|
|
For the poor soul that stumbles upon this in the future, just increase your JM resources.
I thought for sure this must have been the TM experiencing some sort of backpressure. I tried everything from enabling universal compaction to unaligned checkpoints to profiling the TM. It wasn't until I enabled AWS debug logs that I noticed the JM will make a lot of DELETE requests to AWS after a successful checkpoint. If the checkpoint interval is short and the JM resources limited, then I believe the checkpoint barrier will be delayed causing long start delays. The JM is too busy making AWS requests to inject the barrier. After I increased the JM resources, the long start delays disappeared. Hello,
I have an application that reads from two Kafka sources, joins them, and produces to a Kafka sink. The application is experiencing long end to end checkpoint durations for the Kafka source operators. I'm hoping I could get some direction in how to debug this further.
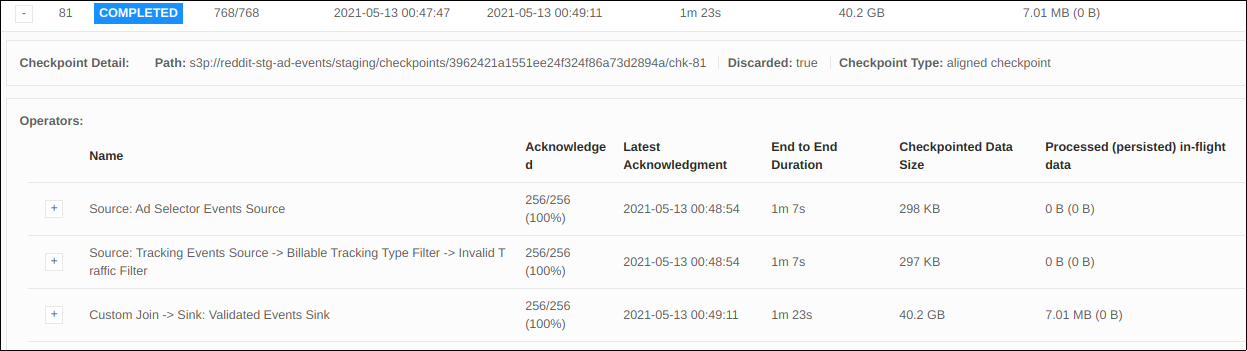
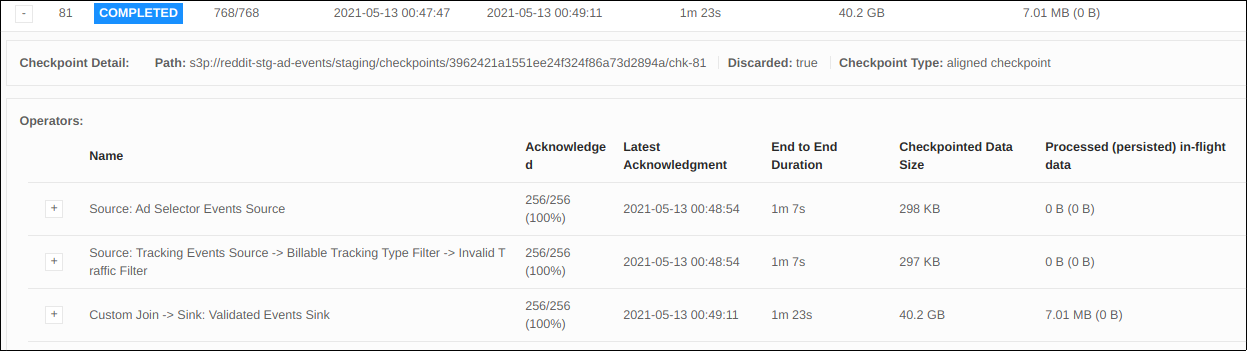
Here is a UI screenshot of a checkpoint instance:
My goal is to bring the total checkpoint duration to sub-minute.
Here are some observations I made: - Each source operator task has an E2E checkpoint duration of 1m 7s
- Each source operator task has sub 100ms sync, async, aligned buffered, and start delay
- Each join operator task has a start delay of 1m 7s
- There is no backpressure in any operator
These observations are leading me to believe that the source operator is taking a long amount of time to checkpoint. I find this a bit strange as the fushioned operator is fairly light. It deserializes the event, assigns a watermark, and might perform two filters. In addition, it's odd that both source operators have tasks with all the same E2E checkpoint duration.
Is there some sort of locking that's occurring on the source operators that can explain these long E2E durations?
Best, Hubert
|