Latency metrics is not aligned with other metrics like max

Latency metrics is not aligned with other metrics like max

|
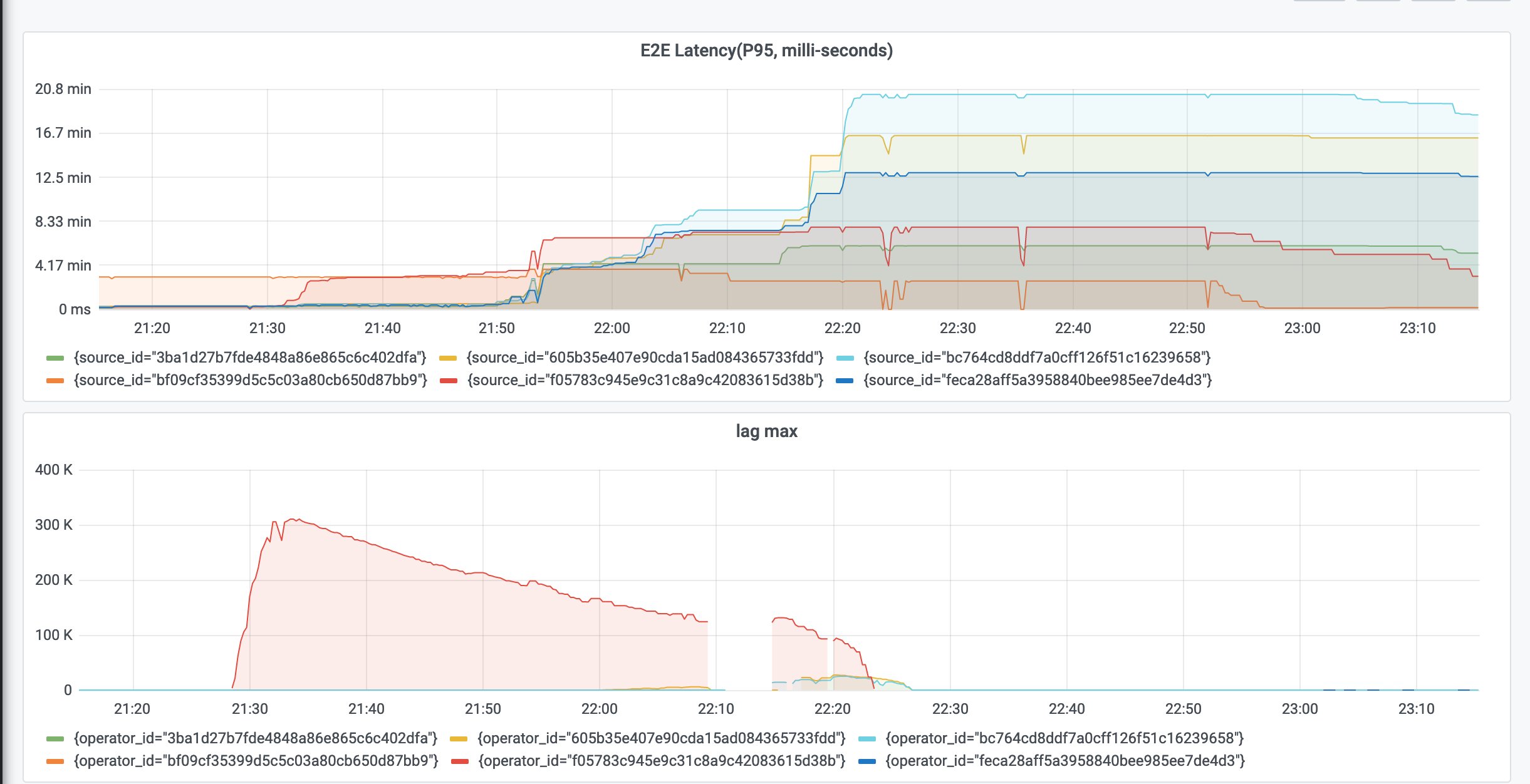

Re: Latency metrics is not aligned with other metrics like max
|
|
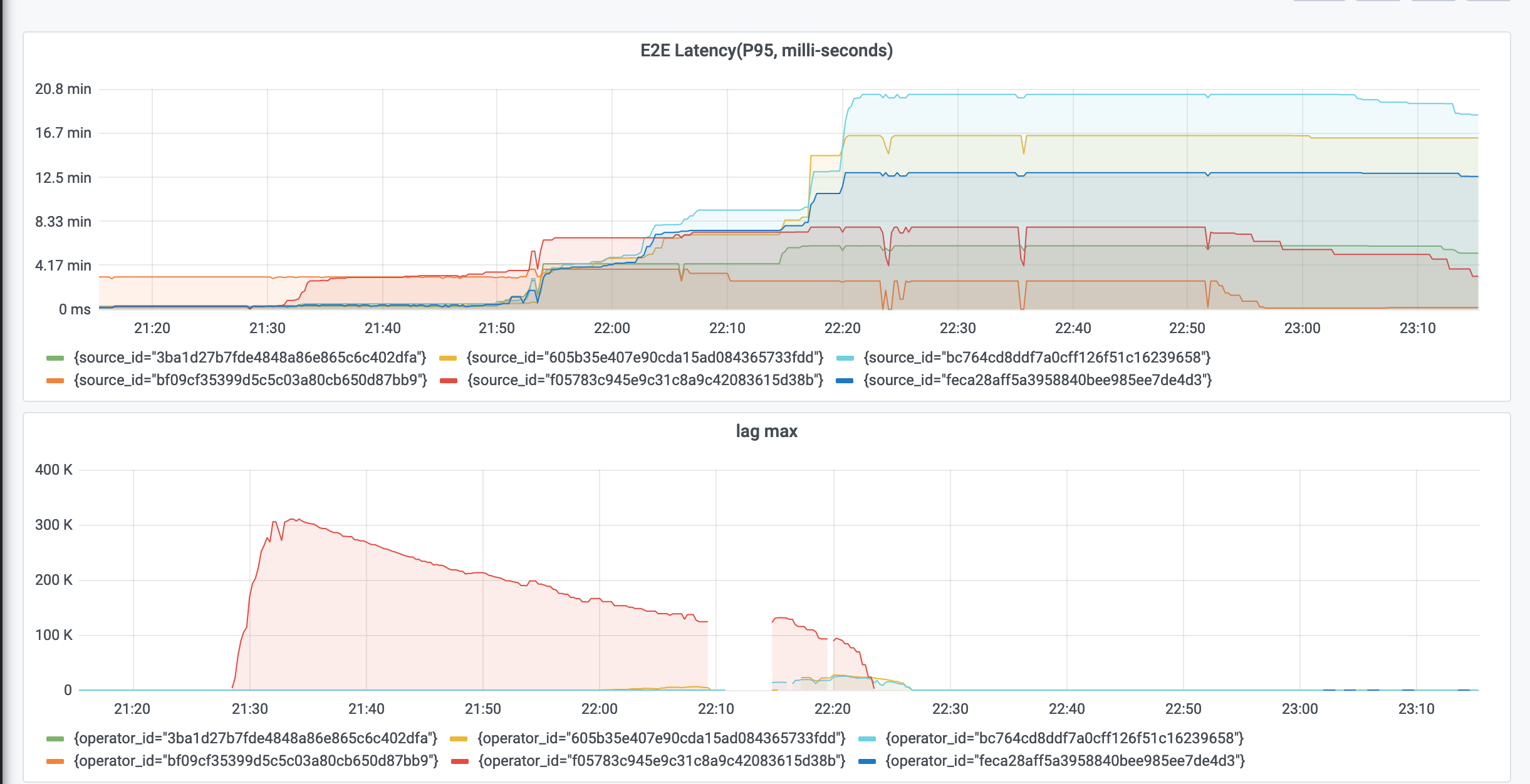

