Joining and Grouping Flink Tables with Java API

Joining and Grouping Flink Tables with Java API

|
Hi, We're trying to use Flink 1.11 Java tables API to process a streaming use case:We have 2 streams, each one with different structures. Both events, coming from Kafka, can be: - A new event (not in the system already) - An updated event (updating an event that previously was inserted) so we only want to store the latest data in the Table. We need to join the 2 previous Tables to have all this data stored in the Flink system. We think
that the best way is to store joined data as a Table. This
is going to be a Flink Table, that will be a join of the 2 tables by a
common key. To sum up, we have: - Stream 1 (coming from Kafka topic) -> Flink Table 1 - Stream 2 (coming from Kafka topic) -> Flink Table 2 - Table 3 = Table 1 join Table 2 - DataStream using RetractStream of Table 3 To get the last element in Table 1 and Table 2, we are using Functions (LastValueAggFunction): streamTableEnvironment.registerFunction("LAST_VALUE_STRING", new LastValueAggFunction.StringLastValueAggFunction()); The questions are: - Is our approach correct to get the data stored in the Flink system? - Is it necessary to use the LastValueAggFunction in our case ? as we want to retract the stream to out custom Pojo instead of Row, but we're getting the attached error: (attached: stack_trace.log) Abdelilah Choukdi, Backend dev at ManoMano. |
Re: Joining and Grouping Flink Tables with Java API
|
|
Hi Abdelilah, I think your approach is overly complicated (and probably slow) but I might have misunderstood things. Naively, I'd assume that you just want to union stream 1 and stream 2 instead of joining. Note that for union the events must have the same schema, so you most likely want to have a select on each stream before union. Summarizing: Table3 = (select id, title, description from Table 1) union (select id, title, description from Table 2) If you use a retract stream, you probably do not need to use the grouping and last value selection as well. On Mon, Feb 8, 2021 at 3:33 PM Abdelilah CHOUKRI <[hidden email]> wrote:
|
Re: Joining and Grouping Flink Tables with Java API
|
|
Thank you Arvid for the reply, In fact, it's not a union of the same data, I'll try to explain what we want to achieve as a concept:We have 2 data sources, with two different schemas, but with a common field/attribute (example: brandId), - Cars: receive data entries with high frequency, one Car can only be related to one Brand. (with the field brandId)I'll try to explain the behaviour that we want to achieve with the following diagram: 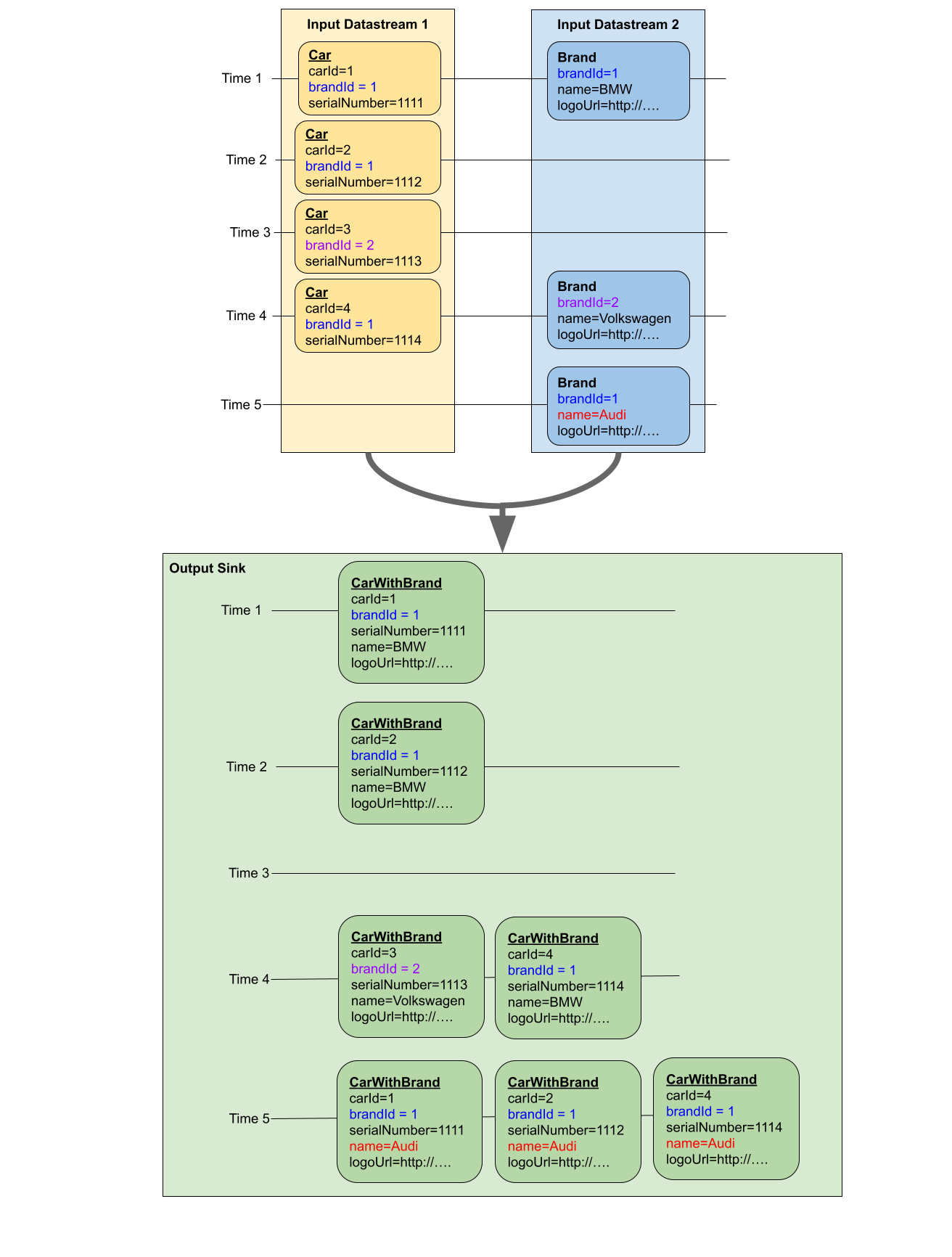 - Time 1: we have a Car and a Brand matching by brandId, so the output should return a corresponding CarWithRand. - Time 2: we have a new Car, also it matched the previous Brand, so we output a CarWithBrand. - Time 4: we have a new Car that matches the previous brand, and on the other hand, we received a new Brand that matches the previous Car, so we should have two outputs. - Time 5: we receive an existing brand, but with an updated field (in this case the name), so we have to replace the previous Brand with brandId, and if there are any previous matching Cars, we have to output all the corresponding CarWithBrand with the changed field. So, we're using Flink Tables during the process, to maintain the latest status of the data regardless of time. And furthermore, here's a simplified java code example that represents what we've achieved so far: flink_join.java How would you recommend to achieve this with Flink ? Is our approach adequate ? Thank you. On Thu, Feb 11, 2021 at 11:50 AM Arvid Heise <[hidden email]> wrote:
|
Re: Joining and Grouping Flink Tables with Java API
|
|
Hi Abdelilah,
at a first glance your logic seems to be correct. But Arvid is right that your pipeline might not have the optimal performance that Flink can offer due to the 3 groupBy operations. I'm wondering what the optimizer produces out of this plan. Maybe you can share it with us using `table.explain()` on the final table? I think what Arvid meant is a UNION ALL in SQL. You would normalize the two streams into a CarWithBrand before (containing nulls for the other side), and then groupBy/aggregate to the last value and filter out invalid CarWithBrands. If DataStream API is an option for you I would consider using the `connect()` method. A connect function can be stateful and you might reduce your state size further. In your current implementation, the join operator will store all input tables for processing. This means car and brand state is stored twice. Regards, Timo On 11.02.21 16:06, Abdelilah CHOUKRI wrote: > Thank you Arvid for the reply, > > In fact, it's not a union of the same data, I'll try to explain what we > want to achieve as a concept: > > We have 2 data sources, with two different schemas, but with a common > field/attribute (example: /brandId/), > - /Cars/: receive data entries with high frequency, one /Car/ can only > be related to one /Brand/. (with the field /brandId/) > - /Brands/: receive data entries with high frequency, one /Brand/ can be > related to many /Cars/. (with the field /brandId/) > And we need to "merge" these data in a single output: /CarWithBrand/. > > I'll try to explain the behaviour that we want to achieve with the > following diagram: > > flink_flow.png > > - Time 1: we have a /Car/ and a /Brand/ matching by /brandId, /so the > output should return a corresponding /CarWithRand. > / > /- /Time 2: we have a new /Car/, also it matched the previous /Brand/, > so we output a /CarWithBrand./ > - Time 3: we receive a new /Car/, but it does not match any existing > /Brand,/ so no output./ > / > - Time 4: we have a new Car that matches the previous brand, and on the > other hand, > we received a new Brand that matches the previous Car, > so we should have two outputs. > - Time 5: we receive an existing brand, but with an updated field (in > this case the name), so we have > to replace the previous Brand with brandId, and if there > are any previous matching Cars, we > have to output all the corresponding CarWithBrand with > the changed field. > > So, we're using Flink Tables during the process, to maintain the latest > status of the data regardless of time. > > And furthermore, here's a simplified java code example that represents > what we've achieved so far:*flink_join.java* > > How would you recommend to achieve this with Flink ? > Is our approach adequate ? > > Thank you. > > On Thu, Feb 11, 2021 at 11:50 AM Arvid Heise <[hidden email] > <mailto:[hidden email]>> wrote: > > Hi Abdelilah, > > I think your approach is overly complicated (and probably slow) but > I might have misunderstood things. Naively, I'd assume that you just > want to union stream 1 and stream 2 instead of joining. Note that > for union the events must have the same schema, so you most likely > want to have a select on each stream before union. Summarizing: > Table3 = (select id, title, description from Table 1) union (select > id, title, description from Table 2) > > If you use a retract stream, you probably do not need to use the > grouping and last value selection as