JobManager not receiving resource offers from Mesos

JobManager not receiving resource offers from Mesos

|
Hi,
I try to launch a Flink cluster on top of dc/os but TaskManagers are not launched at all. What I do to launch a Flink cluster is as follows: - Click "flink" from "Catalog" on the left panel of dc/os GUI. - Click "Run service" without any modification on configuration for the purpose of testing (Figure 1). Until now, everything seems okay as shown in Figure 2. However, Figure 3 shows that TaskManager has never been launched. So I take a look at JobManager log (see the attached "log.txt" for full log). LaunchCoordinator is spitting the same log messages while staying in "GetheringOffers" state as follows: INFO org.apache.flink.mesos.scheduler.LaunchCoordinator - Processing 1 task(s) against 0 new offer(s) plus outstanding off$ DEBUG com.netflix.fenzo.TaskScheduler - Found 0 VMs with non-zero offers to assign from INFO org.apache.flink.mesos.scheduler.LaunchCoordinator - Resources considered: (note: expired offers not deducted from be$ DEBUG org.apache.flink.mesos.scheduler.LaunchCoordinator - SchedulingResult{resultMap={}, failures={}, leasesAdded=0, lease$ INFO org.apache.flink.mesos.scheduler.LaunchCoordinator - Waiting for more offers; 1 task(s) are not yet launched. (FYI, ConnectionMonitor is in its "ConnectedState" as you can see in the full log file.) Can anyone point out what's going wrong on my dc/os installation? Thanks you for attention. I'm really looking forward to running Flink clusters on dc/os :-) p.s. I tested whether dc/os is working correctly by using the following scripts and it works. |
Re: JobManager not receiving resource offers from Mesos
|
|
Oops, I forgot to include files in the previous mail.
|
Re: JobManager not receiving resource offers from Mesos
|
|
Hi,
did you see this exception right at the head of your log? java.io.IOException: HADOOP_HOME or hadoop.home.dir are not set. at org.apache.hadoop.util.Shell.checkHadoopHome(Shell.java:265) at org.apache.hadoop.util.Shell.<clinit>(Shell.java:290) at org.apache.hadoop.util.StringUtils.<clinit>(StringUtils.java:76) at org.apache.hadoop.security.Groups.parseStaticMapping(Groups.java:93) at org.apache.hadoop.security.Groups.<init>(Groups.java:77) at org.apache.hadoop.security.Groups.getUserToGroupsMappingService(Groups.java:240) at org.apache.hadoop.security.UserGroupInformation.initialize(UserGroupInformation.java:255) at org.apache.hadoop.security.UserGroupInformation.ensureInitialized(UserGroupInformation.java:232) at org.apache.hadoop.security.UserGroupInformation.loginUserFromSubject(UserGroupInformation.java:718) at org.apache.hadoop.security.UserGroupInformation.getLoginUser(UserGroupInformation.java:703) at org.apache.hadoop.security.UserGroupInformation.getCurrentUser(UserGroupInformation.java:605) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:498) at org.apache.flink.runtime.util.EnvironmentInformation.getHadoopUser(EnvironmentInformation.java:96) at org.apache.flink.runtime.util.EnvironmentInformation.logEnvironmentInfo(EnvironmentInformation.java:285) at org.apache.flink.mesos.runtime.clusterframework.MesosApplicationMasterRunner.main(MesosApplicationMasterRunner.java:131) I think you forgot to configure the HADOOP_HOME properly. Does that solve your problem? Best, Stefan
|
Re: JobManager not receiving resource offers from Mesos
|
|
Hi Stefan,
I don't want to introduce Hadoop in Flink clusters.
I think the exception is not that serious as it is shown only when log-level is set to DEBUG. Do I have to set HADOOP_HOME to use Flink on dc/os? Regards, Dongwon
|
Re: JobManager not receiving resource offers from Mesos
|
|
Hi Till,
I have enough cpu and memory to have a single task manager. I did a simple test by launching additional 8 tasks while Flink JobManager is still waiting for the Mesos master to send resource offers.
