Interpretting checkpoint data size

Interpretting checkpoint data size

|
Hello, I have incremental checkpoints turned on and there seems to be no relation at all to how often the job checkpoints and how much data exists. Whether checkpoints are set to every 1 min or every 5 seconds they're still around 5 GB in size and checkpoint times are still in minutes. I would expect that if the system only runs for 5s then it would have significantly less data to checkpoint than if it runs for 1 min. Would someone mind clarifying the meaning of checkpoint data size when incremental checkpoints are turned on? Possibly I'm misinterpreting it. Thank you! -- Rex Fenley | Software Engineer - Mobile and Backend Remind.com | BLOG | FOLLOW US | LIKE US |
Re: Interpretting checkpoint data size
|
|
One thing that did just come to mind is possibly every time I'm submitting a job from a previous checkpoint with different settings, it has to slowly re-checkpoint all the previous data. Which means there would be some warm up time before things functioned in a steady state. Is this possible? On Wed, Jan 13, 2021 at 6:09 PM Rex Fenley <[hidden email]> wrote:
-- Rex Fenley | Software Engineer - Mobile and Backend Remind.com | BLOG | FOLLOW US | LIKE US |
Re: Interpretting checkpoint data size
|
|
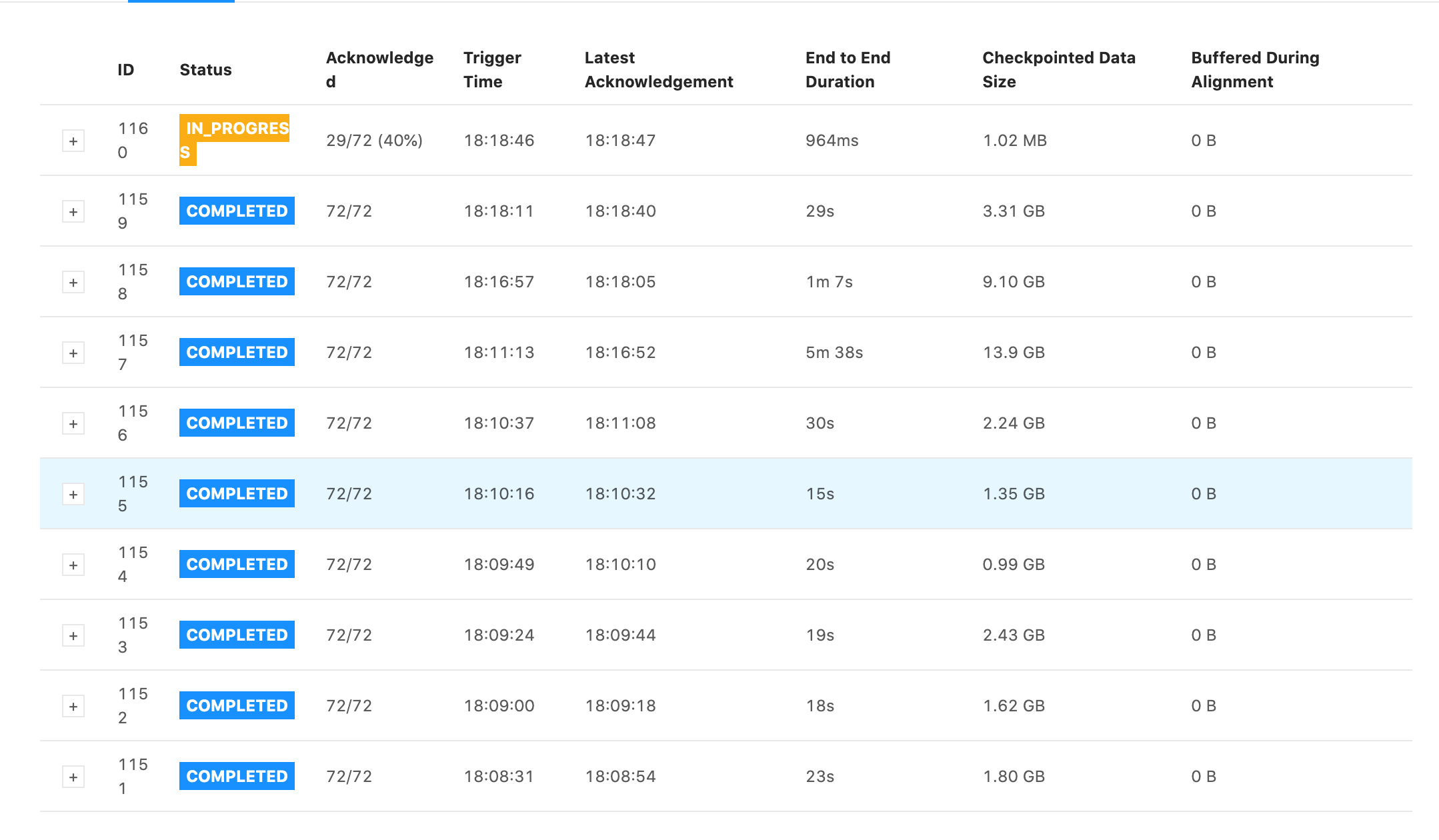
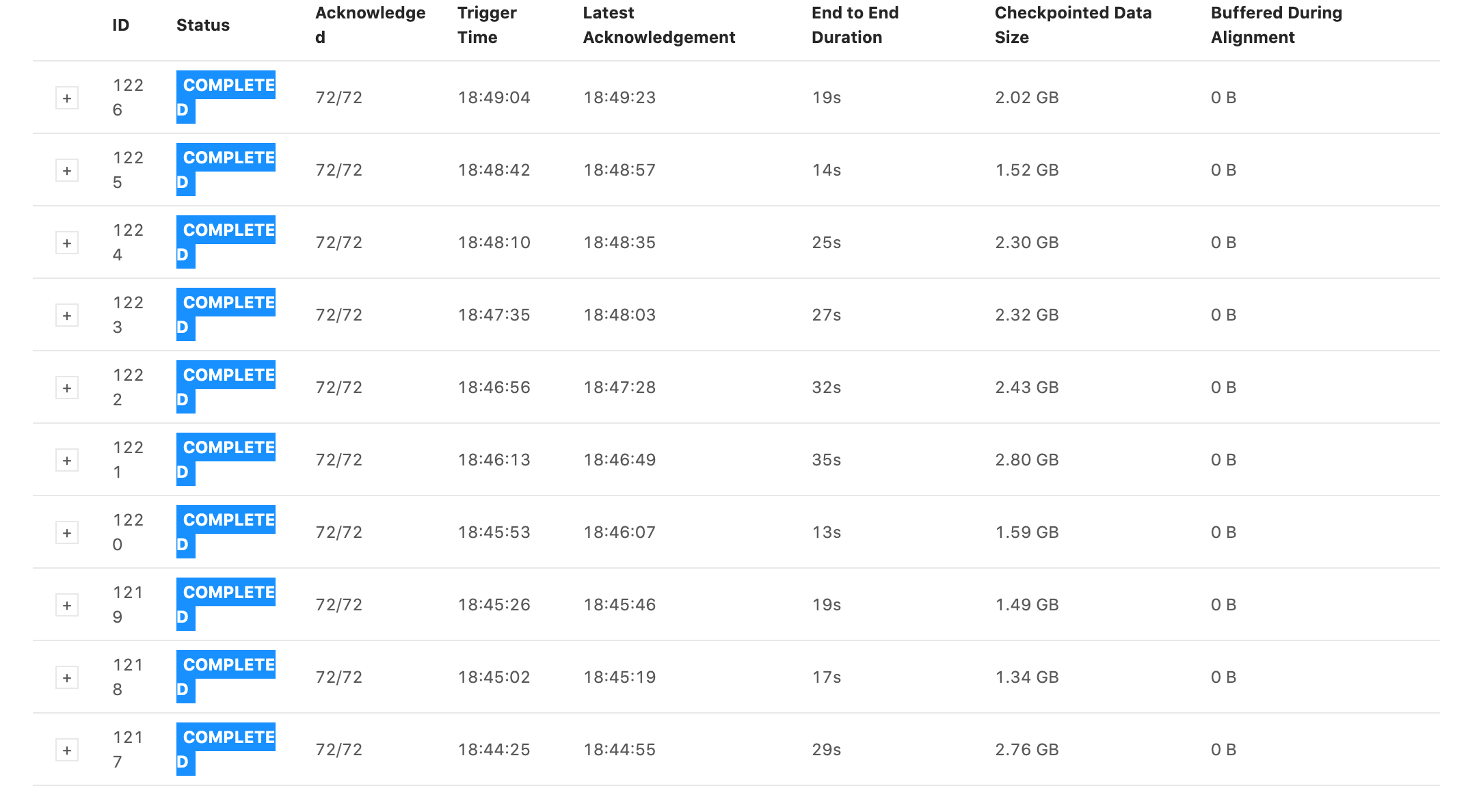
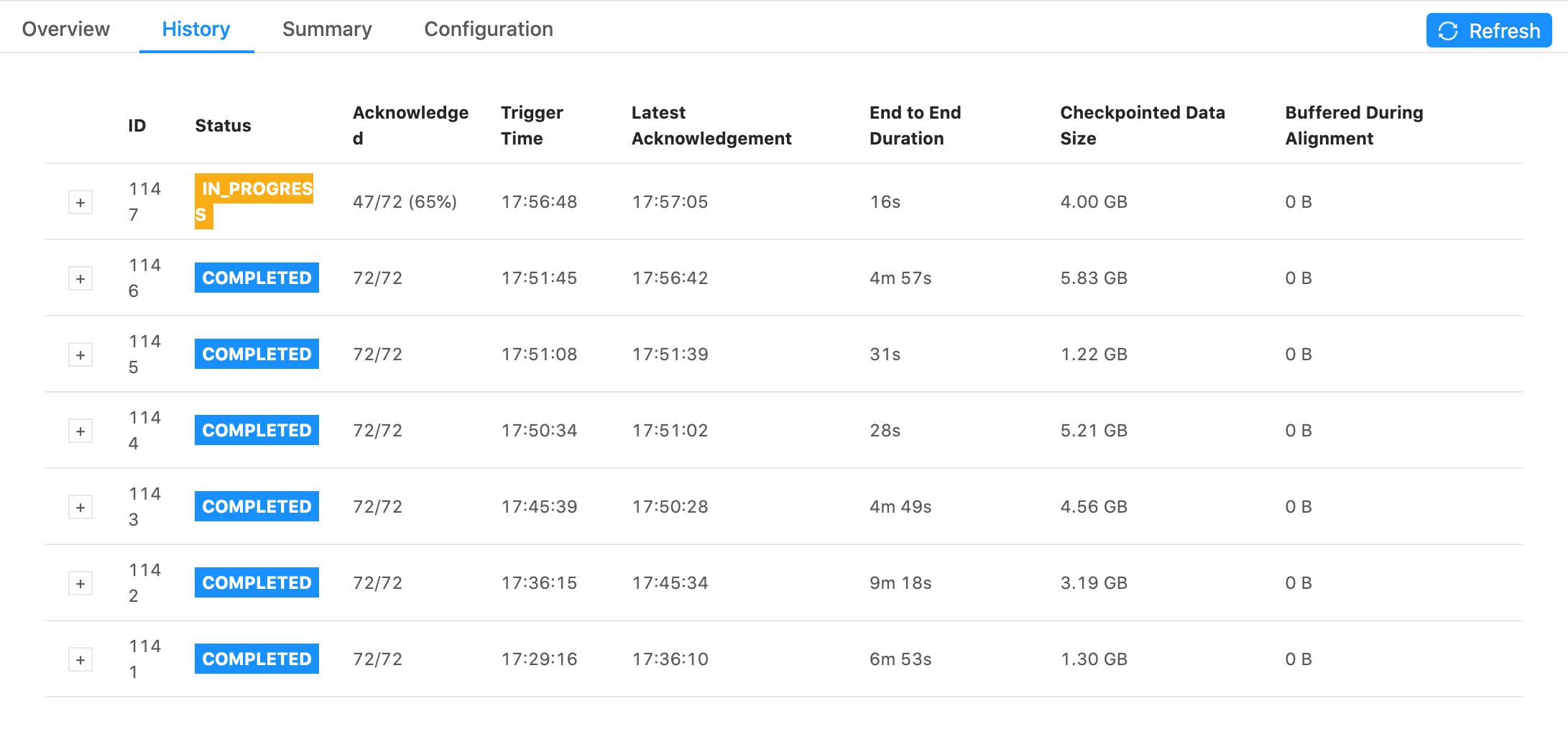
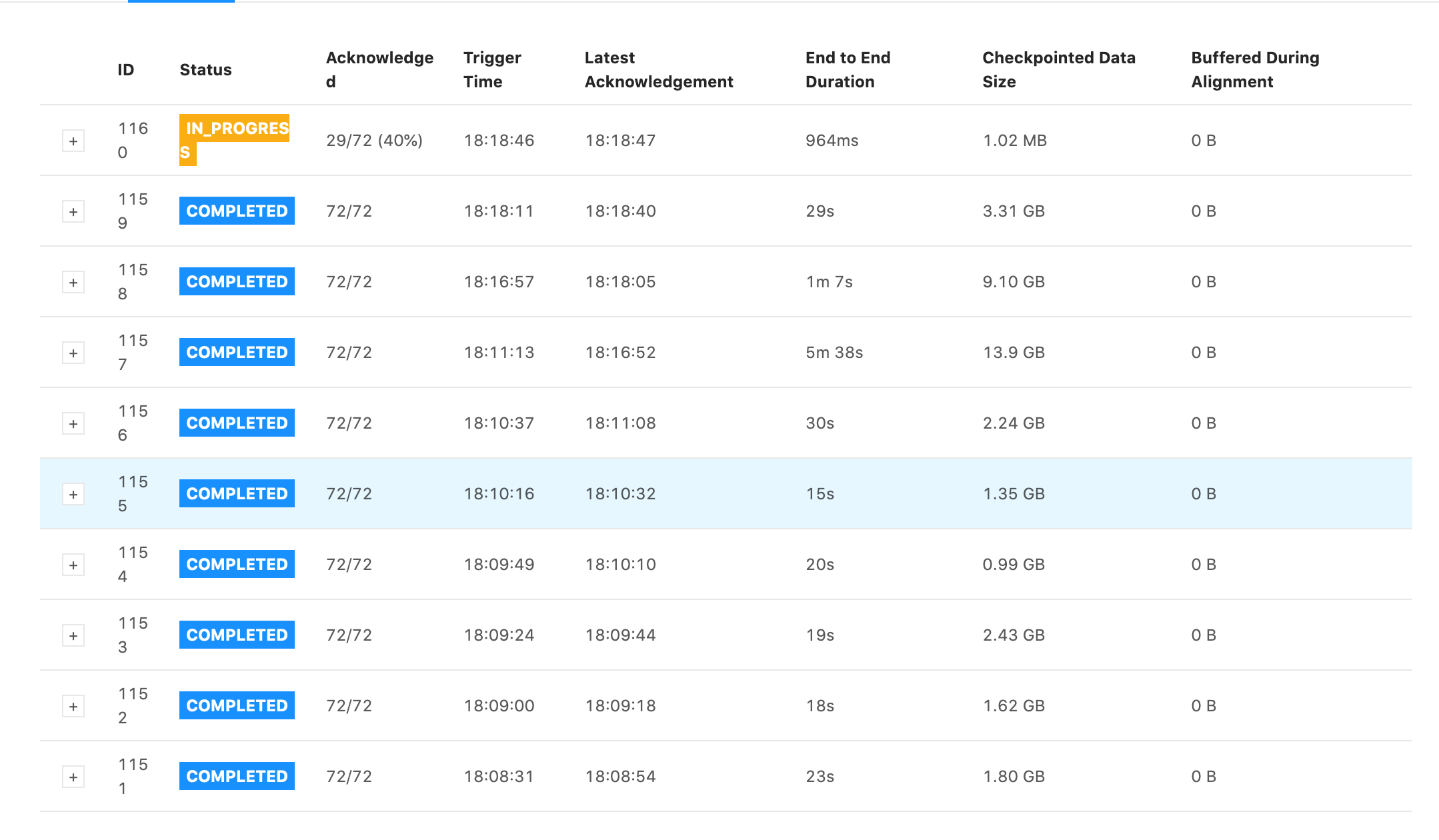
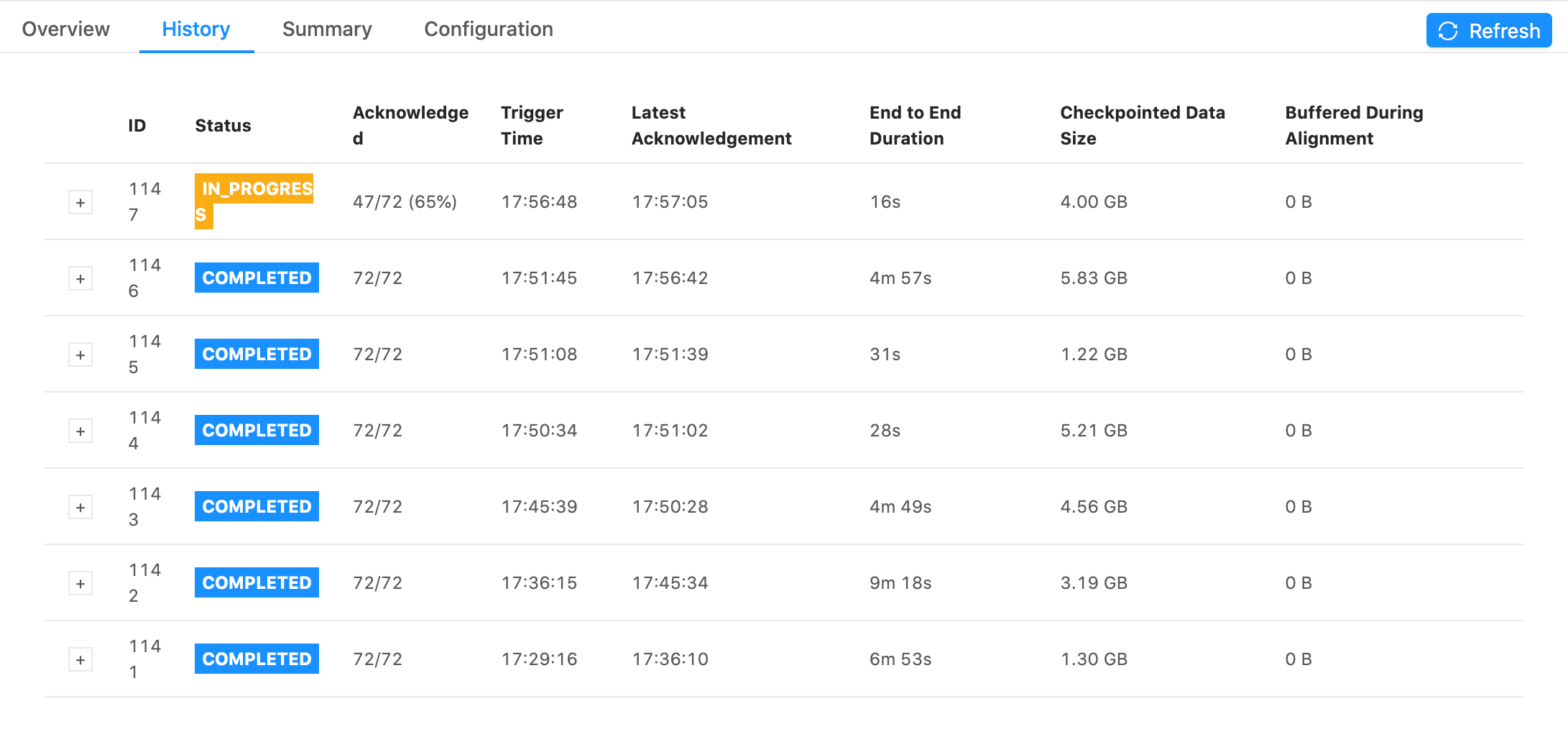
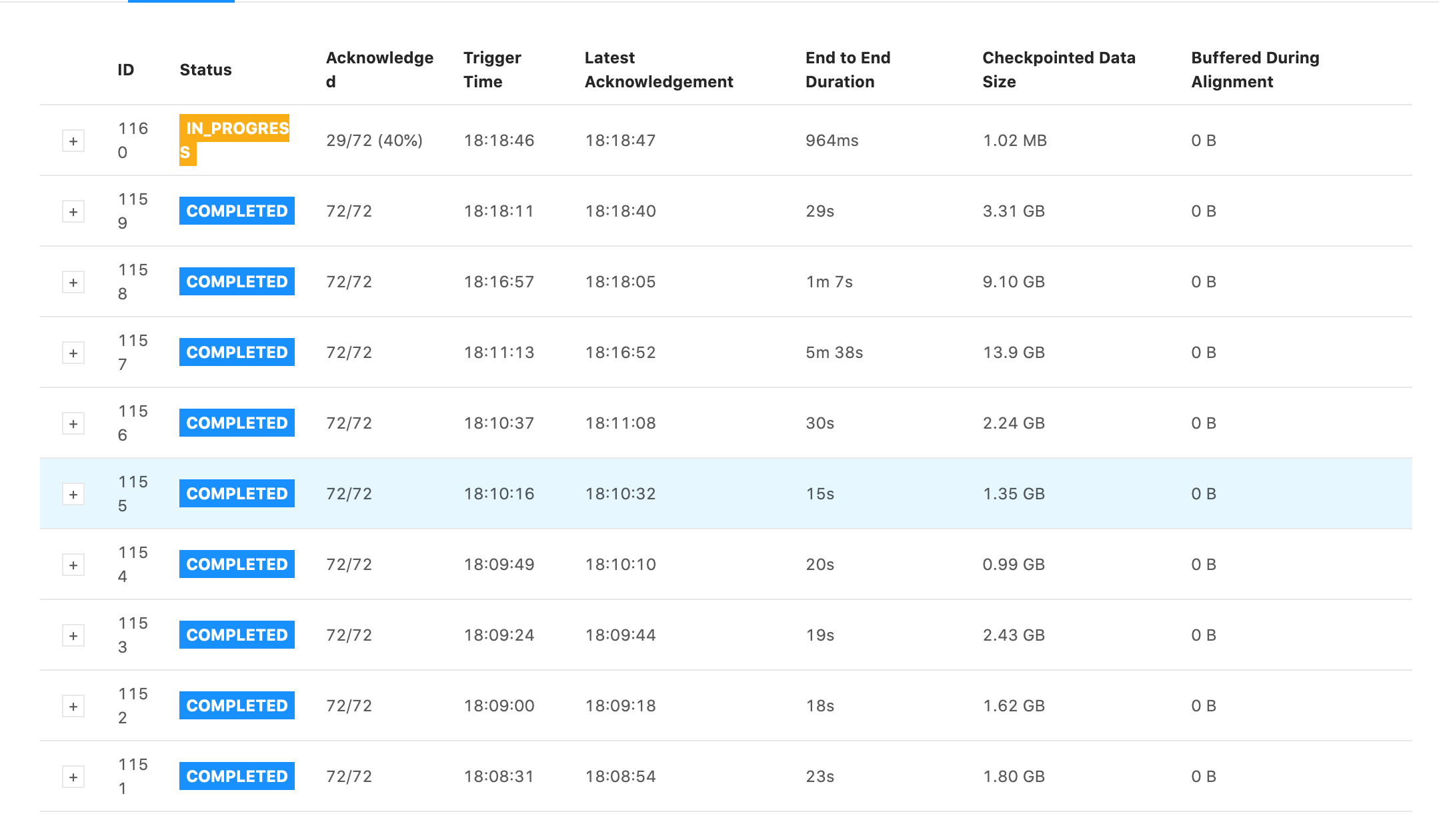
Some snapshots of tests I ran. They all have the same settings for the job except the first one has checkpoints every 1 min with 1 min between checkpoints and the second one has checkpoints every 5s with 5s between