Re: Latency metrics is not aligned with other metrics like max
|
|
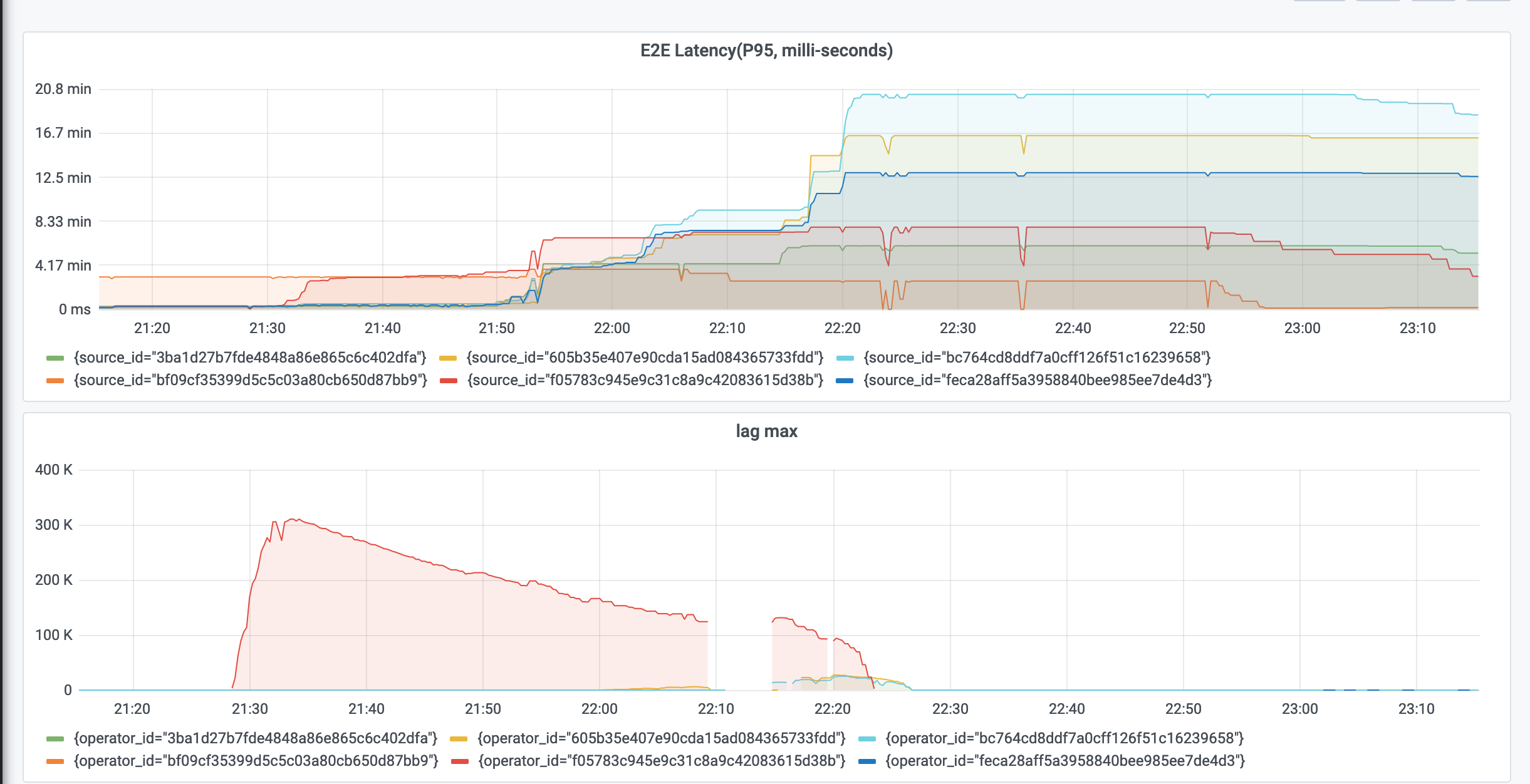

Re: Latency metrics is not aligned with other metrics like max
|
|

| Free forum by Nabble | Edit this page |