Kafka Producer - Null Pointer Exception when processing by element


|
I'm getting a NullPointerException when calling KakfaProducer010.processElement(StreamRecord<T>). Specifically, this comes from its helper function invokeInternally(), and the function's internalProducer not being configured properly, resulting in passing a null value to one its helper functions.
We'd really appreciate taking a look at below to see if this is a Flink bug or something we're doing wrong. Our codeThis is a simplified version of our program: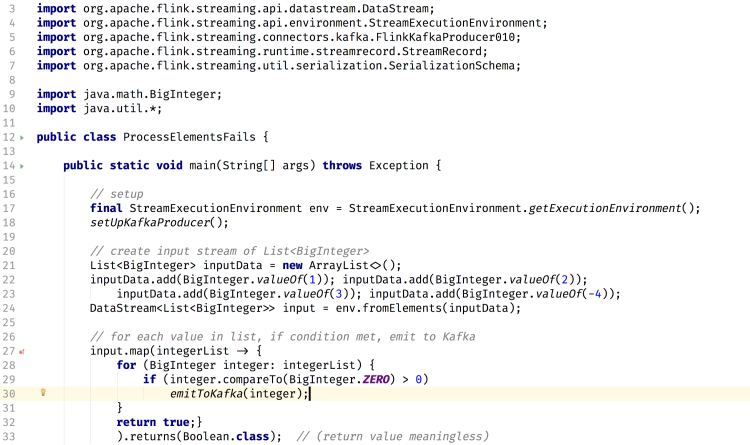  You can copy this code here to reproduce locally: https://pastebin.com/Li8iZuFj Stack traceHere is the stack trace: What causes error in Flink codeThe method processElement() calls invokeInternally(). Within invokeInternally(), Flink tries to parse variable values, e.g. topic name and partitions.The app fails when trying to resolve the partitions. Specifically, the method to resolve the partitions has a parameter of KafkaProducer, which is passed as null, resulting in the NullPointerException. See the highlighted lines below of running the program in debugger view. 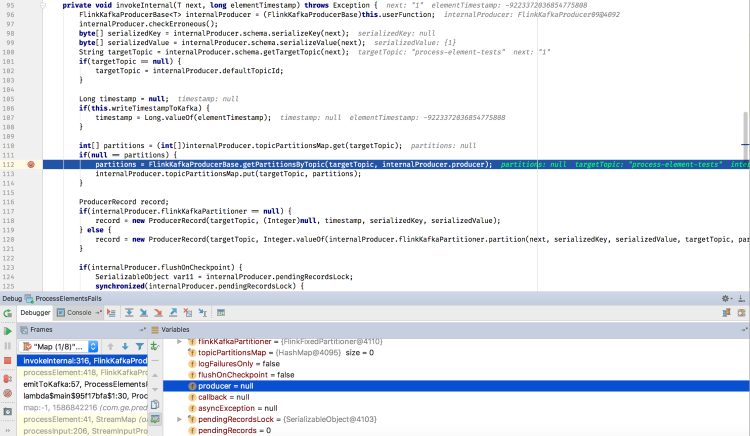 So, I think the issue is that the internalProducer is not being setup correctly. Namely, it never sets the value for its producer field, so this stays null and then gets passed around, resulting in the Null Pointer Exception. Bug? Or issue with our code?My question to you all is if this is a bug that needs to be fixed, or if it results from us improperly configuring our program? The above code shows our configuration within the program itself (just setting bootstrap.servers), and we created the Kafka topic on our local machine as follows:bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic process-elements-tests Any help greatly appreciated! We're really hoping to get processElements() to work, because our streaming architecture requires working on individual elements rather than the entire data stream (sink behavior depends on the individual values within each record of our DataStream<List<T>>). |
Re: Kafka Producer - Null Pointer Exception when processing by element
|
|
Hi, It seems like you’ve misunderstood how to use the FlinkKafkaProducer, or is there any specific reason why you want to emit elements to Kafka in a map function? The correct way to use it is to add it as a sink function to your pipeline, i.e. DataStream<String> someStream = … someStream.addSink(new FlinkKafkaProducer010<>(“topic”, schema, props)); // or, FlinkKafkaProducer010.writeToKafkaWithTimestamps(someStream, “topic”, schema, props); The processElement is invoked internally by the system, and isn’t intended to be invoked by user code. See [1] for more details. Cheers, Gordon On 15 July 2017 at 3:35:32 AM, earellano ([hidden email]) wrote:
|
|
|
The reason we want to use processElement() & a map function, instead of someStream.addSink() is that our output logic has conditional depending on the type of record we have. Our overall program follows this path: Serialized JSON consumed from Kafka: DataStream<byte []> parsed, producing a List of successful events and/or error events: DataStream<List<Events>> outputted conditionally, going to Kafka or Cassandra depending on which type of event it is. This is our code for output logic (although modified types to not use our IP): void output(DataStream<List<SuperclassEvent>> inputStream) { inputStream.map( eventList -> for (SuperclassEvent event : eventList) { if (event instanceof SuccessEvent) emitToCassandra(event); else