checkpoints. Notice that the 5s one has generally faster checkpoint times, but still is in the GB range and still has some checkpoint times within 5 minutes. 1min + 1min 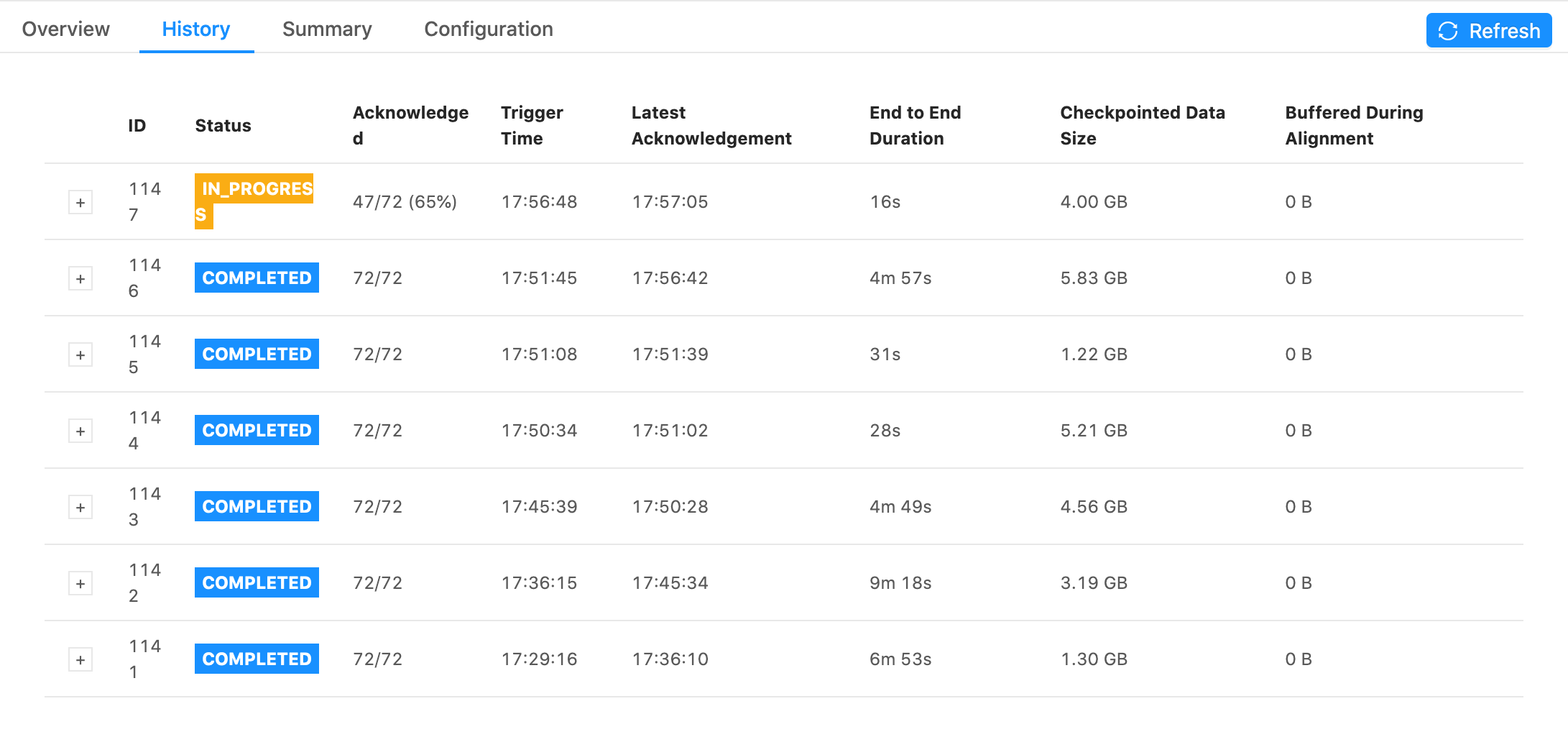 5s + 5s 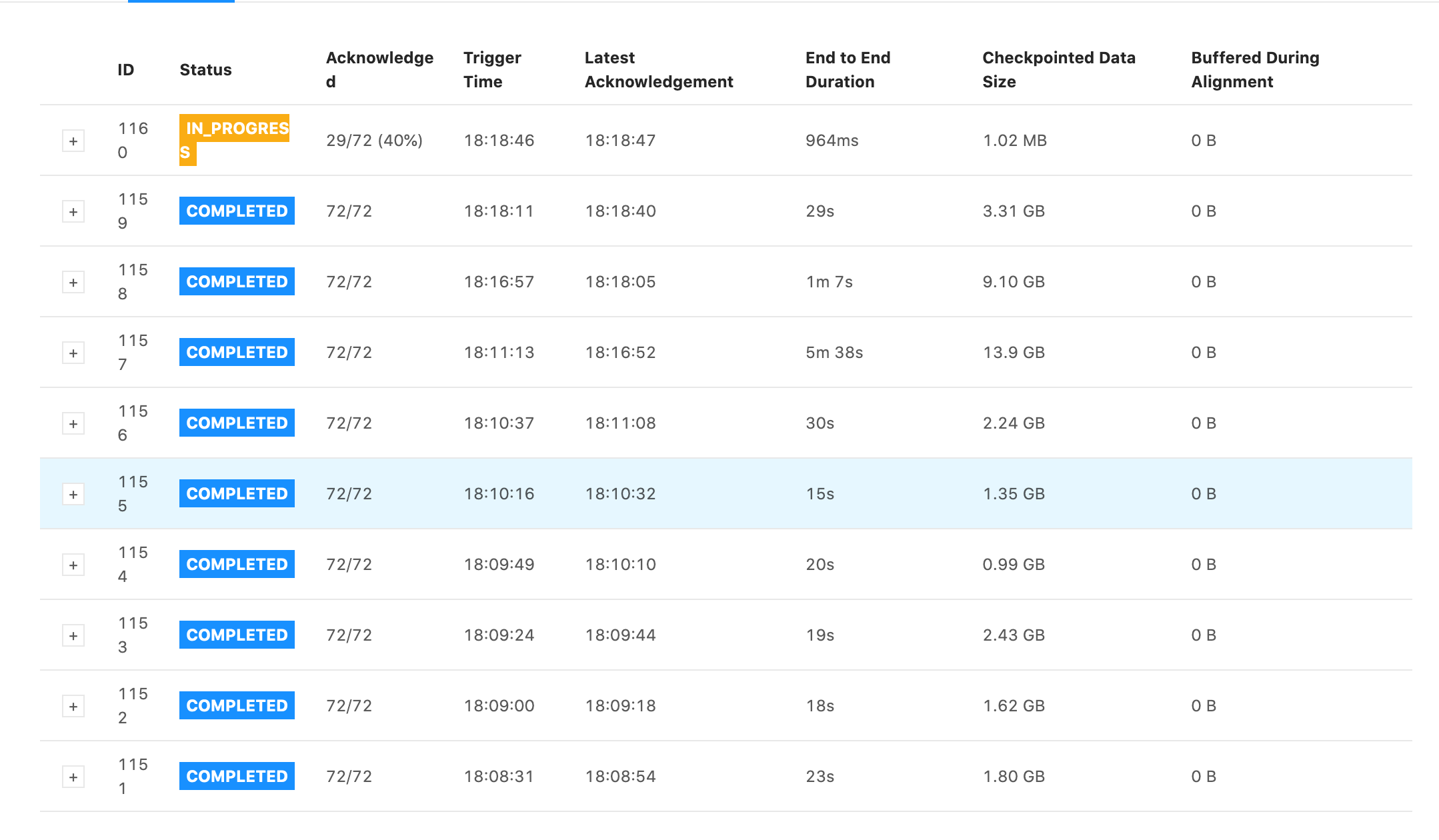 On Wed, Jan 13, 2021 at 6:11 PM Rex Fenley <[hidden email]> wrote:
-- Rex Fenley | Software Engineer - Mobile and Backend Remind.com | BLOG | FOLLOW US | LIKE US |
Re: Interpretting checkpoint data size
|
|
Checkpoint times are now consistently faster on the 5s checkpoint time job, but checkpoint size is still in the GB. I don't understand why this might be. 