Kafka and Flink integration


|
I have to produce custom objects into kafka and read them with flink. Any tuning advices to use kryo? Such as class registration or something like that? Any examples?
Thanks |
Re: Kafka and Flink integration
|
|
Hi! It’s usually always recommended to register your classes with Kryo, to avoid the somewhat inefficient classname writing. Also, depending on the case, to decrease serialization overhead, nothing really beats specific custom serialization. So, you can also register specific serializers for Kryo to use for the type. If you need to store these custom objects as managed state for your operators, you can also have your own custom Flink TypeSerializer for that. Best, Gordon On 16 June 2017 at 12:27:06 PM, nragon ([hidden email]) wrote:
|
|
|
My custom object is used across all job, so it'll be part of checkpoints. Can you point me some references with some examples?
|
|
|
This post was updated on .
Do I need to use registerTypeWithKryoSerializer() in my execution environment and register() in kryo instance?
My serialization into kafka is done with the following snippet try (ByteArrayOutputStream byteArrayOutStream = new ByteArrayOutputStream(); Output output = new Output(byteArrayOutStream)) { Kryo kryo = new Kryo(); kryo.writeClassAndObject(output, event); output.flush(); return byteArrayOutStream.toByteArray(); } catch (IOException e) { return null; } "event" is my custom object. then i desirialize it in flink's kafka consumer try (ByteArrayInputStream byteArrayInStream = new ByteArrayInputStream(bytes); Input input = new Input(byteArrayInStream, bytes.length)) { Kryo kryo = new Kryo(); return kryo.readClassAndObject(input); } catch (IOException e) { return null; } Thanks |
|
|
|
|
In reply to this post by nragon
No, this is only necessary if you want to register a custom serializer itself
[1]. Also, in case you are wondering about registerKryoType() - this is only needed as a performance optimisation. What exactly is your problem? What are you trying to solve? (I can't read JFR files here, and from what I read at Oracle's site, this requires a commercial license, too...) Nico [1] https://ci.apache.org/projects/flink/flink-docs-release-1.3/dev/ custom_serializers.html On Tuesday, 20 June 2017 11:54:45 CEST nragon wrote: > Do I need to use registerTypeWithKryoSerializer() in my execution > environment? > My serialization into kafka is done with the following snippet > > try (ByteArrayOutputStream byteArrayOutStream = new ByteArrayOutputStream(); > Output output = new Output(byteArrayOutStream)) { > Kryo kryo = new Kryo(); > kryo.writeClassAndObject(output, event); > output.flush(); > return byteArrayOutStream.toByteArray(); > } catch (IOException e) { > return null; > } > > "event" is my custom object. > > then i desirialize it in flink's kafka consumer > try (ByteArrayInputStream byteArrayInStream = new > ByteArrayInputStream(bytes); Input input = new Input(byteArrayInStream, > bytes.length)) { > Kryo kryo = new Kryo(); > return kryo.readClassAndObject(input); > } catch (IOException e) { > return null; > } > > Thanks > > > > -- > View this message in context: > http://apache-flink-user-mailing-list-archive.2336050.n4.nabble.com/Kafka-a > nd-Flink-integration-tp13792p13841.html Sent from the Apache Flink User > Mailing List archive. mailing list archive at Nabble.com. |
|
|
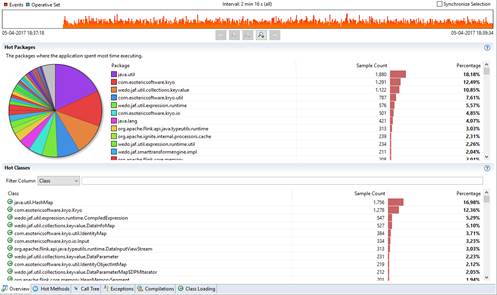
I believe there are some performance impact while de/serializing, which is “normal”. What I’m trying to understand is if there are any tips to improve this process. For instance, tuples vs general class types. Do you
know if it’s worth it to map a custom object into tuple just for de/serialization process? According to jfr analysis, kryo methods are hit a lot.
