Need help regarding Flink Batch Application

Need help regarding Flink Batch Application

|
Hi Everybody,
Currently I am working on a project where i need to write a Flink Batch Application which has to process hourly data around 400GB of compressed sequence file. After processing, it has write it as compressed parquet format in S3. I have managed to write the application in Flink and able to run successfully process the whole hour data and write in Parquet format in S3. But the problem is this that it is not able to meet the performance of the existing application which is written using Spark Batch(running in production). Current Spark Batch Cluster size - Aws EMR - 1 Master + 100 worker node of m4.4xlarge ( 16vCpu, 64GB RAM), each instance with 160GB disk volume Input data - Around 400GB Time Taken to process - Around 36 mins ------------------------------------------------------------ Flink Batch Cluster size - Aws EMR - 1 Master + 100 worker node of r4.4xlarge ( 16vCpu, 64GB RAM), each instance with 630GB disk volume Transient Job - flink run -m yarn-cluster -yn 792 -ys 2 -ytm 14000 -yjm 114736 Input data - Around 400GB Time Taken to process - Around 1 hour I have given all the node memory to jobmanager just to make sure that there is a dedicated node for jobmanager so that it doesn't face any issue related to resources. We are already running Flink Batch job with double RAM compare to Spark Batch however we are not able get the same performance. Kindly suggest on this to achieve the same performance as we are getting from Spark Batch Thanks, Ravi |
Re: Need help regarding Flink Batch Application
|
|
What have you tried so far to increase
performance? (Did you try different combinations of -yn and -ys?)
Can you provide us with your application? What source/sink are you using? On 08.08.2018 07:59, Ravi Bhushan Ratnakar wrote:
|
Re: Need help regarding Flink Batch Application
|
|
The code or the execution plan (ExecutionEnvironment.getExecutionPlan()) of the job would be interesting. 2018-08-08 10:26 GMT+02:00 Chesnay Schepler <[hidden email]>:
|
Re: Need help regarding Flink Batch Application
|
|
Hi Fabina/Chesnay,
Thanks for your quick response. We are using EMR 5.16 which has Flink 1.5.0 Source and Sink are S3(using flink-s3-fs-hadoop module). Parallelism is 1584. I have played around with different values for -yn and -ys and but didn't perform well, the above given configuration is so far the best performance. I am not able to get the execution plan in json. I have added the image from flink ui. while creating the cluster on aws emr, we are using below configuration [{"classification":"hdfs-site","properties":{"dfs.webhdfs.enabled":"True"}},{"classification":"yarn-site","properties":{"yarn.log-aggregation.retain-seconds":"345600","yarn.nodemanager.resource.memory-mb":"116736","yarn.app.mapreduce.am.resource.mb":"2048"}},{"classification":"flink-conf","properties":{"mode":"legacy","akka.lookup.timeout":"120 s","taskmanager.memory.fraction":"0.85","akka.ask.timeout":"120 s","env.java.opts.taskmanager":"-XX:+UseG1GC","akka.startup-timeout":"120 s","akka.client.timeout":"120 s"}}] 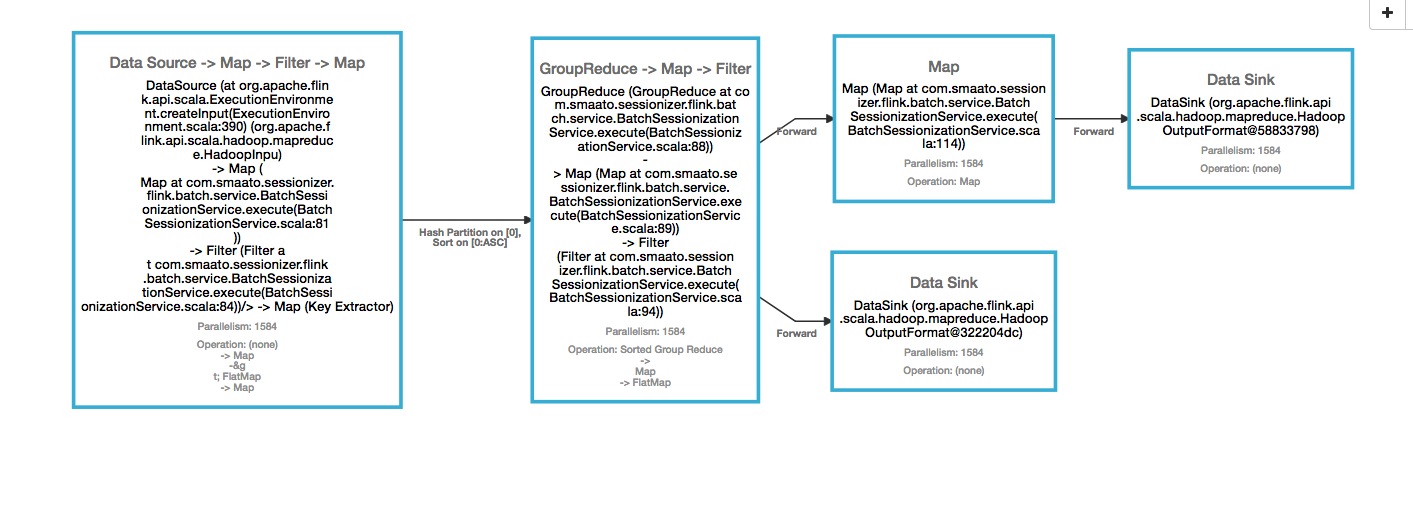 Thanks, Ravi On Wed, Aug 8, 2018 at 11:24 AM, Fabian Hueske <[hidden email]> wrote:
|
Re: Need help regarding Flink Batch Application
|
|
Hi Ravi on the source stream can you add the ".rebalanc()" method and re reun the job. Give us the job timing later. I'm sure this will cause a huge performance impact On Wed 8 Aug, 2018, 5:59 PM Ravi Bhushan Ratnakar, <[hidden email]> wrote:
|
«
Return to (DEPRECATED) Apache Flink User Mailing List archive.
|
1 view|%1 views
| Free forum by Nabble | Edit this page |