Non-heap memory usage jumped after 1.7 -> 1.10 upgrade


|
This is a stateful stream join application using RocksDB state backend with incremental checkpoint enabled.
Is there any default config change for rocksdb state backend btw 1.7 and 1.10 due to FLIP-49? or maybe there are some implications of the FLIP-49 change that we don't understand? I can confirm both 1.7.2 and 1.10.0 jobs have the same state size via various metrics
1.7.2 job setup
1.10.0 job setup
I tried different combinations of "taskmanager.memory.jvm-overhead.max" and "taskmanager.memory.managed.size". They all lead to similar result. 1.7.2 job memory usagefree output vmstat output top output 1.10.0 job memory usagefree output vmstat output top output |






|
|
I tried this combination for extended time (> 12 hours).
It eventually led to job restart loop due to container terminations. One terminated container has this warning 2020-04-11 03:45:57,405 WARN org.apache.flink.streaming.runtime.tasks.StreamTask - Error while canceling task.
org.apache.flink.util.FlinkRuntimeException: Error while removing entry from RocksDB
at org.apache.flink.contrib.streaming.state.AbstractRocksDBState.clear(AbstractRocksDBState.java:113)
at org.apache.flink.contrib.streaming.state.RocksDBValueState.update(RocksDBValueState.java:99)
at com.foo.bar.function.CoprocessImpressionsPlays.onTimer(CoprocessImpressionsPlays.scala:161)
at org.apache.flink.streaming.api.operators.co.LegacyKeyedCoProcessOperator.onEventTime(LegacyKeyedCoProcessOperator.java:98)
at org.apache.flink.streaming.api.operators.InternalTimerServiceImpl.advanceWatermark(InternalTimerServiceImpl.java:276)
at org.apache.flink.streaming.api.operators.InternalTimeServiceManager.advanceWatermark(InternalTimeServiceManager.java:128)
at org.apache.flink.streaming.api.operators.AbstractStreamOperator.processWatermark(AbstractStreamOperator.java:787)
at org.apache.flink.streaming.api.operators.AbstractStreamOperator.processWatermark1(AbstractStreamOperator.java:805)
at org.apache.flink.streaming.runtime.io.StreamTwoInputProcessor$StreamTaskNetworkOutput.emitWatermark(StreamTwoInputProcessor.java:371)
at org.apache.flink.streaming.runtime.streamstatus.StatusWatermarkValve.findAndOutputNewMinWatermarkAcrossAlignedChannels(StatusWatermarkValve.java:179)
at org.apache.flink.streaming.runtime.streamstatus.StatusWatermarkValve.inputWatermark(StatusWatermarkValve.java:101)
at org.apache.flink.streaming.runtime.io.StreamTaskNetworkInput.processElement(StreamTaskNetworkInput.java:153)
