Is it possible to do state migration with checkpoints?

Is it possible to do state migration with checkpoints?

|
Hi,
We are trying out state schema migration for one of our stateful pipelines. We use few Avro type states. Changes made to the job: 1. Updated the schema for one of the states (added a new 'boolean' field with default value). 2. Modified the code by removing a couple of ValueStates. To push these changes, I stopped the live job and resubmitted the new jar with the latest *checkpoint* path. However, the job failed with the following error: java.lang.RuntimeException: Error while getting state at org.apache.flink.runtime.state.DefaultKeyedStateStore.getState(DefaultKeyedStateStore.java:62) at org.apache.flink.streaming.api.operators.StreamingRuntimeContext.getState(StreamingRuntimeContext.java:144) ... ... Caused by: org.apache.flink.util.StateMigrationException: The new state serializer cannot be incompatible. at org.apache.flink.contrib.streaming.state.RocksDBKeyedStateBackend.updateRestoredStateMetaInfo(RocksDBKeyedStateBackend.java:543) at org.apache.flink.contrib.streaming.state.RocksDBKeyedStateBackend.tryRegisterKvStateInformation(RocksDBKeyedStateBackend.java:491) at org.apache.flink.contrib.streaming.state.RocksDBKeyedStateBackend.createInternalState(RocksDBKeyedStateBackend.java:652) I was going through the state schema evolution doc. The document mentions that we need to take a *savepoint* and restart the job with the savepoint path. We are using RocksDB backend with incremental checkpoint enabled. Can we not use the latest checkpoint available when we are dealing with state schema changes? Complete stacktrace is attached with this mail. - Sivaprasanna |
Re: Is it possible to do state migration with checkpoints?
|
|
[hidden email] A follow up question. I tried taking a savepoint but the job failed immediately. It happens everytime I take a savepoint. The job is running on a Yarn cluster so it fails with "container running out of memory". The state size averages around 1.2G but also peaks to ~4.5 GB sometimes (please refer to the screenshot below). The job is running with 2GB task manager heap & 2GB task manager managed memory. I increased the managed memory to 6GB assuming the failure has something to do with RocksDB but it failed even with 6GB managed memory. I guess I am missing on some configurations. Can you folks please help me with this? 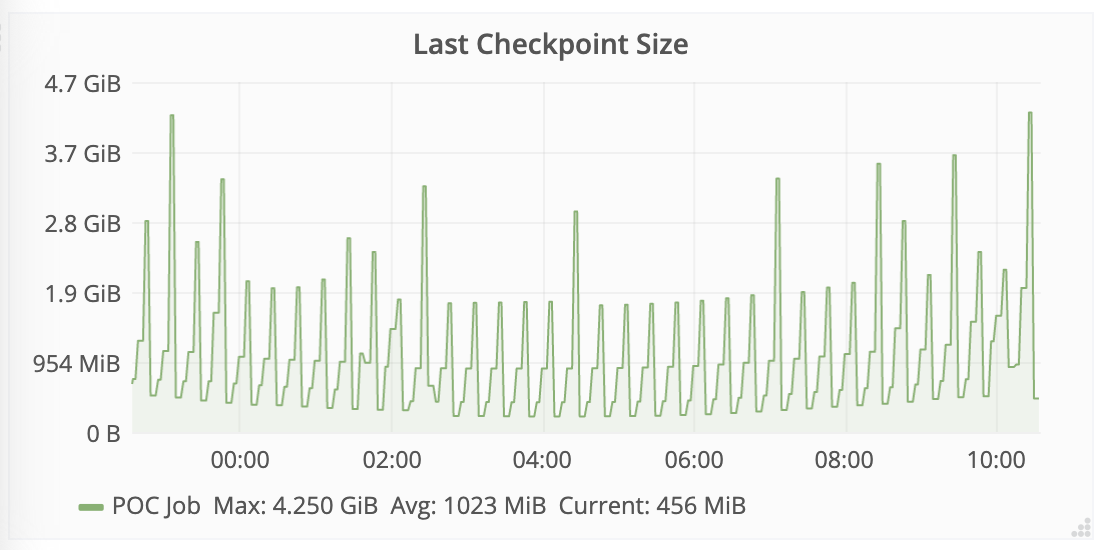 On Wed, Jul 22, 2020 at 7:32 PM Sivaprasanna <[hidden email]> wrote:
|
Re: Is it possible to do state migration with checkpoints?
|
|
Adding dev@ to get some traction. Any help would be greatly appreciated. Thanks. On Thu, Jul 23, 2020 at 11:48 AM Sivaprasanna <[hidden email]> wrote:
|
Re: Is it possible to do state migration with checkpoints?
|
|
In reply to this post by Sivaprasanna
I believe this should work, with a couple of caveats: - You can't do this with unaligned checkpoints - If you have dropped some state, you must specify --allowNonRestoredState when you restart the job David On Wed, Jul 22, 2020 at 4:06 PM Sivaprasanna <[hidden email]> wrote:
|
Re: Is it possible to do state migration with checkpoints?
|
|
Hi David, Thanks for the response. I'm actually specifying --allowNonRestoredState while I submit the job to the yarn session but it still fails with the same error: StateMigrationException: The new state serializer cannot be incompatible. Maybe we cannot resume from incremental checkpoint with state schema changes? BTW, I'm running it on Flink 1.10. I forgot to update it in the original thread. Thanks, Sivaprasanna On Thu, Jul 23, 2020 at 7:52 PM David Anderson <[hidden email]> wrote:
|
Re: Is it possible to do state migration with checkpoints?
|
|
Hi Sivaprasanna I think state schema evolution can work for incremental checkpoint. And I tried with a simple Pojo schema, It also works. maybe you need to check the schema, from the exception stack, the schema before and after are incompatible. Best, Congxian Sivaprasanna <[hidden email]> 于2020年7月24日周五 上午12:06写道:
|
Re: Is it possible to do state migration with checkpoints?
|
|
Thanks, Congxian & David. There was a mistake on the new schema we used. After fixing that, we were able to migrate the state, and since we touched important code blocks, and removed/refactored certain functionalities, we took a savepoint instead of checkpoint. All good now. Thanks again : ) Sivaprasanna On Fri, Jul 24, 2020 at 9:12 AM Congxian Qiu <[hidden email]> wrote:
|
«
Return to (DEPRECATED) Apache Flink User Mailing List archive.
|
1 view|%1 views
| Free forum by Nabble | Edit this page |