-----Original Message----- No, this is only necessary if you want to register a custom serializer itself [1]. Also, in case you are wondering about registerKryoType() - this is only needed as a performance optimisation. What exactly is your problem? What are you trying to solve? (I can't read JFR files here, and from what I read at Oracle's site, this requires a commercial license, too...) Nico [1]
https://ci.apache.org/projects/flink/flink-docs-release-1.3/dev/ custom_serializers.html On Tuesday, 20 June 2017 11:54:45 CEST nragon wrote: > Do I need to use registerTypeWithKryoSerializer() in my execution > environment? > My serialization into kafka is done with the following snippet > > try (ByteArrayOutputStream byteArrayOutStream = new ByteArrayOutputStream(); > Output output = new Output(byteArrayOutStream)) { > Kryo kryo = new Kryo(); > kryo.writeClassAndObject(output, event); > output.flush(); > return byteArrayOutStream.toByteArray(); > } catch (IOException e) { > return null; > } > > "event" is my custom object. > > then i desirialize it in flink's kafka consumer > try (ByteArrayInputStream byteArrayInStream = new > ByteArrayInputStream(bytes); Input input = new Input(byteArrayInStream, > bytes.length)) { > Kryo kryo = new Kryo(); > return kryo.readClassAndObject(input); > } catch (IOException e) { > return null; > } > > Thanks > > > > -- > View this message in context: >
http://apache-flink-user-mailing-list-archive.2336050.n4.nabble.com/Kafka-a > nd-Flink-integration-tp13792p13841.html Sent from the Apache Flink User > Mailing List archive. mailing list archive at Nabble.com. |
|
|
I can only repeat what Gordon wrote on Friday: "It’s usually always
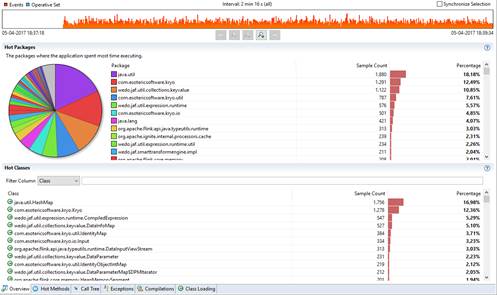
recommended to register your classes with Kryo [using registerKryoType()], to avoid the somewhat inefficient classname writing. Also, depending on the case, to decrease serialization overhead, nothing really beats specific custom serialization. So, you can also register specific serializers for Kryo to use for the type." I also guess, this highly depends on your actual use case and in particular the class you are trying to de/serialize. Unfortunately, your image is to small to read, but does your performance improve when registering the class as a Kryo type? Also, I don't think, mapping it to a tuple will improve performance since Kryo would have to do something similar anyway. Instead, you could really have your own de/serializer and go from "Class (<-> Tuple) <-> Kryo <-> bytes" directly to "Class <-> bytes". Nico On Tuesday, 20 June 2017 17:20:38 CEST Nuno Rafael Goncalves wrote: > I believe there are some performance impact while de/serializing, which is > "normal". What I'm trying to understand is if there are any tips to improve > this process. For instance, tuples vs general class types. Do you know if > it's worth it to map a custom object into tuple just for de/serialization > process? > > According to jfr analysis, kryo methods are hit a lot. > > [cid:image003.jpg@01D2E9E1.26D2D370] > > > > > > > > -----Original Message----- > From: Nico Kruber [mailto:[hidden email]] > Sent: 20 de junho de 2017 16:04 > To: [hidden email] > Cc: Nuno Rafael Goncalves <[hidden email]> > Subject: Re: Kafka and Flink integration > > > > No, this is only necessary if you want to register a custom serializer > itself [1]. Also, in case you are wondering about registerKryoType() - this > is only needed as a performance optimisation. > > > > What exactly is your problem? What are you trying to solve? > > (I can't read JFR files here, and from what I read at Oracle's site, this > requires a commercial license, too...) > > > > > > Nico > > > > [1] https://ci.apache.org/projects/flink/flink-docs-release-1.3/dev/ > > custom_serializers.html > > On Tuesday, 20 June 2017 11:54:45 CEST nragon wrote: > > Do I need to use registerTypeWithKryoSerializer() in my execution > > > > environment? > > > > My serialization into kafka is done with the following snippet > > > > > > > > try (ByteArrayOutputStream byteArrayOutStream = new > > ByteArrayOutputStream(); > > > > Output output = new Output(byteArrayOutStream)) { > > > > Kryo kryo = new Kryo(); > > > > kryo.writeClassAndObject(output, event); > > > > output.flush(); > > > > return byteArrayOutStream.toByteArray(); > > > > } catch (IOException e) { > > > > return null; > > > > } > > > > "event" is my custom object. > > > > > > > > then i desirialize it in flink's kafka consumer > > > > try (ByteArrayInputStream byteArrayInStream = new > > > > ByteArrayInputStream(bytes); Input input = new Input(byteArrayInStream, > > > > bytes.length)) { > > > > Kryo kryo = new Kryo(); > > > > return kryo.readClassAndObject(input); > > > > } catch (IOException e) { > > > > return null; > > > > } > > > > Thanks > > > > > > > > > > > > > > > > -- > > > > View this message in context: > > > > http://apache-flink-user-mailing-list-archive.2336050.n4.nabble.com/Kafka-> > a > > > > nd-Flink-integration-tp13792p13841.html Sent from the Apache Flink User > > > > Mailing List archive. mailing list archive at Nabble.com. |
