One Kafka consumer operator subtask sending many more bytes than the others

One Kafka consumer operator subtask sending many more bytes than the others

|
Hi,
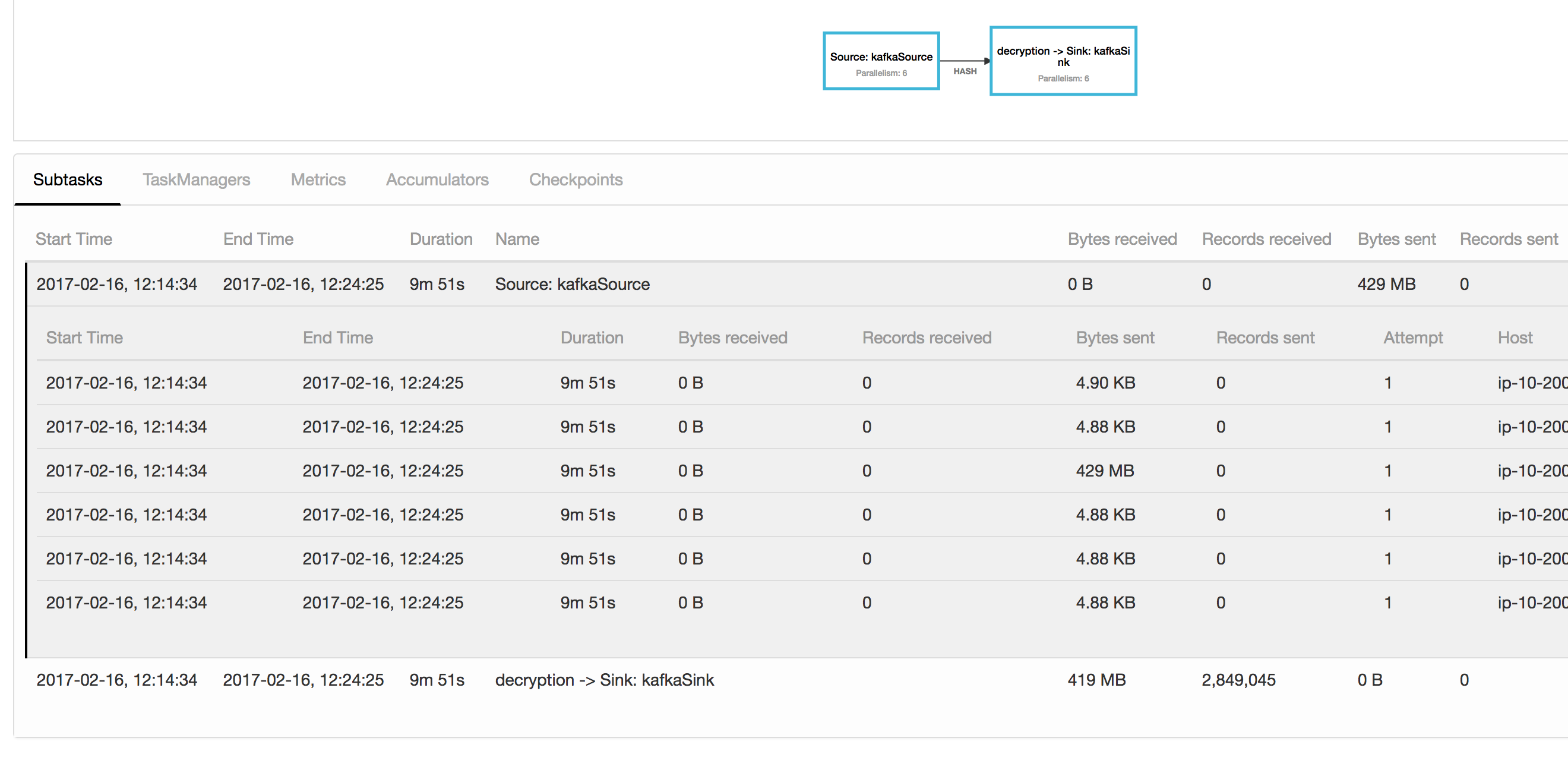
I am trying to understand this issue in one of my Flink jobs with a Kafka source. At the moment I am using parallelism 6. The operator subtask just read the Kafka records (from a topic with 600 partitions), applies a keyBy and sends them to the next operator after the hashing. What I can see is that one of the subtasks is sending much more data than the others. The kafka partitions are well-balanced, as in they roughly contain the same number of records. I attach a screenshot. One subtask has sent 429 MB and the others around 4.88 KB. Could this be related that I originally created this stream with just parallelism one and I increased it later at some point. This is from a performance test suite where I am increasing parallelism between runs to check the performance, in a highly available cluster setup with zookeeper and checkpoints in S3. I am not cancelling the job with savepoints. Any ideas or things I can look for? Thanks! Bruno 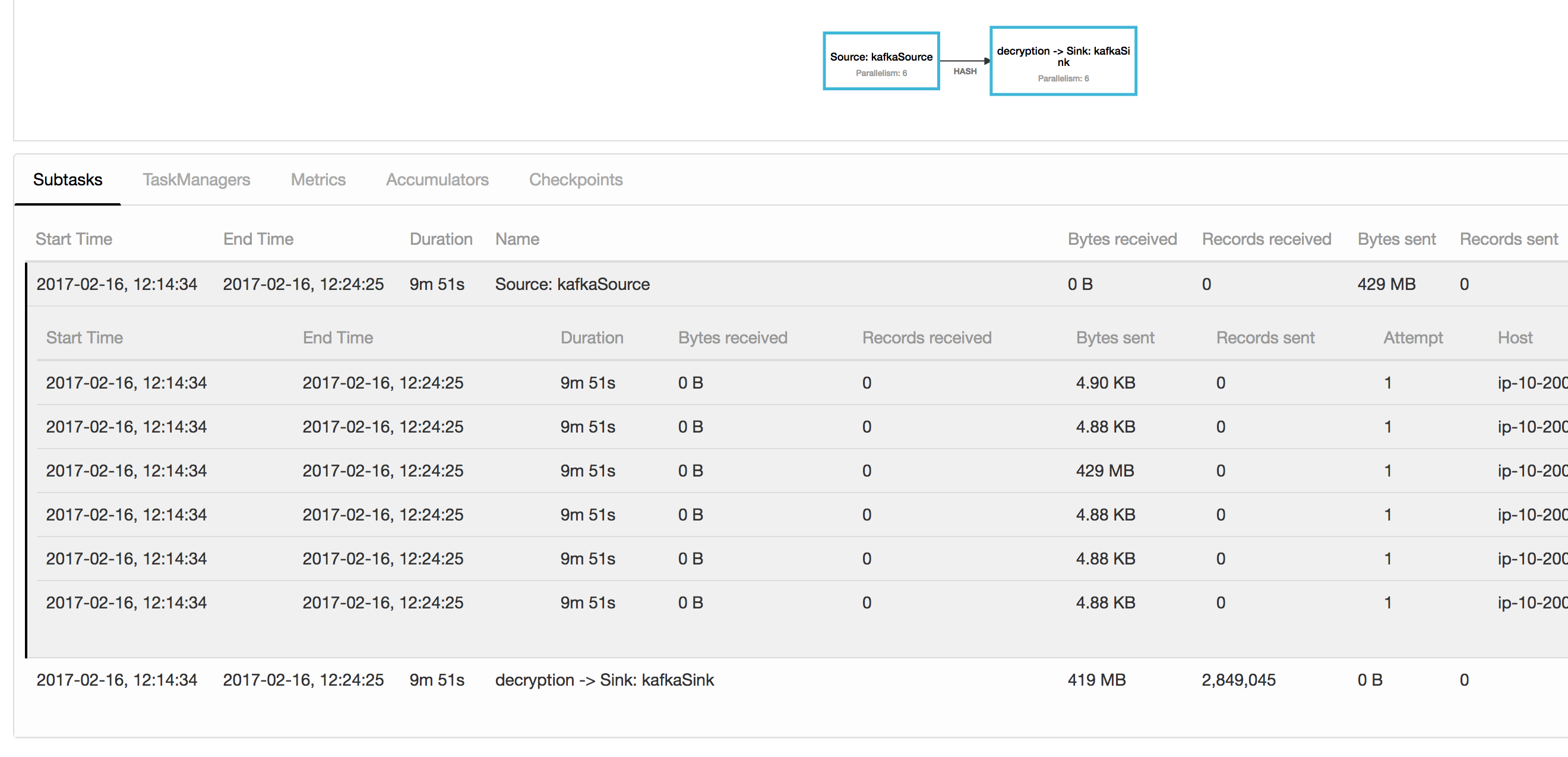 |
Re: One Kafka consumer operator subtask sending many more bytes than the others
|
|
Hi Bruno, do you resume from the savepoints with a changed parallelism? Which version of Flink are you running? Which Kafka version are you using (+ which Kafka consumer version). The partitions should be distributed among all 6 parallel subtasks which means that every subtask should read from 100 partitions. You can check in the logs how many partitions each consumer has been assigned by searching for "Got x partitions from these topics" or "Consumer is going to read the following topics". If you don't see 100 partitions assigned to each consumer, then something is clearly going wrong. Cheers, Till On Thu, Feb 16, 2017 at 1:42 PM, Bruno Aranda <[hidden email]> wrote:
|
|
|
