Is copying flink-hadoop-compatibility jar to FLINK_HOME/lib the only way to make it work?

Is copying flink-hadoop-compatibility jar to FLINK_HOME/lib the only way to make it work?

|
Hi,
I’m using Flink 1.5.6 and Hadoop 2.7.1.
My requirement is to read hdfs sequence file (SequenceFileInputFormat), then write it back to hdfs (SequenceFileAsBinaryOutputFormat with compression).
Below code won’t work until I copy the flink-hadoop-compatibility jar to FLINK_HOME/lib. I find a similar discussion http://apache-flink-user-mailing-list-archive.2336050.n4.nabble.com/hadoopcompatibility-not-in-dist-td12552.html, do we have any update regarding this, or this is still the only way to get the hadoop compatibility work?
If this is still the only way, do I need to copy that jar to every node of the cluster?
Or, for my SUPER simple requirement above, is there any other way to go? For example, without using flink-hadoop-compatibility?
import org.apache.flink.api.common.functions.FlatMapFunction; import org.apache.flink.api.common.typeinfo.TypeInformation; import org.apache.flink.api.java.ExecutionEnvironment; import org.apache.flink.api.java.hadoop.mapreduce.HadoopOutputFormat; import org.apache.flink.api.java.operators.DataSource; import org.apache.flink.api.java.operators.FlatMapOperator; import org.apache.flink.api.java.tuple.Tuple2; import org.apache.flink.api.java.typeutils.TupleTypeInfo; import org.apache.flink.hadoopcompatibility.HadoopInputs; import org.apache.flink.util.Collector; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.BytesWritable; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.SequenceFile.CompressionType; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.output.SequenceFileAsBinaryOutputFormat; import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import com.twitter.chill.protobuf.ProtobufSerializer;
public class Foobar {
@SuppressWarnings("serial") public static void main(String[] args) throws Exception { ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment(); env.getConfig().registerTypeWithKryoSerializer(ProtobufObject.class, ProtobufSerializer.class);
String path = "hdfs://..."; DataSource<Tuple2<NullWritable, BytesWritable>> input = env.createInput(HadoopInputs.readHadoopFile( new org.apache.hadoop.mapreduce.lib.input.SequenceFileInputFormat<NullWritable, BytesWritable>(), NullWritable.class, BytesWritable.class, path), new TupleTypeInfo<>(TypeInformation.of(NullWritable.class), TypeInformation.of(BytesWritable.class)));
FlatMapOperator<Tuple2<NullWritable, BytesWritable>, Tuple2<BytesWritable, BytesWritable>> x = input.flatMap( new FlatMapFunction<Tuple2<NullWritable, BytesWritable>, Tuple2<BytesWritable, BytesWritable>>() {
@Override public void flatMap(Tuple2<NullWritable, BytesWritable> value, Collector<Tuple2<BytesWritable, BytesWritable>> out) throws Exception { ProtobufObject info = ProtobufObject.parseFrom(value.f1.copyBytes()); String key = info.getKey(); out.collect(new Tuple2<BytesWritable, BytesWritable>(new BytesWritable(key.getBytes()), new BytesWritable(info.toByteArray()))); } });
Job job = Job.getInstance(); HadoopOutputFormat<BytesWritable, BytesWritable> hadoopOF = new HadoopOutputFormat<BytesWritable, BytesWritable>( new SequenceFileAsBinaryOutputFormat(), job);
hadoopOF.getConfiguration().set("mapreduce.output.fileoutputformat.compress", "true"); hadoopOF.getConfiguration().set("mapreduce.output.fileoutputformat.compress.type", CompressionType.BLOCK.toString()); TextOutputFormat.setOutputPath(job, new Path("hdfs://..."));
x.output(hadoopOF); env.execute("foo"); } } |
Re: Is copying flink-hadoop-compatibility jar to FLINK_HOME/lib the only way to make it work?
|
|
Hi, Packaging the flink-hadoop-compatibility dependency with your code into a "fat" job jar should work as well. Best, Fabian Am Mi., 10. Apr. 2019 um 15:08 Uhr schrieb Morven Huang <[hidden email]>:
|
Re: Is copying flink-hadoop-compatibility jar to FLINK_HOME/lib the only way to make it work?
