Kafka and Flink's partitions


|
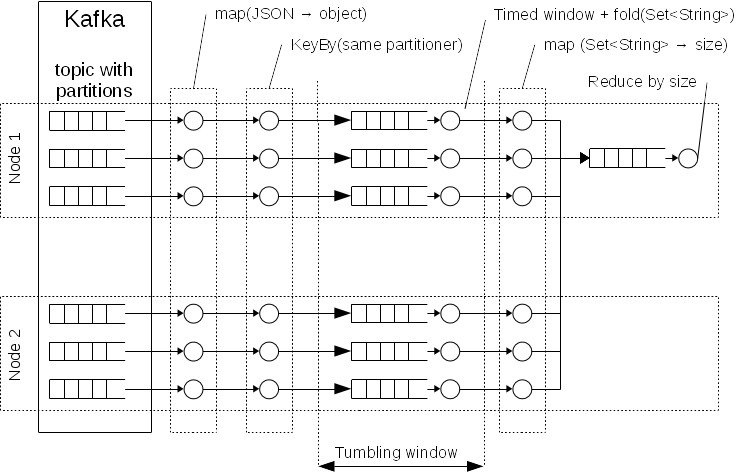
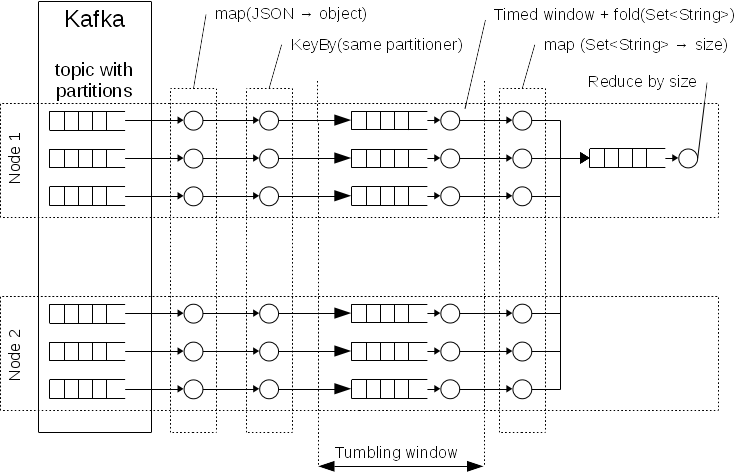
Hello, I want to implement something like a schema of processing which is presented on following diagram. This is calculation of number of unique users per specified time with assumption that we have > 100k events per second and > 100M unique users: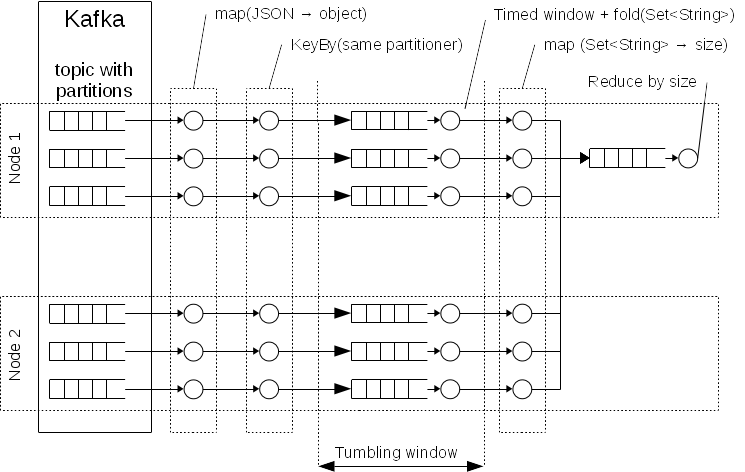 Basic assumption. I need to calculate a number of unique identifiers, so I need to store them in a memory in Set<String> structure but the size of this data structure is dozens GB. So I need to partitioning data by identifier to reduce size and collect only already calculated numbers per specified time. E.g. every hour.
PS: I found some information at http://data-artisans.com/kafka-flink-a-practical-how-to/ and https://www.elastic.co/blog/building-real-time-dashboard-applications-with-apache-flink-elasticsearch-and-kibana but unfortunately these articles doesn't answer how to build the specified schema. Cheers |
|
|
Hi rss, Concerning your questions: 1. There is currently no way to avoid the repartitioning. When you do a keyBy(), Flink will shuffle the data through the network. What you would need is a way to tell Flink that the data is already partitioned. If you would use keyed state, you would also need to ensure that the same hash function is used for the partitions and the state. 2. Why do you assume that this would end up in one partition? 3. You can also read old messages from a Kafka topic by setting the "auto.offset.reset" to "smallest" (or "latest") and using a new "group.id". I'll add Aljoscha and Kostas to the eMail. Maybe they can help with the incorrect results of the windowing. Regards, Robert On Thu, Aug 25, 2016 at 8:21 PM, rss rss <[hidden email]> wrote:
|
|
|
Hello, thanks for the answer.
Is it an assumption only or are some examples exist? Yesterday I wrote a question about incompatibility of keyed serializer in Flink with Kafka's deserializer. 2. Why do you assume that this would end up in one partition? Just assumption. I don't know ways how to check it. 3. You can also read old messages from a Kafka topic by setting the "auto.offset.reset" to "smallest" (or "latest") and using a new "group.id". Ok, I know about it. But "smallest" is a way to repeat test with same data. The question from my side in general. Is the implementation https://github.com/rssdev10/flink-kafka-streaming/blob/master/src/main/java/FlinkStreamingConsumer.java appropriate to the schema in the first email? Regarding the example. This small autonomous test is based on DIMA's project. And in this form you can use it, If it may be useful. Thanks, best regards. 2016-08-29 13:54 GMT+02:00 Robert Metzger <[hidden email]>:
|
«
Return to (DEPRECATED) Apache Flink User Mailing List archive.
|
1 view|%1 views
| Free forum by Nabble | Edit this page |