|
|
In reply to this post by nragon
Hi Nuno, In general, if it is possible, it is recommended that you map your generic classes to Tuples / POJOs [1]. For Tuples / POJOs, Flink will create specialized serializers for them, whereas for generic classes (i.e. types which cannot be treated as POJOs) Flink simply fallbacks to using Kryo for them. The actual performance gain may depend a bit on what the original generic class type looked like. One other thing probably to look at is enabling object reuse for de-/serialization. However, be aware that the user code needs to be aware of this, otherwise it may lead to unexpected errors. Gordon [1] https://ci.apache.org/projects/flink/flink-docs-release-1.3/dev/types_serialization.html#rules-for-pojo-types
On 20 June 2017 at 11:24:03 PM, Nuno Rafael Goncalves ([hidden email]) wrote:
|
|
|
In reply to this post by Nico Kruber
Nico,
I'll try some different approaches and will be back here, hopefully with some results :) Thanks for this brainstorming :) -----Original Message----- From: Nico Kruber [mailto:[hidden email]] Sent: 20 de junho de 2017 16:44 To: Nuno Rafael Goncalves <[hidden email]> Cc: [hidden email] Subject: Re: Kafka and Flink integration I can only repeat what Gordon wrote on Friday: "It’s usually always recommended to register your classes with Kryo [using registerKryoType()], to avoid the somewhat inefficient classname writing. Also, depending on the case, to decrease serialization overhead, nothing really beats specific custom serialization. So, you can also register specific serializers for Kryo to use for the type." I also guess, this highly depends on your actual use case and in particular the class you are trying to de/serialize. Unfortunately, your image is to small to read, but does your performance improve when registering the class as a Kryo type? Also, I don't think, mapping it to a tuple will improve performance since Kryo would have to do something similar anyway. Instead, you could really have your own de/serializer and go from "Class (<-> Tuple) <-> Kryo <-> bytes" directly to "Class <-> bytes". Nico On Tuesday, 20 June 2017 17:20:38 CEST Nuno Rafael Goncalves wrote: > I believe there are some performance impact while de/serializing, > which is "normal". What I'm trying to understand is if there are any > tips to improve this process. For instance, tuples vs general class > types. Do you know if it's worth it to map a custom object into tuple > just for de/serialization process? > > According to jfr analysis, kryo methods are hit a lot. > > [cid:image003.jpg@01D2E9E1.26D2D370] > > > > > > > > -----Original Message----- > From: Nico Kruber [mailto:[hidden email]] > Sent: 20 de junho de 2017 16:04 > To: [hidden email] > Cc: Nuno Rafael Goncalves <[hidden email]> > Subject: Re: Kafka and Flink integration > > > > No, this is only necessary if you want to register a custom serializer > itself [1]. Also, in case you are wondering about registerKryoType() - > this is only needed as a performance optimisation. > > > > What exactly is your problem? What are you trying to solve? > > (I can't read JFR files here, and from what I read at Oracle's site, > this requires a commercial license, too...) > > > > > > Nico > > > > [1] https://ci.apache.org/projects/flink/flink-docs-release-1.3/dev/ > > custom_serializers.html > > On Tuesday, 20 June 2017 11:54:45 CEST nragon wrote: > > Do I need to use registerTypeWithKryoSerializer() in my execution > > > > environment? > > > > My serialization into kafka is done with the following snippet > > > > > > > > try (ByteArrayOutputStream byteArrayOutStream = new > > ByteArrayOutputStream(); > > > > Output output = new Output(byteArrayOutStream)) { > > > > Kryo kryo = new Kryo(); > > > > kryo.writeClassAndObject(output, event); > > > > output.flush(); > > > > return byteArrayOutStream.toByteArray(); > > > > } catch (IOException e) { > > > > return null; > > > > } > > > > "event" is my custom object. > > > > > > > > then i desirialize it in flink's kafka consumer > > > > try (ByteArrayInputStream byteArrayInStream = new > > > > ByteArrayInputStream(bytes); Input input = new > > Input(byteArrayInStream, > > > > bytes.length)) { > > > > Kryo kryo = new Kryo(); > > > > return kryo.readClassAndObject(input); > > > > } catch (IOException e) { > > > > return null; > > > > } > > > > Thanks > > > > > > > > > > > > > > > > -- > > > > View this message in context: > > > > http://apache-flink-user-mailing-list-archive.2336050.n4.nabble.com/ > > Kafka-> > a > > > > nd-Flink-integration-tp13792p13841.html Sent from the Apache Flink > > User > > > > Mailing List archive. mailing list archive at Nabble.com. |
|
|
In reply to this post by Tzu-Li Tai
Can i have pojo has composition of other pojo?