|
|
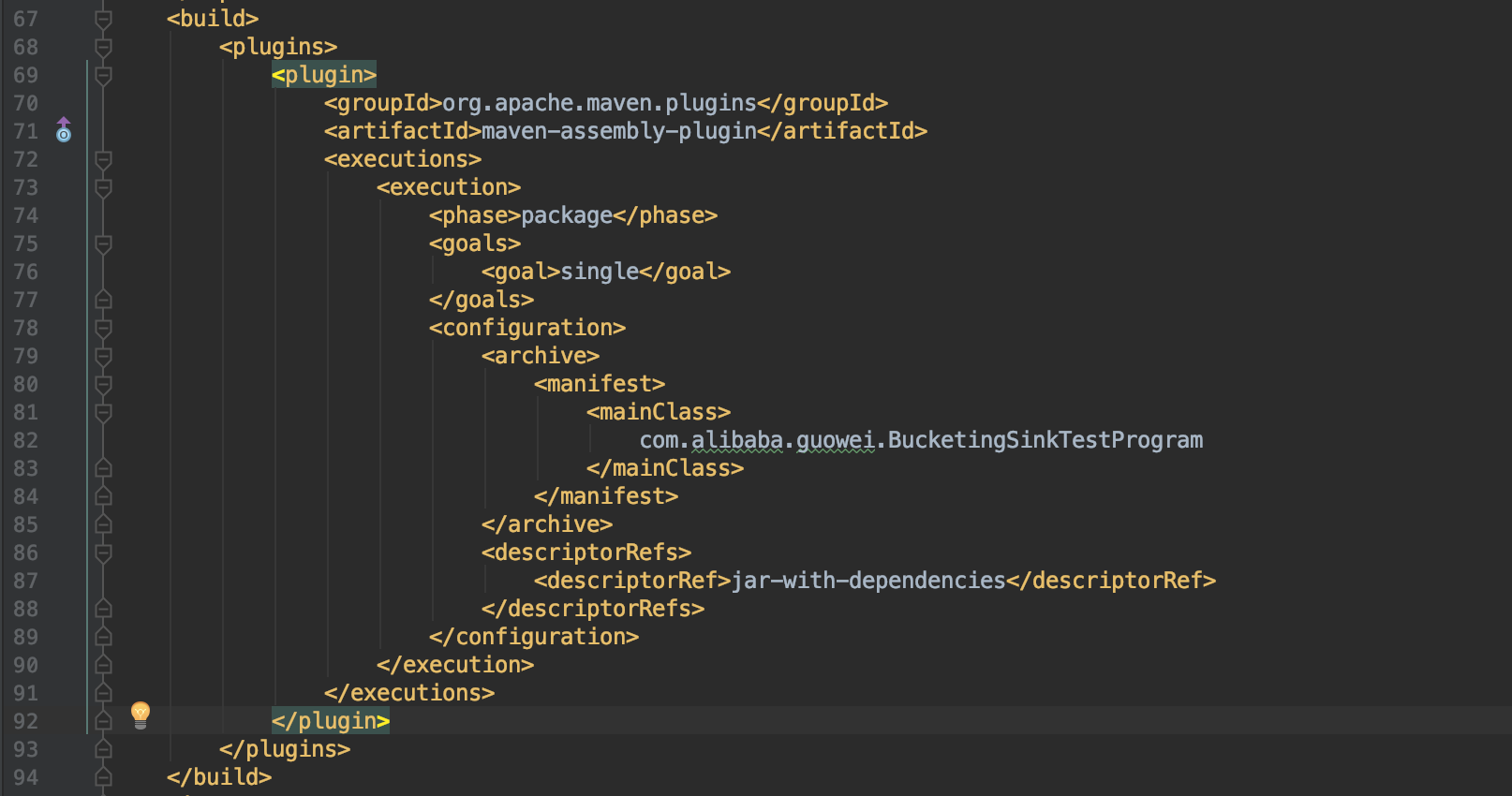
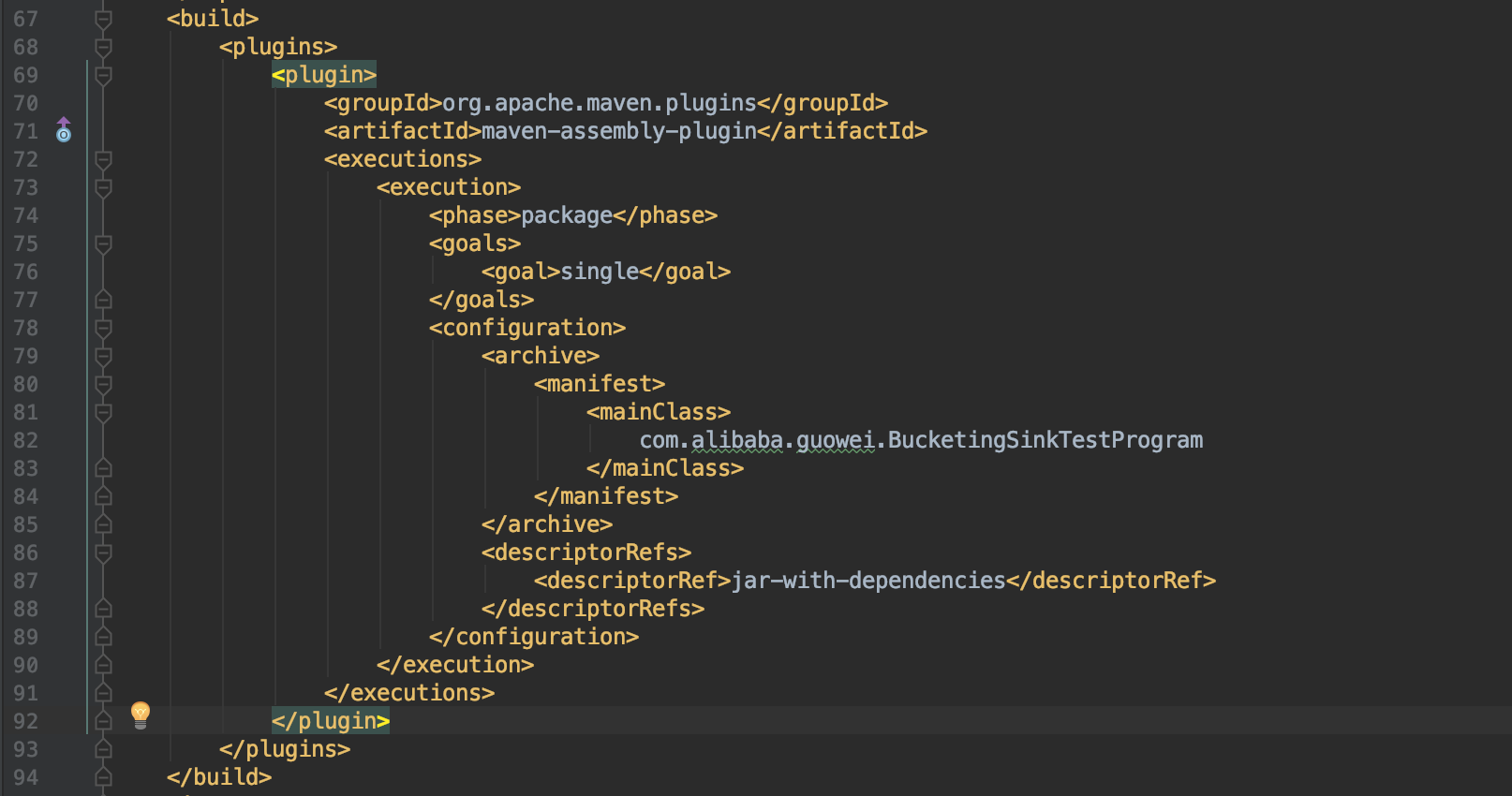
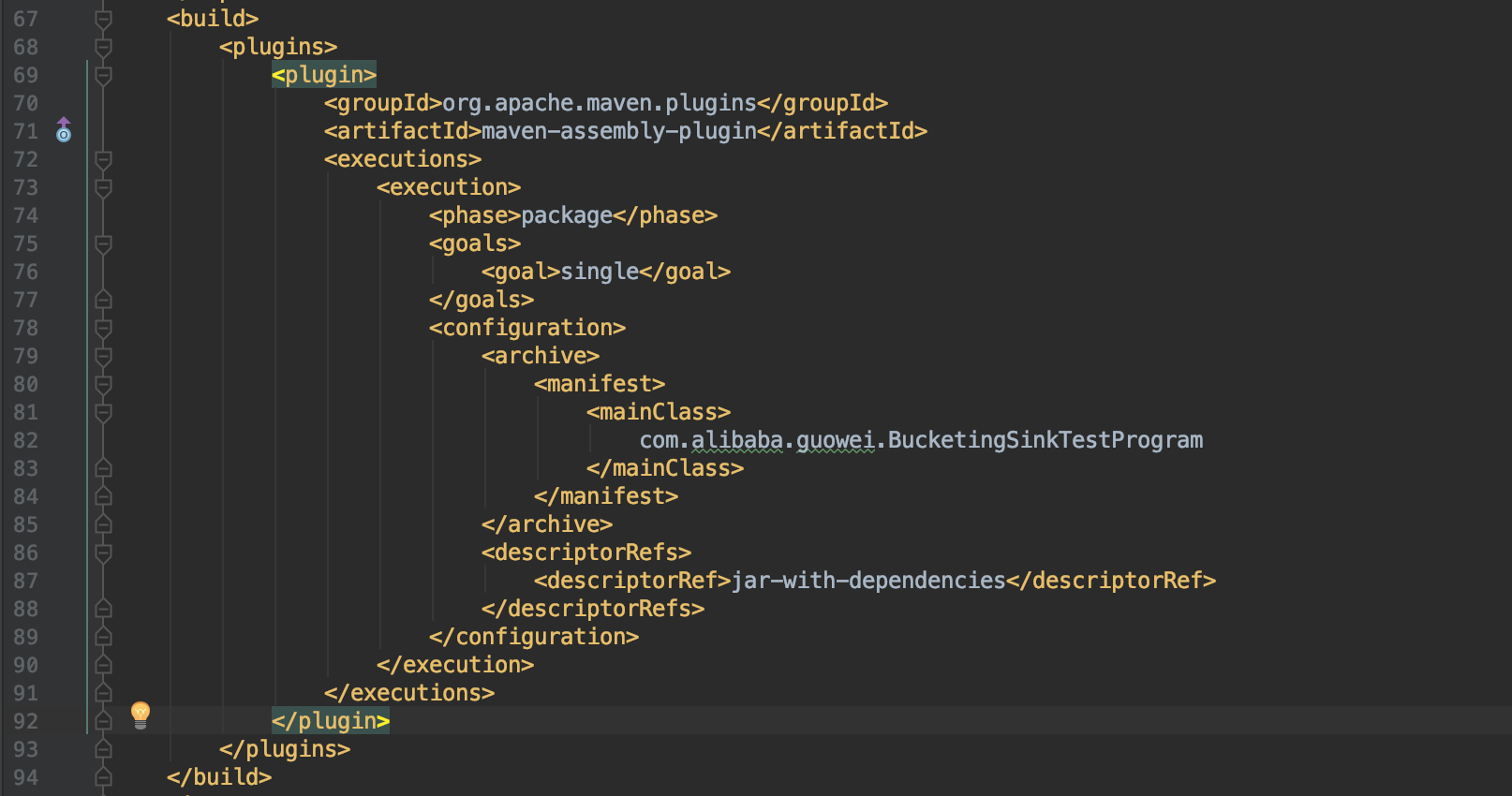
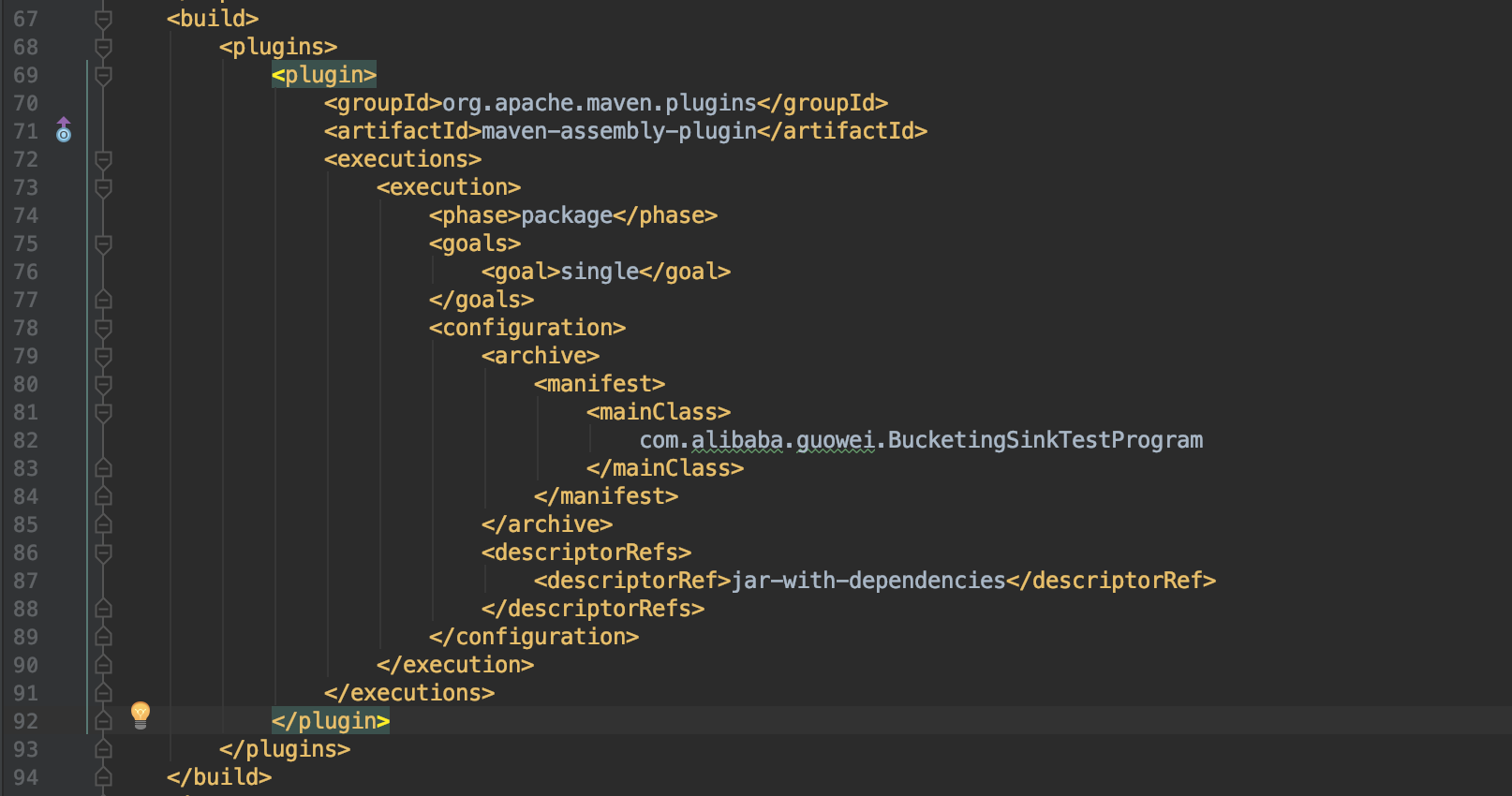
Hi Fabian, Packaging that dependency into a fat jar doesn't help, here is the pom.xml I use, could you please help to take a look if there're some problems? <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" <modelVersion>4.0.0</modelVersion> <groupId>com.misc.flink</groupId> <artifactId>foobar</artifactId> <version>0.0.1-SNAPSHOT</version> <packaging>jar</packaging> <name>foobar</name> <url>http://maven.apache.org</url> <properties> <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> <flink.version>1.5.6</flink.version> <hadoop.version>2.7.1</hadoop.version> <java.version>1.8</java.version> <scala.binary.version>2.11</scala.binary.version> <maven.compiler.source>${java.version}</maven.compiler.source> <maven.compiler.target>${java.version}</maven.compiler.target> </properties> <repositories> <repository> <id>apache.snapshots</id> <name>Apache Development Snapshot Repository</name> <releases> <enabled>false</enabled> </releases> <snapshots> <enabled>true</enabled> </snapshots> </repository> </repositories> <dependencies> <!