well. > > On Mon, Feb 8, 2021 at 3:33 PM Abdelilah CHOUKRI > <[hidden email] > <mailto:[hidden email]>> wrote: > > Hi, > > We're trying to use Flink 1.11 Java tables API to process a > streaming use case: > > We have 2 streams, each one with different structures. Both > events, coming from Kafka, can be: > - A new event (not in the system already) > - An updated event (updating an event that previously was inserted) > so we only want to store the latest data in the Table. > > We need to join the 2 previous Tables to have all this data > stored in the Flink system. We think that the best way is to > store joined data as a Table. > This is going to be a Flink Table, that will be a join of the 2 > tables by a common key. > > To sum up, we have: > - Stream 1 (coming from Kafka topic) -> Flink Table 1 > - Stream 2 (coming from Kafka topic) -> Flink Table 2 > - Table 3 = Table 1 join Table 2 > - DataStream using RetractStream of Table 3 > > To get the last element in Table 1 and Table 2, we are using > Functions (LastValueAggFunction): > > streamTableEnvironment.registerFunction("LAST_VALUE_STRING", new LastValueAggFunction.StringLastValueAggFunction()); > ... > streamTableEnvironment.fromDataStream(inputDataStream) > .groupBy($("id")) > .select( > $("id").as("o_id"), > call("LAST_VALUE_STRING", $("title")).as("o_title"), > call("LAST_VALUE_STRING", $("description")).as("o_description") > ); > > > The questions are: > - Is our approach correct to get the data stored in the Flink > system? > - Is it necessary to use the _/LastValueAggFunction /_in our > case ? as we want to retract the stream to > out custom Pojo instead of _/Row/_, but we're getting the > attached error: (attached*: stack_trace.log*) > > > Abdelilah Choukdi, > Backend dev at ManoMano. > |
Re: Joining and Grouping Flink Tables with Java API
|
|
After thinking about this topic again, I think UNION ALL will not solve
the problem because you would need to group by brandId and perform the joining within the aggregate function which could also be quite expensive. Regards, Timo On 11.02.21 17:16, Timo Walther wrote: > Hi Abdelilah, > > at a first glance your logic seems to be correct. But Arvid is right > that your pipeline might not have the optimal performance that Flink can > offer due to the 3 groupBy operations. I'm wondering what the optimizer > produces out of this plan. Maybe you can share it with us using > `table.explain()` on the final table? > > I think what Arvid meant is a UNION ALL in SQL. You would normalize the > two streams into a CarWithBrand before (containing nulls for the other > side), and then groupBy/aggregate to the last value and filter out > invalid CarWithBrands. > > If DataStream API is an option for you I would consider using the > `connect()` method. A connect function can be stateful and you might > reduce your state size further. In your current implementation, the join > operator will store all input tables for processing. This means car and > brand state is stored twice. > > Regards, > Timo > > On 11.02.21 16:06, Abdelilah CHOUKRI wrote: >> Thank you Arvid for the reply, >> >> In fact, it's not a union of the same data, I'll try to explain what >> we want to achieve as a concept: >> >> We have 2 data sources, with two different schemas, but with a common >> field/attribute (example: /brandId/), >> - /Cars/: receive data entries with high frequency, one /Car/ can only >> be related to one /Brand/. (with the field /brandId/) >> - /Brands/: receive data entries with high frequency, one /Brand/ can >> be related to many /Cars/. (with the field /brandId/) >> And we need to "merge" these data in a single output: /CarWithBrand/. >> >> I'll try to explain the behaviour that we want to achieve with the >> following diagram: >> >> flink_flow.png >> >> - Time 1: we have a /Car/ and a /Brand/ matching by /brandId, /so the >> output should return a corresponding /CarWithRand. >> / >> /- /Time 2: we have a new /Car/, also it matched the previous /Brand/, >> so we output a /CarWithBrand./ >> - Time 3: we receive a new /Car/, but it does not match any existing >> /Brand,/ so no output./ >> / >> - Time 4: we have a new Car that matches the previous brand, and on >> the other hand, >> we received a new Brand that matches the previous Car, >> so we should have two outputs. >> - Time 5: we receive an existing brand, but with an updated field (in >> this case the name), so we have >> to replace the previous Brand with brandId, and if >> there are any previous matching Cars, we >> have to output all the corresponding CarWithBrand with >> the changed field. >> >> So, we're using Flink Tables during the process, to maintain the >> latest status of the data regardless of time. >> >> And furthermore, here's a simplified java code example that represents >> what we've achieved so far:*flink_join.java* >> >> How would you recommend to achieve this with Flink ? >> Is our approach adequate ? >> >> Thank you. >> >> On Thu, Feb 11, 2021 at 11:50 AM Arvid Heise <[hidden email] >> <mailto:[hidden email]>> wrote: >> >> Hi Abdelilah, >> >> I think your approach is overly complicated (and probably slow) but >> I might have misunderstood things. Naively, I'd assume that you just >> want to union stream 1 and stream 2 instead of joining. Note that >> for union the events must have the same schema, so you most likely >> want to have a select on each stream before union. Summarizing: >> Table3 = (select id, title, description from Table 1) union (select >> id, title, description from Table 2) >> >> If you use a retract stream, you probably do not need to use the >> grouping and last value selection as well. >> >> On Mon, Feb 8, 2021 at 3:33 PM Abdelilah CHOUKRI >> <[hidden email] >> <mailto:[hidden email]>> wrote: >> >> Hi, >> >> We're trying to use Flink 1.11 Java tables API to process a >> streaming use case: >> >> We have 2 streams, each one with different structures. Both >> events, coming from Kafka, can be: >> - A new event (not in the system already) >> - An updated event (updating an event that previously was >> inserted) >> so we only want to store the latest data in the Table. >> >> We need to join the 2 previous Tables to have all this data >> stored in the Flink system. We think that the best way is to >> store joined data as a Table. >> This is going to be a Flink Table, that will be a join of the 2 >> tables by a common key. >> >> To sum up, we have: >> - Stream 1 (coming from Kafka topic) -> Flink Table 1 >> - Stream 2 (coming from Kafka topic) -> Flink Table 2 >> - Table 3 = Table 1 join Table 2 >> - DataStream using RetractStream of Table 3 >> >> To get the last element in Table 1 and Table 2, we are using >> Functions (LastValueAggFunction): >> >> streamTableEnvironment.registerFunction("LAST_VALUE_STRING", >> new LastValueAggFunction.StringLastValueAggFunction()); >> ... >> streamTableEnvironment.fromDataStream(inputDataStream) >> .groupBy($("id")) >> .select( >> $("id").as("o_id"), >> call("LAST_VALUE_STRING", $("title")).as("o_title"), >> call("LAST_VALUE_STRING", $("description")).as("o_description") >> ); >> >> >> The questions are: >> - Is our approach correct to get the data stored in the Flink >> system? >> - Is it necessary to use the _/LastValueAggFunction /_in our >> case ? as we want to retract the stream to >> out custom Pojo instead of _/Row/_, but we're getting the >> attached error: (attached*: stack_trace.log*) >> >> >> Abdelilah Choukdi, >> Backend dev at ManoMano. >> > |