My custom object has many dependencies and in order to refactor it I must also change another 5 classes as well. |
RE: Kafka and Flink integration
|
|
Yes, POJOs can contain other nested POJO types. You just have to make sure that the nested field is either public, or has a corresponding public getter- and setter- method that follows the Java beans naming conventions. On 21 June 2017 at 12:20:31 AM, nragon ([hidden email]) wrote:
|
|
|
Thanks, I'll try to refactor into POJOs.
|
|
|
In reply to this post by Tzu-Li (Gordon) Tai
Just one more question :).
Considering I'm producing into kafka with other application other than flink, which serializer should i use in order to use pojo types when consuming those same messages (now in flink)? |
|
|
Hi! For general data exchange between systems, it is often good to have a more standard format. Being able to evolve the schema of types is very helpful if you evolve the data pipeline (which almost always happens eventually). For that reason, Avro and Thrift are very popular for that type of data exchange. While they are not as fast as Kryo, they are more "robust" in the sense that the format is stable. Kryo is a good choice for intermediate data that is not persistent or at least not leaving one specific system. Greetings, Stephan On Tue, Jun 20, 2017 at 7:22 PM, nragon <[hidden email]> wrote: Just one more question :). |
|
|
This post was updated on .
So,
1 - serialization between producer application -> kafka -> flink kafka consumer will use avro, thrift or kryo right? 2 - Should I use AbstractDeserializationSchema or TypeExtractor.getForClass(<MyCustomerObject>.class) in my DeserializationSchema? 3 - Remaining pipeline can just use standard pojo serialization, which would be better? 4 - How can i monitor which serialization mechnism flink is using? How can i force not to use kryo or avro during job runtime? 5 - Should I always define TypeInformation, for instance, using factory? |
|
|
The recommendation has been to avoid Kryo where possible.
General data exchange: avro or thrift. Flink internal data exchange: POJO (or Tuple, which are slightly faster though less readable, and there is an outstanding PR to narrow or close the performance gap). Kryo is useful for types which cannot be modified to be a POJO. There are also cases where Kryo must be used because Flink has insufficient TypeInformation, such as when returning an interface or abstract type when the actual concrete type can be known. > On Jun 21, 2017, at 3:19 AM, nragon <[hidden email]> wrote: > > So, serialization between producer application -> kafka -> flink kafka > consumer will use avro, thrift or kryo right? From there, the remaining > pipeline can just use standard pojo serialization, which would be better? > > > > -- > View this message in context: http://apache-flink-user-mailing-list-archive.2336050.n4.nabble.com/Kafka-and-Flink-integration-tp13792p13885.html > Sent from the Apache Flink User Mailing List archive. mailing list archive at Nabble.com. |
|
|
In reply to this post by nragon
Greg:
Can you clarify he last part? Should it be: the concrete type cannot be known ? -------- Original message -------- From: Greg Hogan <[hidden email]> Date: 6/21/17 3:10 AM (GMT-08:00) To: nragon <[hidden email]> Cc: [hidden email] Subject: Re: Kafka and Flink integration General data exchange: avro or thrift. Flink internal data exchange: POJO (or Tuple, which are slightly faster though less readable, and there is an outstanding PR to narrow or close the performance gap). Kryo is useful for types which cannot be modified to be a POJO. There are also cases where Kryo must be used because Flink has insufficient TypeInformation, such as when returning an interface or abstract type when the actual concrete type can be known. > On Jun 21, 2017, at 3:19 AM, nragon <[hidden email]> wrote: > > So, serialization between producer application -> kafka -> flink kafka > consumer will use avro, thrift or kryo right? From there, the remaining > pipeline can just use standard pojo serialization, which would be better? > > > > -- > View this message in context: http://apache-flink-user-mailing-list-archive.2336050.n4.nabble.com/Kafka-and-Flink-integration-tp13792p13885.html > Sent from the Apache Flink User Mailing List archive. mailing list archive at Nabble.com. |
|
|
If the concrete type cannot be known then a proper TypeInformation cannot be created and Kryo must be used.