-- Apache Flink dependencies --> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-java</artifactId> <version>${flink.version}</version> <scope>provided</scope> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-clients_${scala.binary.version}</artifactId> <version>${flink.version}</version> <scope>provided</scope> </dependency> <!-- Different groupId --> <dependency> <groupId>com.esotericsoftware</groupId> <artifactId>kryo</artifactId> <version>3.0.0</version> </dependency> <dependency> <groupId>com.twitter</groupId> <artifactId>chill-protobuf</artifactId> <version>0.7.4</version><!-- 0.5.2 --> </dependency> <dependency> <groupId>com.google.protobuf</groupId> <artifactId>protobuf-java</artifactId> <version>2.5.0</version> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-hadoop-compatibility_${scala.binary.version}</artifactId> <version>${flink.version}</version> </dependency> <!-- Add connector dependencies here. They must be in the default scope (compile). --> <!-- Example: <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-connector-kafka-0.10_${scala.binary.version}</artifactId> <version>${flink.version}</version> </dependency> --> <!-- Add logging framework, to produce console output when running in the IDE. --> <!-- These dependencies are excluded from the application JAR by default. --> <dependency> <groupId>org.slf4j</groupId> <artifactId>slf4j-api</artifactId> <version>1.7.7</version> </dependency> <dependency> <groupId>org.slf4j</groupId> <artifactId>slf4j-log4j12</artifactId> <version>1.7.7</version> <scope>runtime</scope> </dependency> <dependency> <groupId>log4j</groupId> <artifactId>log4j</artifactId> <version>1.2.17</version> <scope>runtime</scope> </dependency> </dependencies> <build> <plugins> <!-- Java Compiler --> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-compiler-plugin</artifactId> <version>3.1</version> <configuration> <source>${java.version}</source> <target>${java.version}</target> </configuration> </plugin> <!-- We use the maven-shade plugin to create a fat jar that contains all necessary dependencies. --> <!-- Change the value of <mainClass>...</mainClass> if your program entry point changes. --> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-shade-plugin</artifactId> <version>3.0.0</version> <executions> <!-- Run shade goal on package phase --> <execution> <phase>package</phase> <goals> <goal>shade</goal> </goals> <configuration> <artifactSet> <excludes> <exclude>org.apache.flink:force-shading</exclude> <exclude>com.google.code.findbugs:jsr305</exclude> <exclude>org.slf4j:*</exclude> <exclude>log4j:*</exclude> </excludes> </artifactSet> <filters> <filter> <!