if (event instanceof ErrorEvent) emitToKafka(event); } return true; // we don't actually want to return anything, just don't know how else to use map ); That is, we have sinks for both Kafka and Cassandra, and want to be able to iterate through our List<SuperclassElement> and conditionally send each individual record to its appropriate sink depending on its type. I know Flink offers SplitStreams for a similar purpose, but this doesn't seem very ideal to us because it requires a new operator to first split the stream, and only after the whole List is processed can the records then be sent to their respective sinks. Whereas the code above sends the records to their sinks immediately upon finding its type. -- Is there any way to make processElement() work so that we can work on individual records instead of the whole DataStream? Or are we misusing Flink? How do you recommend doing this the best way possible? -- Also, if processElement() and invoke() aren't meant to be used, should they be made package private? Happy to make a pull request if so, although fear that might break a few things. |
Re: Kafka Producer - Null Pointer Exception when processing by element
|
|
Hi, void output(DataStream<List<SuperclassEvent>> inputStream) { These seems odd. Are your events intended to be a list? If not, this should be a `DataStream<SuperclassEvent>`. From the code snippet you’ve attached in the first post, it seems like you’ve initialized your source incorrectly. `env.fromElements(List<...>)` will take the whole list as a single event, thus your source is only emitting a single list as a record. Perhaps what you actually want to do here is `env.fromCollection(List<...>)`? This should also eliminate the situation that “only after the whole List is processed can the records then be sent to their respective sinks”, as you mentioned in your reply. but this doesn't seem very ideal to us because it requires a new operator to first split the stream IMO, this wouldn’t really introduce noticeable overhead, as the operator will be chained to the map operator. Side outputs is also the preferred way here, as side outputs subsume stream splitting. Overall, I think it is reasonable to do a map -> split -> Kafka / Cassandra sinks in your case, given that you’ve declared the source correctly to be a single SuperclassEvent as a record. The operator overhead is fairly trivial if it is chained. Another reason to use sinks properly is that only then will you benefit from the exactly-once / at-least-once delivery guarantees to external systems (which requires collaboration between the sink and Flink’s checkpointing). Hope this helps! Cheers, Gordon On 17 July 2017 at 2:59:38 AM, earellano [via Apache Flink User Mailing List archive.] ([hidden email]) wrote:
|
|
|
Hi,
Ah sorry for the confusion. So the original code snippet isn't our actual code - it's a simplified and generified version so that it would be easy to reproduce the Null Pointer Exception without having to show our whole code base. To clarify, our input actually uses a Kafka Consumer that reads a byte[], which is then passed to our external library parser which takes a byte[] and converts it into a List<Events>. This is why we have to use DataStream<List<Events>>, rather than just DataStream<Event>. It's a requirement from the parser we have to use, because each byte[] array record can create both a SuccessEvent(s) and/or ErrorEvent(s). Our motivation for using the above map & for loop with conditional output logic was that we have to work with this whole