Re: Joining and Grouping Flink Tables with Java API
|
|
Hi Abdelilah, you are right that union does not work (well) in your case. I misunderstood the relation between the two streams. The ideal pattern would be a broadcast join imho. [1] I'm not sure how to do it in Table API/SQL though, but I hope Timo can help here as well. On Thu, Feb 11, 2021 at 7:00 PM Timo Walther <[hidden email]> wrote: After thinking about this topic again, I think UNION ALL will not solve |
Re: Joining and Grouping Flink Tables with Java API
|
|
Thank you guys for the interest, feedback and advies, Form each DataStream we only interested in the last updated or new Event, Just to clarify further on the why we used tables with grouping, duplicated events (same data/fields as the stored ones) will be ignored. So as we understood - and please correct us if we're wrong - we can achieve this behaviour with the following steps: step 1: Register the LastValueFunctions for each column type, so we can store only the last incoming Event, and when we retract to the stream, we can filter in later stage the Events that have been changed/updated (step 4). StreamTableEnvironment streamTableEnvironment = StreamTableEnvironment.create(streamExecutionEnvironment, ...);
streamTableEnvironment.registerFunction("LAST_VALUE_STRING", new LastValueAggFunction.StringLastValueAggFunction());
streamTableEnvironment.registerFunction("LAST_VALUE_LONG", new LastValueAggFunction.LongLastValueAggFunction());
streamTableEnvironment.registerFunction("LAST_VALUE_BOOLEAN", new LastValueAggFunction.BooleanLastValueAggFunction());
step 2:
Use Flink Table and group them by Id to store the latest data regardless
of the Window time, (as if it was Primary Key in a SQL Table)Table carTable = streamTableEnvironment.fromDataStream(carStream)
.groupBy($("carId"))
.select(
$("carId").as("c_carId"),
call("LAST_VALUE_LONG", $("brandId")).as("c_brandId"),
call("LAST_VALUE_LONG", $("serialNumber")).as("c_serialNumber"),
call("LAST_VALUE_STRING", $("carName")).as("c_carName")
);step 3: Join both tables by the common Id, and group them by another to merge both datas. Table brandCarTable = carTable.join(brandTable)
.where($("c_brandId").isEqual($("b_brandId")))
.groupBy($("c_carId"))
.select(
$("c_carId").as("carId"),
call("LAST_VALUE_LONG", $("b_brandId")).as("brandId"),
call("LAST_VALUE_LONG", $("c_serialNumber")).as("serialNumber"),
call("LAST_VALUE_STRING", $("c_carName")).as("carName"),
call("LAST_VALUE_STRING", $("b_brandName")).as("brandName")
);step 4: Retract the joined/grouped data, and filter by the boolean `flaggedJoin.f0`, as we understood, only the new/updated Events will be flagged `True`. DataStream<BrandCar> brandCarStream = streamTableEnvironment.toRetractStream(brandCarTable, BrandCar.class) .filter(flaggedJoin -> flaggedJoin.f0) .map(changedJoin -> changedJoin.f1) .flatMap(...); - Have we misunderstood the usage of LastValueFunctions ? - Could we achieve the same with only DataStreas ? (without using Tables) - If we switch to DataSteams, how can we store all the previous events regardless of Time (without a Window) - You seem to be concerned about the performance of the groupings, is it regardless of what we use ? (DataSteams or Tables) Thank you again, we're checking your suggestion about Broadcast. On Thu, Feb 11, 2021 at 9:28 PM Arvid Heise <[hidden email]> wrote:
|
Re: Joining and Grouping Flink Tables with Java API
|
|
Hi,
yes, we can confirm that your program has the behavior you mentioned. Since we don't use any type of time operation or windowing, your query has updating semantics. State is used for keeping the LAST_VALUEs as well as the full input tables of the JOIN. You can achieve the same with a KeyedCoProcessFunction (see the connect API [1][2]) that uses ValueState. Regards, Timo [1] https://ci.apache.org/projects/flink/flink-docs-release-1.12/dev/stream/operators/#connect [2] https://ci.apache.org/projects/flink/flink-docs-stable/dev/stream/operators/process_function.html#low-level-joins On 15.02.21 09:44, Abdelilah CHOUKRI wrote: > Thank you guys for the interest, feedback and advies, > > Just to clarify further on the why we used tables with grouping, > Form each DataStream we only interested in the last updated or new Event, > Also, we need to have ALL the previous Events storedin order to identify > if the incoming event is a new or an updated, > duplicated events (same data/fields as the stored ones) will be ignored. > So as we understood - and please correct us if we're wrong - we can > achieve this behaviour with the following steps: > > *_step 1:_* Register the LastValueFunctions for each column type, so we > can store only the last incoming Event, > and when we retract to the stream, we can filter in later stage the > Events that have been changed/updated (step 4). > > StreamTableEnvironment streamTableEnvironment = > StreamTableEnvironment.create(streamExecutionEnvironment, ...); > streamTableEnvironment.registerFunction("LAST_VALUE_STRING", new > LastValueAggFunction.StringLastValueAggFunction()); > streamTableEnvironment.registerFunction("LAST_VALUE_LONG", new > LastValueAggFunction.LongLastValueAggFunction()); > streamTableEnvironment.registerFunction("LAST_VALUE_BOOLEAN", new > LastValueAggFunction.BooleanLastValueAggFunction()); > > *_step 2:_* Use Flink Table and group them by Id to store the latest > data regardless of the Window time, (as if it was Primary Key in a SQL > Table) > > Table carTable = streamTableEnvironment.fromDataStream(carStream) > .groupBy($("carId")) .select( $("carId").as("c_carId"), > call("LAST_VALUE_LONG", $("brandId")).as("c_brandId"), > call("LAST_VALUE_LONG", $("serialNumber")).as("c_serialNumber"), > call("LAST_VALUE_STRING", $("carName")).as("c_carName") ); > > > *_step 3:_* Join both tables by the common Id, and group them by another > to merge both datas. > > Table brandCarTable = carTable.join(brandTable) > .where($("c_brandId").isEqual($("b_brandId"))) .groupBy($("c_carId")) > .select( $("c_carId").as("carId"), call("LAST_VALUE_LONG", > $("b_brandId")).as("brandId"), call("LAST_VALUE_LONG", > $("c_serialNumber")).as("serialNumber"), call("LAST_VALUE_STRING", > $("c_carName")).as("carName"), call("LAST_VALUE_STRING", > $("b_brandName")).as("brandName") ); > > > *_step 4:_* Retract the joined/grouped data, and filter by the boolean > `*flaggedJoin.f0*`, as we understood, only the new/updated Events will > be flagged `*True*`. > > DataStream<BrandCar> brandCarStream = > streamTableEnvironment.toRetractStream(brandCarTable, BrandCar.class) > .filter(flaggedJoin -> flaggedJoin.f0) > .map(changedJoin -> changedJoin.f1) > .flatMap(...); > > - Have we misunderstood the usage of LastValueFunctions ? > - Could we achieve the same with only DataStreas ? (without using Tables) > - If we switch to DataSteams, how can we store all the previous events > regardless of Time (without a Window) > - You seem to be concerned about the performance of the groupings, is it > regardless of what we use ? (DataSteams or Tables) > > Thank you again, we're checking your suggestion about Broadcast. > > > On Thu, Feb 11, 2021 at 9:28 PM Arvid Heise <[hidden email] > <mailto:[hidden email]>> wrote: > > Hi Abdelilah, > > you are right that union does not work (well) in your case. I > misunderstood the relation between the two streams. > > The ideal pattern would be a broadcast join imho. [1] I'm not sure > how to do it in Table API/SQL though, but I hope Timo can help here > as well. > > [1] > https://ci.apache.org/projects/flink/flink-docs-stable/dev/stream/state/broadcast_state.html > <https://ci.apache.org/projects/flink/flink-docs-stable/dev/stream/state/broadcast_state.html> > > On Thu, Feb 11, 2021 at 7:00 PM Timo Walther <[hidden email] > <mailto:[hidden email]>> wrote: > > After thinking about this topic again, I think UNION ALL will > not solve > the problem because you would need to group by brandId and > perform the > joining within the aggregate function which could also be quite > expensive. > > Regards, > Timo > > On 11.02.21 17:16, Timo Walther wrote: > > Hi Abdelilah, > > > > at a first glance your logic seems to be correct. But Arvid > is right > > that your pipeline might not have the optimal performance > that Flink can > > offer due to the 3 groupBy operations. I'm wondering what the > optimizer > > produces out of this plan. Maybe you can share it with us using > > `table.explain()` on the final table? > > > > I think what Arvid meant is a UNION ALL in SQL. You would > normalize the > > two streams into a CarWithBrand before (containing nulls for > the other > > side), and then groupBy/aggregate to the last value and > filter out > > invalid CarWithBrands. > > > > If DataStream API is an option for you I would consider using > the > > `connect()` method. A connect function can be stateful and > you might > > reduce your state size further. In your current > implementation, the join > > operator will store all input tables for processing. This > means car and > > brand state is stored twice. > > > > Regards, > > Timo > > > > On 11.02.21 16:06, Abdelilah CHOUKRI wrote: > >> Thank you Arvid for the reply, > >> > >> In fact, it's not a union of the same data, I'll try to > explain what > >> we want to achieve as a concept: > >> > >> We have 2 data sources, with two different schemas, but with > a common > >> field/attribute (example: /brandId/), > >> - /Cars/: receive data entries with high frequency, one > /Car/ can only > >> be related to one /Brand/. (with the field /brandId/) > >> - /Brands/: receive data entries with high frequency, one > /Brand/ can > >> be related to many /Cars/. (with the field /brandId/) > >> And we need to "merge" these data in a single output: > /CarWithBrand/. > >> > >> I'll try to explain the behaviour that we want to achieve > with the > >> following diagram: > >> > >> flink_flow.png > >> > >> - Time 1: we have a /Car/ and a /Brand/ matching by > /brandId, /so the > >> output should return a corresponding /CarWithRand. > >> / > >> /- /Time 2: we have a new /Car/, also it matched the > previous /Brand/, > >> so we output a /CarWithBrand./ > >> - Time 3: we receive a new /Car/, but it does not match any > existing > >> /Brand,/ so no output./ > >> / > >> - Time 4: we have a new Car that matches the previous brand, > and on > >> the other hand, > >> we received a new Brand that matches the > previous Car, > >> so we should have two outputs. > >> - Time 5: we receive an