-- Do not copy the signatures in the META-INF folder. Otherwise, this might cause SecurityExceptions when using the JAR. --> <artifact>*:*</artifact> <excludes> <exclude>META-INF/*.SF</exclude> <exclude>META-INF/*.DSA</exclude> <exclude>META-INF/*.RSA</exclude> </excludes> </filter> </filters> <transformers> <transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer"> <mainClass>com.misc.flink.SinkPbHdfsToHdfs</mainClass> </transformer> </transformers> </configuration> </execution> </executions> </plugin> </plugins> <pluginManagement> <plugins> <!-- This improves the out-of-the-box experience in Eclipse by resolving some warnings. --> <plugin> <groupId>org.eclipse.m2e</groupId> <artifactId>lifecycle-mapping</artifactId> <version>1.0.0</version> <configuration> <lifecycleMappingMetadata> <pluginExecutions> <pluginExecution> <pluginExecutionFilter> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-shade-plugin</artifactId> <versionRange>[3.0.0,)</versionRange> <goals> <goal>shade</goal> </goals> </pluginExecutionFilter> <action> <ignore /> </action> </pluginExecution> <pluginExecution> <pluginExecutionFilter> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-compiler-plugin</artifactId> <versionRange>[3.1,)</versionRange> <goals> <goal>testCompile</goal> <goal>compile</goal> </goals> </pluginExecutionFilter> <action> <ignore /> </action> </pluginExecution> </pluginExecutions> </lifecycleMappingMetadata> </configuration> </plugin> </plugins> </pluginManagement> </build> <!-- This profile helps to make things run out of the box in IntelliJ --> <!-- Its adds Flink's core classes to the runtime class path. --> <!-- Otherwise they are missing in IntelliJ, because the dependency is 'provided' --> <profiles> <profile> <id>add-dependencies-for-IDEA</id> <activation> <property> <name>idea.version</name> </property> </activation> <dependencies> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-java</artifactId> <version>${flink.version}</version> <scope>compile</scope> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-streaming-java_${scala.binary.version}</artifactId> <version>${flink.version}</version> <scope>compile</scope> </dependency> </dependencies> </profile> </profiles> </project> On Wed, Apr 10, 2019 at 9:53 PM Fabian Hueske <[hidden email]> wrote:
|
|
|
