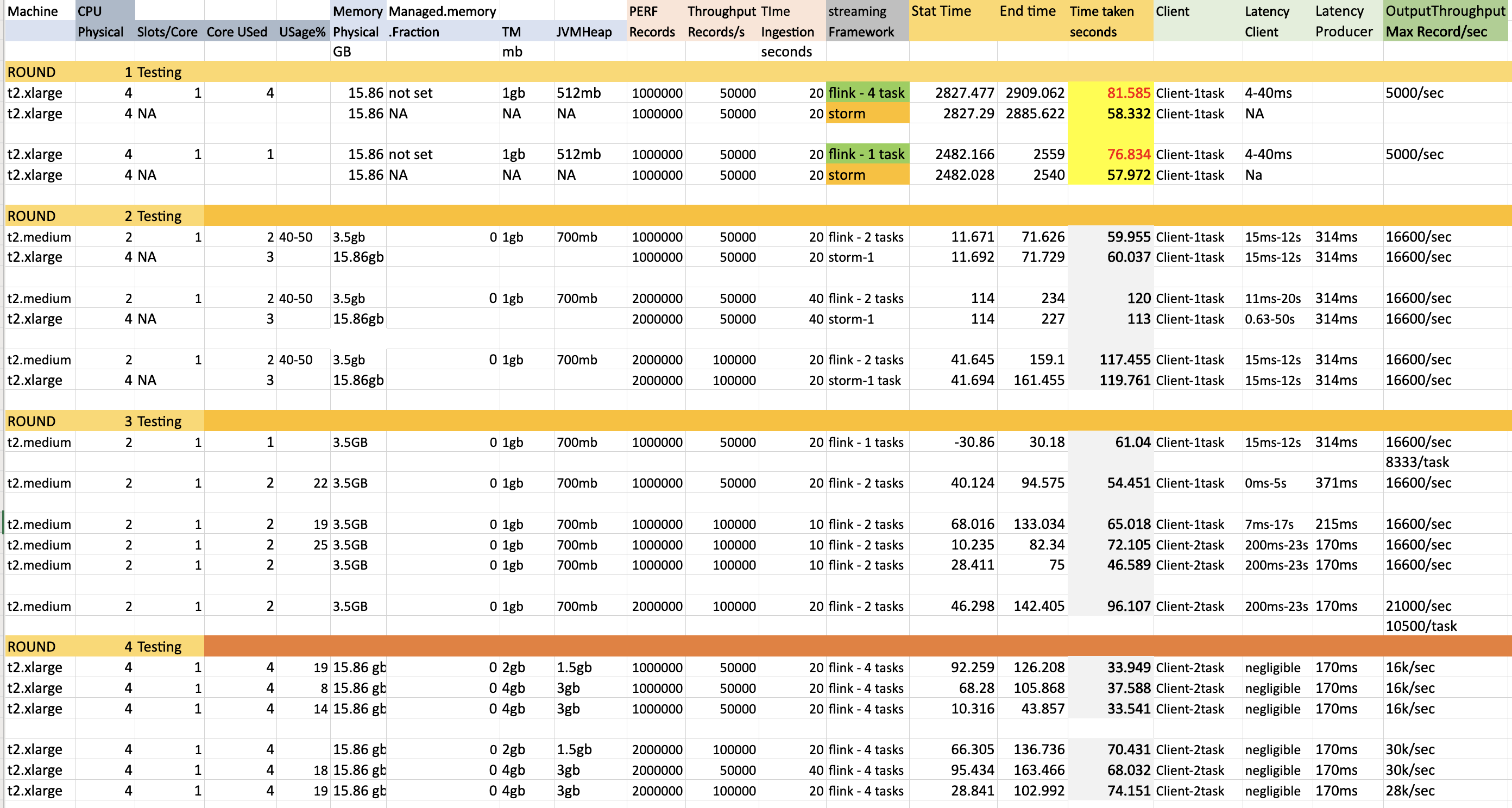 Code FlinkKafkaConsumer011 fkC = new FlinkKafkaConsumer011<>(TOPIC_IN, public class EventKeyedSerializationSchema implements KeyedSerializationSchema<EventMessage> { Prasanna. On Fri, Jul 17, 2020 at 2:52 PM Theo Diefenthal <[hidden email]> wrote:
|
Re: Performance test Flink vs Storm
|
|
What's the purpose of the rebalance? That's quite expensive and seems unnecessary. env.setBufferTimeout(timeoutMillis); The default timeout is 100 msec. You should find that setting it to 1 msec will provide most of the benefit of setting it to 0, while doing less damage to the throughput. And if you are serious about reducing latency, turn on object reuse. ExecutionConfig.enableObjectReuse(); They're not relevant for this job, but checkpointing, and the auto-watermarking interval can also play a role in increasing latency. Another frequent cause of excessive latency is inefficient serialization. But I assume you are using the same serializers with Storm, so even if there's room for improvement, perhaps it's irrelevant. David On Sat, Jul 18, 2020 at 7:43 PM Prasanna kumar <[hidden email]> wrote:
|
Re: Performance test Flink vs Storm
|
|
Please look at Lightbend cloudflow which covers both flink and spark in same pipeline and has vendor support for production issues. Lightbend has good enterprise support. Thanks Sri On Sat, 18 Jul 2020 at 14:06, David Anderson <[hidden email]> wrote:
Thanks & Regards
Sri Tummala |
Re: Performance test Flink vs Storm
|
|
In reply to this post by David Anderson-3
David, Thanks for the various Suggestions. I have tried all the points you have mentioned. I did Not see much difference. Looks like 2gb of task manager memory is more than enough for our use case. When i scaled horizontally , i was able to get better performance. Its about IOPS rather than CPU/Memory. More machines (even though smaller in config) has improved the performance tremendously. It required 3 t2.xlarge machine (12 core in total) to get a latency of 0-2 sec for a 50k/s throughput. Planning to test with machines having IOPS capacity to get for 100k/s. Prasanna. On Sun, Jul 19, 2020 at 2:35 AM David Anderson <[hidden email]> wrote:
|
|
|
Hey Prasanna, you mention that most of the latency is lost in the Flink's Kafka consumer. If you want to optimize for low latency, and your Kafka cluster is not overloaded, you could consider reducing Flink's Kafka poll timeout. Here's a description of the timeout: https://kafka.apache.org/0110/javadoc/org/apache/kafka/clients/consumer/KafkaConsumer.html#poll(long) By default, the timeout is 100ms. You can reduce the timeout using this FlinkKafkaConsumer property: Maybe try a value like 5ms (or 0ms, which might kill your throughput).flink.poll-timeout Best, Robert On Tue, Jul 21, 2020 at 7:48 PM Prasanna kumar <[hidden email]> wrote:
|
| Free forum by Nabble | Edit this page |