There may be a few cases where the TypeInformation can be deduced by the developer but not by TypeExtractor and the returns TypeInformation must be explicitly given to prevent the use of Kryo. A recent example in Gelly was a Function with input and output types the same generic interface bound to different parameters. The implementation outputs the same concrete class as the input, but this programmatic structure cannot be deduced by the TypeExtractor so a returns TypeInformation was specified. Greg > On Jun 21, 2017, at 6:21 AM, Ted Yu <[hidden email]> wrote: > > Greg: > Can you clarify he last part? > Should it be: the concrete type cannot be known ? > > -------- Original message -------- > From: Greg Hogan <[hidden email]> > Date: 6/21/17 3:10 AM (GMT-08:00) > To: nragon <[hidden email]> > Cc: [hidden email] > Subject: Re: Kafka and Flink integration > > The recommendation has been to avoid Kryo where possible. > > General data exchange: avro or thrift. > > Flink internal data exchange: POJO (or Tuple, which are slightly faster though less readable, and there is an outstanding PR to narrow or close the performance gap). > > Kryo is useful for types which cannot be modified to be a POJO. There are also cases where Kryo must be used because Flink has insufficient TypeInformation, such as when returning an interface or abstract type when the actual concrete type can be known. > > > > > On Jun 21, 2017, at 3:19 AM, nragon <[hidden email]> wrote: > > > > So, serialization between producer application -> kafka -> flink kafka > > consumer will use avro, thrift or kryo right? From there, the remaining > > pipeline can just use standard pojo serialization, which would be better? > > > > > > > > -- > > View this message in context: http://apache-flink-user-mailing-list-archive.2336050.n4.nabble.com/Kafka-and-Flink-integration-tp13792p13885.html > > Sent from the Apache Flink User Mailing List archive. mailing list archive at Nabble.com. |
Re: Kafka and Flink integration
|
|
In reply to this post by Greg Hogan
Hi Greg,
do you have a link where I could read up on the rationale behind avoiding Kryo? I'm currently facing a similar decision and would like to get some more background on this. Thank you very much, Urs On 21.06.2017 12:10, Greg Hogan wrote: > The recommendation has been to avoid Kryo where possible. > > General data exchange: avro or thrift. > > Flink internal data exchange: POJO (or Tuple, which are slightly faster though less readable, and there is an outstanding PR to narrow or close the performance gap). > > Kryo is useful for types which cannot be modified to be a POJO. There are also cases where Kryo must be used because Flink has insufficient TypeInformation, such as when returning an interface or abstract type when the actual concrete type can be known. > > > >> On Jun 21, 2017, at 3:19 AM, nragon <[hidden email]> wrote: >> >> So, serialization between producer application -> kafka -> flink kafka >> consumer will use avro, thrift or kryo right? From there, the remaining >> pipeline can just use standard pojo serialization, which would be better? >> >> >> >> -- >> View this message in context: http://apache-flink-user-mailing-list-archive.2336050.n4.nabble.com/Kafka-and-Flink-integration-tp13792p13885.html >> Sent from the Apache Flink User Mailing List archive. mailing list archive at Nabble.com. > -- Urs Schönenberger - [hidden email] TNG Technology Consulting GmbH, Betastr. 13a, 85774 Unterföhring Geschäftsführer: Henrik Klagges, Christoph Stock, Dr. Robert Dahlke Sitz: Unterföhring * Amtsgericht München * HRB 135082 |
| Free forum by Nabble | Edit this page |