Hi, 1. You could use the command "jar tf xxx.jar" to see if the class you depended is in the jar.2. AFAIK, you need a maven plugin to package all your dependencies to a fat jar. But I don't find one in your pom.xml. You could add some lines to your pom.xml and have a test. BTW, I think the document of flink might need a tutorial to let user know how to do that. 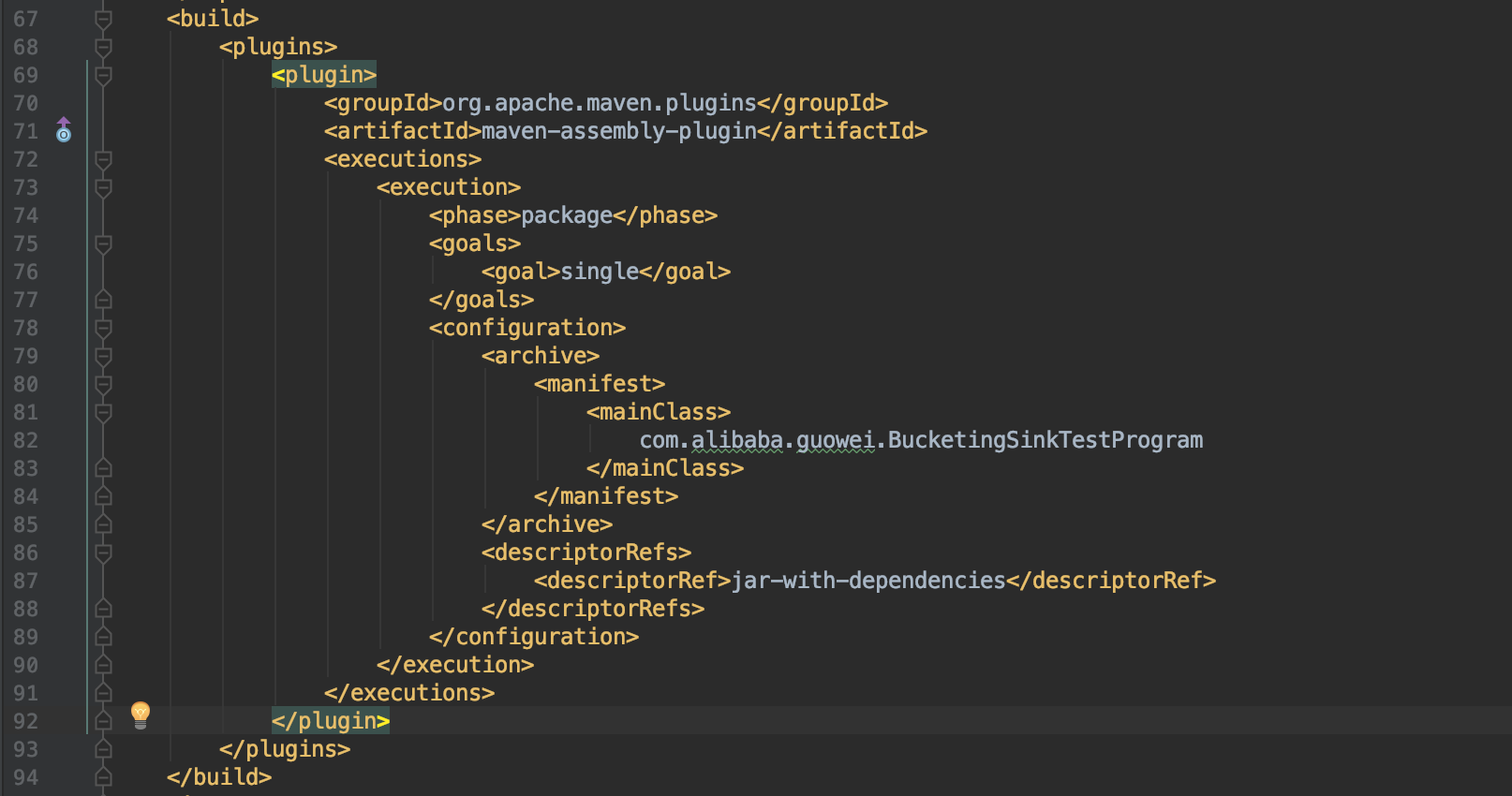 Best, Guowei Morven Huang <[hidden email]> 于2019年4月11日周四 上午10:48写道:
|
Re: Is copying flink-hadoop-compatibility jar to FLINK_HOME/lib the only way to make it work?
|
|
Hi, Many thanks for the help. 1. The error I run into is, 2. I did check the jar using tools like jd-gui, and the class is there, 3. I create that maven project according to the doc https://ci.apache.org/projects/flink/flink-docs-release-1.7/dev/projectsetup/java_api_quickstart.html, and use maven-shade-plugin to package the jar, 4. The error won't go until I move flink-hadoop-compatibility_2.11-1.5.6.jar to FLINK_HOME/lib 5. I'll try maven-assembly-plugin, as you suggested. Best, morven On Thu, Apr 11, 2019 at 1:41 PM Guowei Ma <[hidden email]> wrote:
|
Re: Is copying flink-hadoop-compatibility jar to FLINK_HOME/lib the only way to make it work?
|
|
In reply to this post by Guowei Ma
Using maven-assembly-plugin doesn't help, still same error. On Thu, Apr 11, 2019 at 1:41 PM Guowei Ma <[hidden email]> wrote:
|
Re: Is copying flink-hadoop-compatibility jar to FLINK_HOME/lib the only way to make it work?
|
|
Hi Morven, This looks like a bug to me. The TypeExtractor (method createHadoopWritableTypeInfo(), lines 2077ff) tries to look up the WritableTypeInfo class in the wrong classloader. Class<?> typeInfoClass; When the hadoop-compatibility dependency is bundled in the job JAR file, it is loaded in the usercode classloader, however the TypeExtractor looks only in the system classloader. It works when the hadoop-compatibility JAR is added to the ./lib folder, because everything in ./lib is loaded into the system classloader. Long story short, packaging hadoop-compatibility in your job JAR does not work due to a bug. Would you mind creating a bug in Jira for this issue? Thanks, Fabian Am Do., 11. Apr. 2019 um 09:01 Uhr schrieb Morven Huang <[hidden email]>:
|
Re: Is copying flink-hadoop-compatibility jar to FLINK_HOME/lib the only way to make it work?
|
|
Hi Fabian, Thank you for the help. JIRA has been filed, https://issues.apache.org/jira/browse/FLINK-12163 Best, Morven On Thu, Apr 11, 2019 at 4:27 PM Fabian Hueske <[hidden email]> wrote:
|
| Free forum by Nabble | Edit this page |