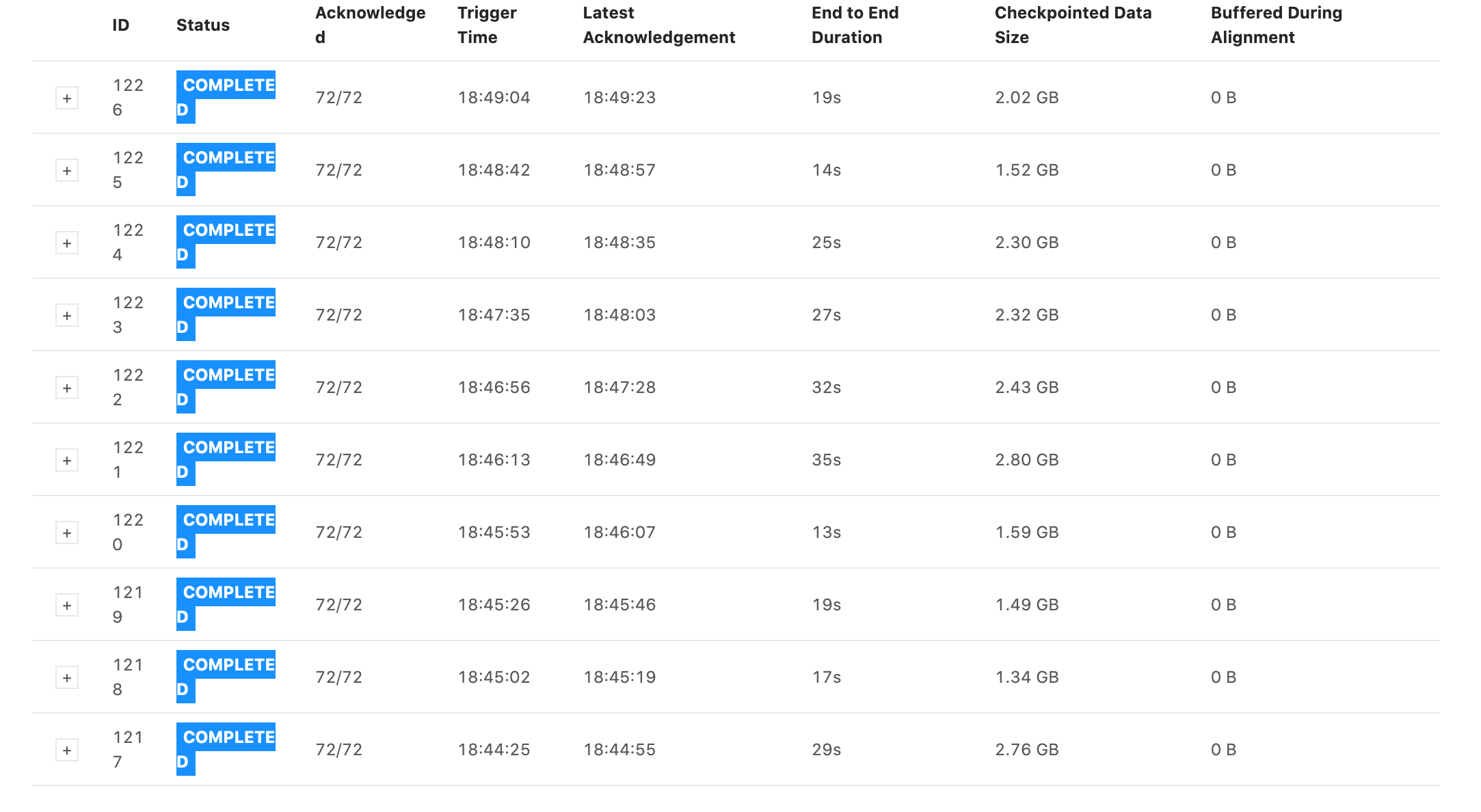 On Wed, Jan 13, 2021 at 6:23 PM Rex Fenley <[hidden email]> wrote:
-- Rex Fenley | Software Engineer - Mobile and Backend Remind.com | BLOG | FOLLOW US | LIKE US |
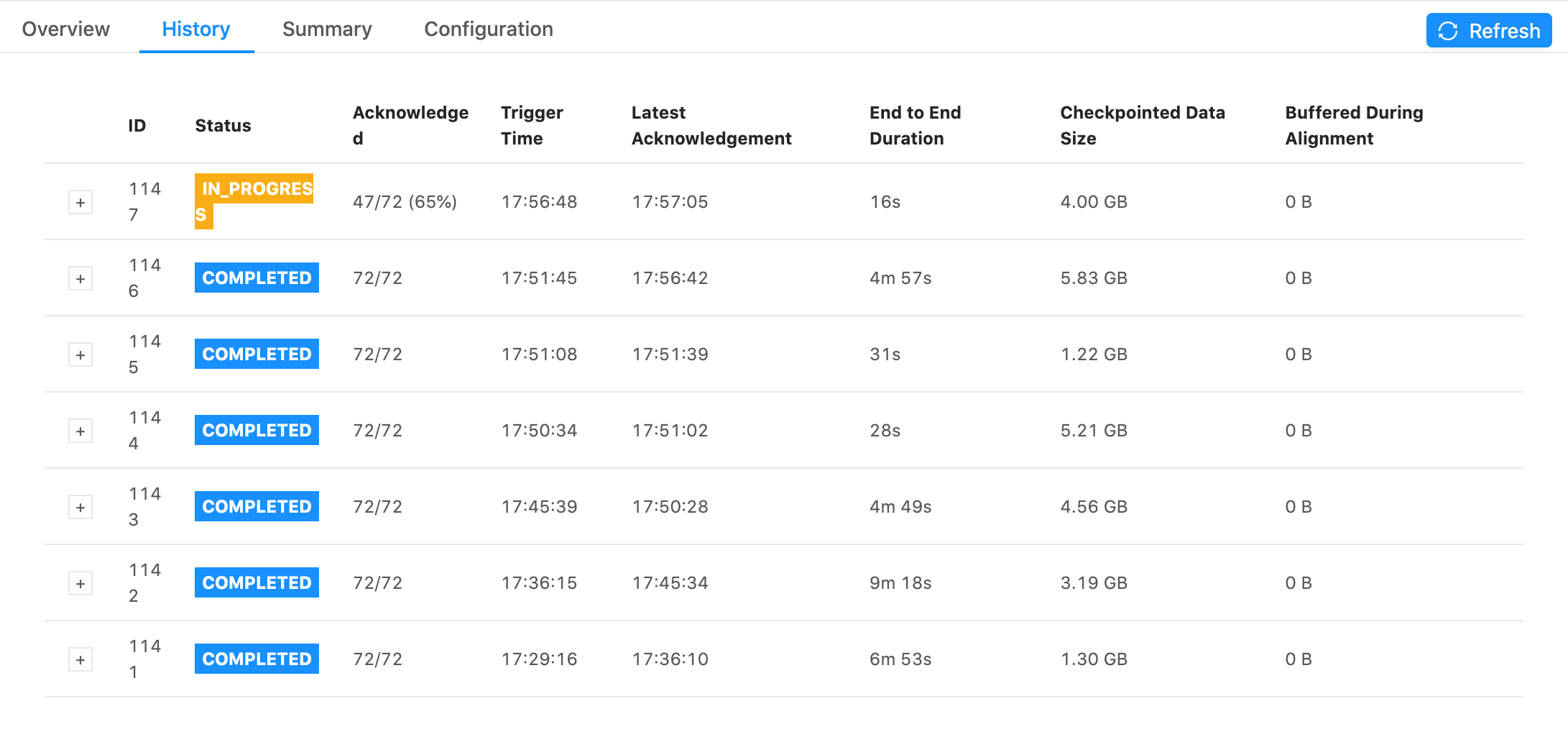
Re: Interpretting checkpoint data size
|
|
Which backend are you using? Incremental checkpoints are only working with rocks db as of now. I do see a difference though between the different settings but still want to make sure. Incremental checkpoints mostly help with cold keys. So if you have very many different