at org.apache.flink.streaming.runtime.io.StreamTaskNetworkInput.emitNext(StreamTaskNetworkInput.java:128)
at org.apache.flink.streaming.runtime.io.StreamTwoInputProcessor.processInput(StreamTwoInputProcessor.java:182)
at org.apache.flink.streaming.runtime.tasks.StreamTask.processInput(StreamTask.java:311)
at org.apache.flink.streaming.runtime.tasks.mailbox.MailboxProcessor.runMailboxLoop(MailboxProcessor.java:187)
at org.apache.flink.streaming.runtime.tasks.StreamTask.runMailboxLoop(StreamTask.java:487)
at org.apache.flink.streaming.runtime.tasks.StreamTask.invoke(StreamTask.java:470)
at org.apache.flink.runtime.taskmanager.Task.doRun(Task.java:707)
at org.apache.flink.runtime.taskmanager.Task.run(Task.java:532)
at java.lang.Thread.run(Thread.java:748)
Caused by: org.rocksdb.RocksDBException: While open a file for appending: /tmp/flink-io-b3fb05c6-6412-4ed2-addf-1271351526ec/job_60f02c1f97bee9f7d6c82c96c1ddd12a_op_LegacyKeyedCoProcessOperator_b68dc018046f1b94f31128067b2e3230__1147_1440__uuid_44478c30-acc1-4cda-88c8-c0fd36eed589/db/005385.sst: No such file or directory
at org.rocksdb.RocksDB.delete(Native Method)
at org.rocksdb.RocksDB.delete(RocksDB.java:1186)
at org.apache.flink.contrib.streaming.state.AbstractRocksDBState.clear(AbstractRocksDBState.java:111)
... 20 more Also observed "rocksdb.is-write-stopped" metric showing up 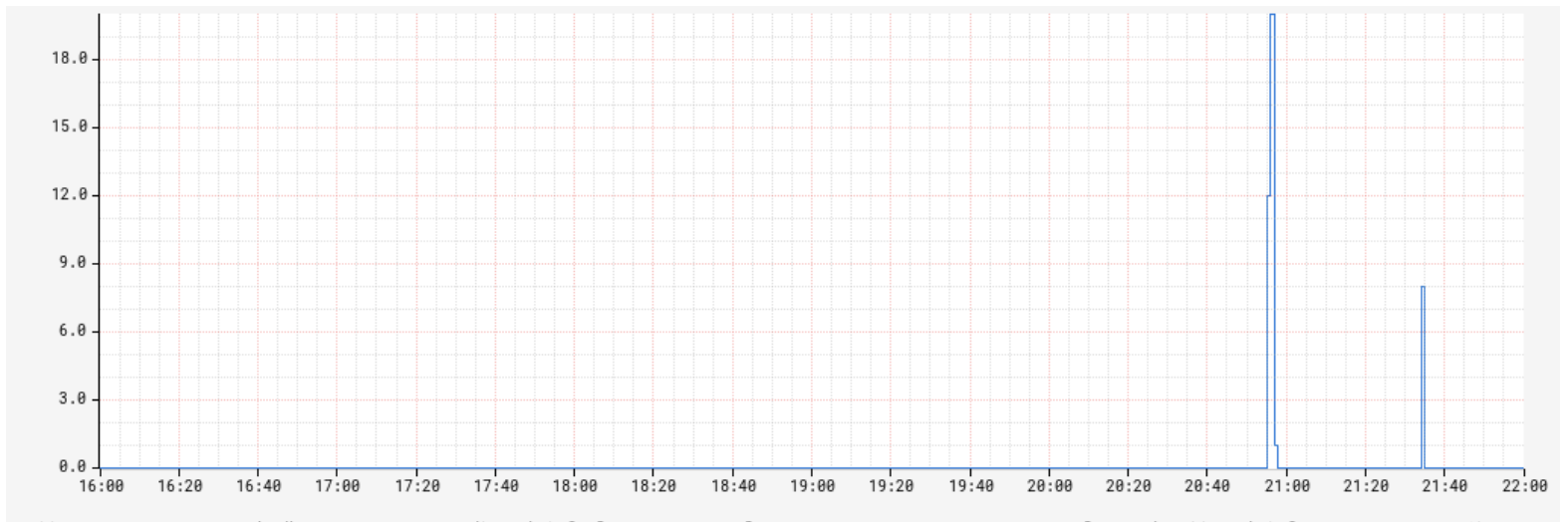 On Sun, Apr 12, 2020 at 3:07 PM Steven Wu <[hidden email]> wrote:
|
Re: Non-heap memory usage jumped after 1.7 -> 1.10 upgrade
|
|
Hi Steven, There's one new feature, RocksDB memory control, that might related to your case. Before Flink 1.10, RocksDB will decide its memory usage without being aware of how many memory Flink has reserved for it. That means for your 1.7.2 setup, despite around 100GB memory is available to RocksDB (128GB in total, minus 20GB heap, 6GB direct and a few JVM native memory overhead), it may use far less than that. In Flink 1.10, RocksDB will try to use as many memory as the configured Flink managed memory size. That means it will try to take all the memory available to it, allocate all the memory buffers even if there's not yet that much data to store. If you want to disable that feature and go back to the old behavior, you can configure 'state.backend.rocksdb.memory.managed' to 'false'. Thank you~ Xintong Song On Mon, Apr 13, 2020 at 8:56 AM Steven Wu <[hidden email]> wrote:
|
| Free forum by Nabble | Edit this page |