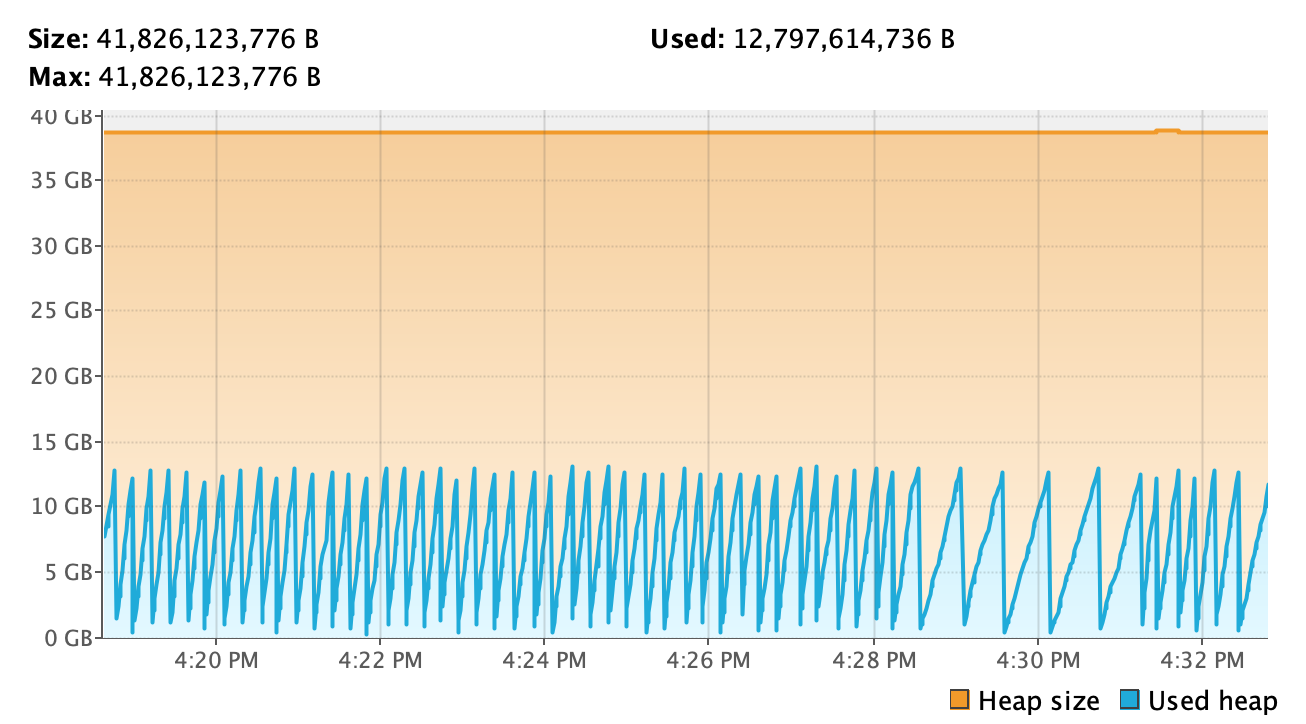
It seems there are only young GCs for short lifecycles objects in your case, because the flink managed memory which reserves in old generation never be used and the network memory is off-heap.
If you want to change the GC to start later and reach the upper bound of the heap memory, you could adjust the GC options, might increase the ratio of eden generation comparing with old generation, also for survivor ratio.
But I do not think you should give so large heap memory for TM, because it seems not give any benefits in your case.
Best,
Zhijiang
------------------------------------------------------------------
Send Time:2019年6月14日(星期五) 22:50
Subject:Optimizing Heap usage for Streaming Jobs
Dear community,
I'm currently debugging my job with flink-1.6.4, which manages big states so that I use rocksdb to host the data. I know that for streaming purpose Flink does not use the managed memory features, but anyway I'm asking then how can I optimize its usage anyway [2]. I reserve to each TM (three TM plus one JM) 40G heap memory.
then I configure each TM with the following:
taskmanager.heap.size: 40960m
taskmanager.memory.fraction: 0.7
taskmanager.memory.preallocate: false
taskmanager.numberOfTaskSlots: 16
which is more or less using the defaults, preallocate and fraction as well.
In the picture, I report the heap usage by profiling the job and it does not look really nice though.
Andrea Spina
Head of R&D @ Radicalbit Srl
Via Giovanni Battista Pirelli 11, 20124, Milano - IT