List<Events> and not just individual Events, but don't want to wait for the whole list to be processed for the event at the beginning of the list to be outputted. For example, a byte[] record can return from our parser a List of 10 SuccessEvents and 1 ErrorEvent; we want to publish each Event immediately. Low latency is extremely important to us. -- With task chaining as you're saying, could you help clarify how it works please? With each record of type List<Events> and calling the Split Operator followed by the sink operators, does that whole record/list have to be split before it can then go on to the sink? Or does task chaining mean it immediately gets outputted to the sink? Thanks so much for all this help by the way! |
Re: Kafka Producer - Null Pointer Exception when processing by element
|
|
With task chaining as you're saying, could you help clarify how it works Operator can be chained to be executed by a single task thread. See [1] for more details on that. Basically, when two operators are chained together, the output of the first operator is immediately chained to the processElement of the next operator; it’s therefore just a consecutive invocation of processElements on the chained operators. There will be no thread-to-thread handover or buffering. For example, a In that case, I would suggest using flatMap here, followed by chained splits and then sinks. Using flatMap, you can collect elements as you iterate through the list element (i.e. `collector.collect(...)`). If the sinks are properly chained (which should be the case if there is no keyBy before the sink and you haven’t explicitly configured otherwise [2]), then for each .collect(...) the sink write will be invoked as part of the chain. Effectively, this would then be writing to Kafka / Cassandra for every element as you iterate through that list (happening in the same thread since everything is chained), and matches what you have in mind. On 17 July 2017 at 2:06:52 PM, earellano ([hidden email]) wrote:
|
|
|
Okay great, chaining tasks does sound like what we want then. We changed our code to roughly follow this suggestion, but I'm not sure we're doing this correctly? Is there a better way you recommend chaining the tasks? As written below, are individual Events within the List being sent to their respective sinks right away, or does the whole list have to split first? 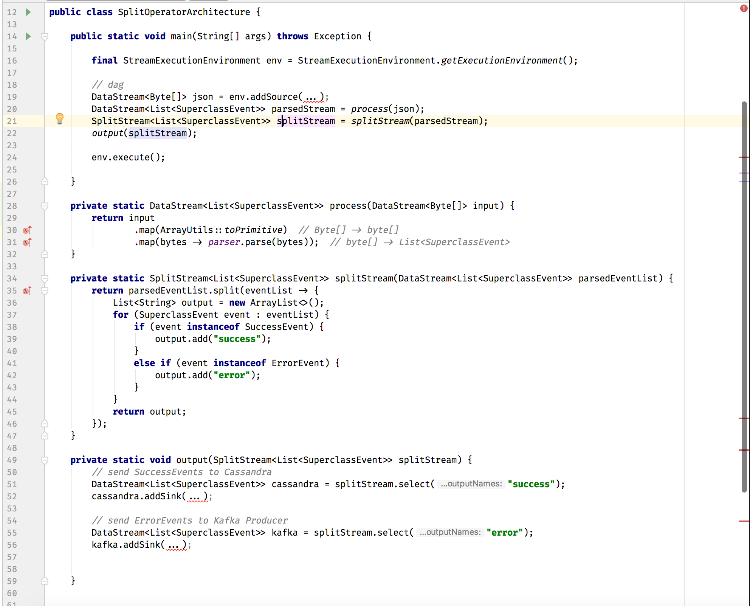 We also had issues getting flatMap to work, and map seemed more appropriate. Our parser.parse() function has a one-to-one mapping between an input byte[] to a List<SuperclassEvent>, and that never changes, so a map seems to make sense to us. Were you suggesting a flatMap instead of map at this stage of calling our parser, or did you mean to use a flatMap() after the parser and before the split()? |
Re: Kafka Producer - Null Pointer Exception when processing by element
|
|
Our parser.parse() function has a one-to-one mapping between an input byte[] Ideally, this should be handled within the KeyedDeserializationSchema passed to your Kafka consumer. That would then avoid the need of an extra “parser map function” after the source. Were you suggesting a flatMap instead of map at this stage of I meant a flatMap after the parser (whether it’s done as a map function or within the Kafka source) and before the split. The flatMap function iterates through your per-record lists and collects as it iterates through them. - Gordon On 18 July 2017 at 3:02:45 AM, earellano ([hidden email]) wrote:
|
| Free forum by Nabble | Edit this page |