existing brand, but with an updated > field (in > >> this case the name), so we have > >> to replace the previous Brand with brandId, > and if > >> there are any previous matching Cars, we > >> have to output all the corresponding > CarWithBrand with > >> the changed field. > >> > >> So, we're using Flink Tables during the process, to maintain > the > >> latest status of the data regardless of time. > >> > >> And furthermore, here's a simplified java code example that > represents > >> what we've achieved so far:*flink_join.java* > >> > >> How would you recommend to achieve this with Flink ? > >> Is our approach adequate ? > >> > >> Thank you. > >> > >> On Thu, Feb 11, 2021 at 11:50 AM Arvid Heise > <[hidden email] <mailto:[hidden email]> > >> <mailto:[hidden email] <mailto:[hidden email]>>> wrote: > >> > >> Hi Abdelilah, > >> > >> I think your approach is overly complicated (and > probably slow) but > >> I might have misunderstood things. Naively, I'd assume > that you just > >> want to union stream 1 and stream 2 instead of joining. > Note that > >> for union the events must have the same schema, so you > most likely > >> want to have a select on each stream before union. > Summarizing: > >> Table3 = (select id, title, description from Table 1) > union (select > >> id, title, description from Table 2) > >> > >> If you use a retract stream, you probably do not need to > use the > >> grouping and last value selection as well. > >> > >> On Mon, Feb 8, 2021 at 3:33 PM Abdelilah CHOUKRI > >> <[hidden email] > <mailto:[hidden email]> > >> <mailto:[hidden email] > <mailto:[hidden email]>>> wrote: > >> > >> Hi, > >> > >> We're trying to use Flink 1.11 Java tables API to > process a > >> streaming use case: > >> > >> We have 2 streams, each one with different > structures. Both > >> events, coming from Kafka, can be: > >> - A new event (not in the system already) > >> - An updated event (updating an event that > previously was > >> inserted) > >> so we only want to store the latest data in the Table. > >> > >> We need to join the 2 previous Tables to have > all this data > >> stored in the Flink system. We think that the best > way is to > >> store joined data as a Table. > >> This is going to be a Flink Table, that will be a > join of the 2 > >> tables by a common key. > >> > >> To sum up, we have: > >> - Stream 1 (coming from Kafka topic) -> Flink Table 1 > >> - Stream 2 (coming from Kafka topic) -> Flink Table 2 > >> - Table 3 = Table 1 join Table 2 > >> - DataStream using RetractStream of Table 3 > >> > >> To get the last element in Table 1 and Table 2, we > are using > >> Functions (LastValueAggFunction): > >> > >> > streamTableEnvironment.registerFunction("LAST_VALUE_STRING", > >> new LastValueAggFunction.StringLastValueAggFunction()); > >> ... > >> streamTableEnvironment.fromDataStream(inputDataStream) > >> .groupBy($("id")) > >> .select( > >> $("id").as("o_id"), > >> call("LAST_VALUE_STRING", $("title")).as("o_title"), > >> call("LAST_VALUE_STRING", > $("description")).as("o_description") > >> ); > >> > >> > >> The questions are: > >> - Is our approach correct to get the data stored in > the Flink > >> system? > >> - Is it necessary to use the _/LastValueAggFunction > /_in our > >> case ? as we want to retract the stream to > >> out custom Pojo instead of _/Row/_, but we're > getting the > >> attached error: (attached*: stack_trace.log*) > >> > >> > >> Abdelilah Choukdi, > >> Backend dev at ManoMano. > >> > > > |
«
Return to (DEPRECATED) Apache Flink User Mailing List archive.
|
1 view|%1 views
| Free forum by Nabble | Edit this page |