Cool, thanks for your feedback Till. I will investigate the logs and our Kafka installation. So far we use Flink 1.2 with Kafka 0.10.0.0 on AWS. Flink client is 0.10 (with underlying java client 0.10.0.0). Will have a look at the logs and try different things with Kafka today (ie upgrade it, configure the availability zones, etc), to see if I can pinpoint the issue. Thanks! Bruno On Fri, 17 Feb 2017 at 09:44 Till Rohrmann <[hidden email]> wrote:
|
|
|
Hi there! Just coming back to say we have identified what our issue was. Basically we have two jobs, one that puts data to Kafka and another one that will read from it. It seems we forgot to add a partitioner for the first Job and it was using the default FixedPartitioner and putting everything in as many partitions as parallelism for that first job. On another note, looking for the logs "Consumer is going to read the following topics" and such didn't help much, since it looks like they just get the metadata for the topic and returns all the partitions every call, at least for the FlinkKafkaConsumer 0.9/0.10. Cheers! Bruno On Fri, 17 Feb 2017 at 09:56 Bruno Aranda <[hidden email]> wrote:
|
Re: One Kafka consumer operator subtask sending many more bytes than the others
|
|
Hi Bruno, you're absolutely right. We don't log which partitions where assigned to the consumer. Maybe we should add this. Thanks for the pointer. Cheers, Till On Fri, Feb 17, 2017 at 7:02 PM, Bruno Aranda <[hidden email]> wrote:
|
Re: One Kafka consumer operator subtask sending many more bytes than the others
|
|
+1 to adding logs for which partition were assigned to each consumer subtask. FYI - I’ve included adding these logs in this PR: https://github.com/apache/flink/pull/3378. The PR was fixing another issue irrelevant to this thread, but since it was touching parts related to partition assigning, I added the logs while passing that part of the code. On February 20, 2017 at 10:29:08 PM, Till Rohrmann ([hidden email]) wrote:
|
«
Return to (DEPRECATED) Apache Flink User Mailing List archive.
|
1 view|%1 views
| Free forum by Nabble | Edit this page |