Below you can see that 9 tasks are being executed: 1 for Flink JobManager and 8 for the above simple-gpu-test. 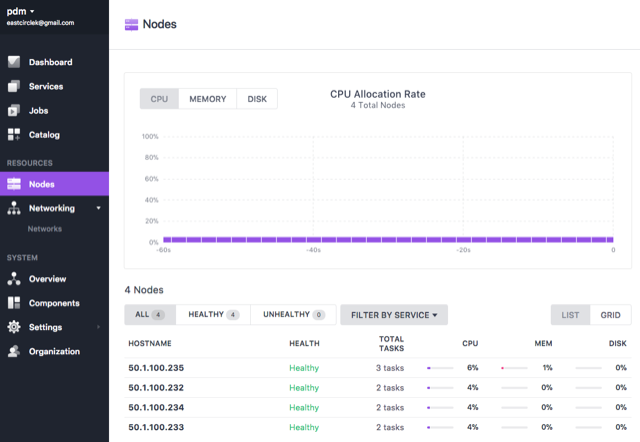 What I suspect at the moment is the Mesos master, especially the hierarchical allocator (the default allocation module inside the Mesos master). AFAIK the allocator tries to prepare resource offers after it gets REVIVE call from any Mesos framework (Flink in this case). While preparing offers, the allocator seems to ignore the Flink framework due to a certain condition about which I have no idea. Take a look at the below log messages from the Mesos master (when it gets REVIVE call from Flink JobManager). FYI, 5865e700-bd58-4b24-b906-5658c364e45a-0001 is the Marathon framework and 5865e700-bd58-4b24-b906-5658c364e45a-0014 is the Flink framework. ----- I0104 09:06:54.000000 23302 master.cpp:5225] Processing REVIVE call for framework 5865e700-bd58-4b24-b906-5658c364e45a-0014 (Flink) at [hidden email]:15656 I0104 09:06:54.000000 23302 process.cpp:3270] Resuming hierarchical-allocator(1)@50.1.100.231:5050 at 2018-01-04 00:06:54.710612992+00:00 I0104 09:06:54.000000 23302 hierarchical.cpp:1290] Revived offers for roles { * } of framework 5865e700-bd58-4b24-b906-5658c364e45a-0014 I0104 09:06:54.000000 23302 hierarchical.cpp:2173] Filtered offer with gpus:2; ports:[1025-2180, 2182-3887, 3889-5049, 5052-8079, 8082-8180, 8182-32000]; disk:205900; cpus:48; mem:127634 on agent 5865e700-bd58-4b24-b906-5658c364e45a-S0 for role slave_public of framework 5865e700-bd58-4b24-b906-5658c364e45a-0001 I0104 09:06:54.000000 23302 hierarchical.cpp:2173] Filtered offer with gpus:2; ports:[1025-2180, 2182-3887, 3889-5049, 5052-8079, 8082-8180, 8182-32000]; disk:197491; cpus:48; mem:127634 on agent 5865e700-bd58-4b24-b906-5658c364e45a-S2 for role slave_public of framework 5865e700-bd58-4b24-b906-5658c364e45a-0001 I0104 09:06:54.000000 23302 hierarchical.cpp:2173] Filtered offer with gpus:2; ports:[1025-2180, 2182-3887, 3889-5049, 5052-8079, 8082-8180, 8182-15651, 15657-32000]; disk:197666; cpus:47; mem:126610 on agent 5865e700-bd58-4b24-b906-5658c364e45a-S3 for role slave_public of framework 5865e700-bd58-4b24-b906-5658c364e45a-0001 I0104 09:06:54.000000 23302 hierarchical.cpp:2173] Filtered offer with gpus:2; ports:[1025-2180, 2182-3887, 3889-5049, 5052-8079, 8082-8180, 8182-32000]; disk:199128; cpus:48; mem:127634 on agent 5865e700-bd58-4b24-b906-5658c364e45a-S1 for role slave_public of framework 5865e700-bd58-4b24-b906-5658c364e45a-0001 I0104 09:06:54.000000 23302 hierarchical.cpp:1925] No allocations performed I0104 09:06:54.000000 23302 hierarchical.cpp:2015] No inverse offers to send out! I0104 09:06:54.000000 23302 hierarchical.cpp:1468] Performed allocation for 4 agents in 587159ns ----- As you can see, the allocation module just shows why the Marathon framework is filtered out, not why the Flink framework gets no offer. If things were going smoothly, the following line of code from the hierarchical allocation module should have been executed: VLOG(2) << "Allocating " << resources << " on agent " << slaveId << " to role " << role << " of framework " << frameworkId << " as part of its role quota"; As I'm quite new to dc/os and Mesos, I just read log messages from JobManager and Mesos Master and Mesos source code. I would appreciate it greatly if you could let me know how to cope with such a situation when playing with dc/os and Mesos. Best, Dongwon
|
Re: JobManager not receiving resource offers from Mesos
|
|
Hi Till,
The problem seems more related to resources (GPUs) than framework roles. The cluster I'm working on consists of servers all equipped with GPUs. When DC/OS is installed, a GPU-specific configuration parameter named "gpus_are_scarce" parameter is enabled by default, which means DC/OS reserves GPU nodes exclusively for services that are configured to consume GPU resources (https://docs.mesosphere.com/1.10/deploying-services/gpu/). Therefore, when I executed Flink without specifying to use GPUs, the hierarchical allocator has to exclude all GPUs servers from candidates. Unfortunately, all servers that we use for Mesos agents have GPUs. Your first guess was somewhat correct! It's because of GPU resources. Now the problem is how to specify to use GPUs when launching Flink clusters. However, as you can see below, there's no room for specifying to make TaskManagers get allocated GPUs. It would be great to have a form to specify how much GPUs is necessary for each instance of TaskManager. 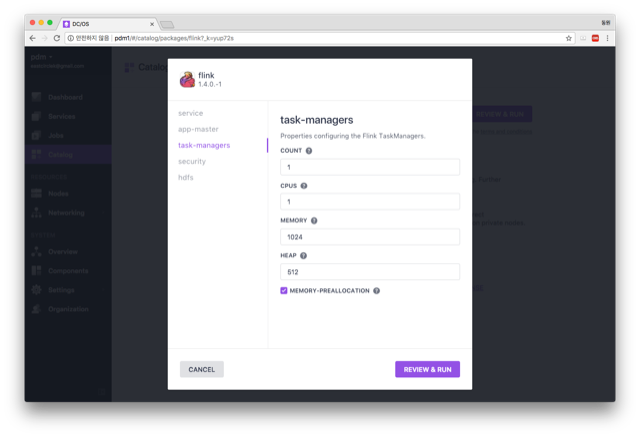 Best, Dongwon
|
Re: JobManager not receiving resource offers from Mesos
|
|
Hi Till,
Currently I'm doing as you said for the purpose of testing. So that's not a big deal at this moment. But I hope it will be supported in Flink sooner or later as we're going to adopt Flink on a very large cluster in which GPU resources are very scarce. Anyway thank you for your attention! Best, Dongwon
|
«
Return to (DEPRECATED) Apache Flink User Mailing List archive.
|
1 view|%1 views
| Free forum by Nabble | Edit this page |