user_ids and only a small fraction of active users at the same time, incremental checkpoints would be drastically smaller than full checkpoints. However, if all your keys are changed in between any incremental checkpoint, then you would also need to store the complete state each time. So whether incremental checkpoints are better or not depends very much on the nature of your application. Incremental checkpoints are usually faster as we just need to copy the SST files from rocks db to your checkpoint storage. On Thu, Jan 14, 2021 at 3:53 AM Rex Fenley <[hidden email]> wrote:
-- Arvid Heise | Senior Java Developer Follow us @VervericaData -- Join Flink Forward - The Apache Flink Conference Stream Processing | Event Driven | Real Time -- Ververica GmbH | Invalidenstrasse 115, 10115 Berlin, Germany -- Ververica GmbHRegistered at Amtsgericht Charlottenburg: HRB 158244 B Managing Directors: Timothy Alexander Steinert, Yip Park Tung Jason, Ji (Toni) Cheng |
Re: Interpretting checkpoint data size
|
|
Hello, Thanks for the reply. We are using Rocks and we are materializing documents over a graph. We're seeing millions of mutations a day and given our daily active users I'd guess we're probably changing around 10%-20% of the stateful rows in a given day. In which case incremental checkpoints do sound like the better option, and it also makes sense now stating this why it might be in the GiB range. Thanks for the clarification. Two follow ups though, this is a lot of data to be incrementally increasing over time. Is there any compaction mechanism for the checkpoints? Also, do longer times between checkpoints have proportionally smaller checkpoints? I.e. if a 1min checkpoint time has 1GiB checkpoints then if 2min checkpoints operate over some of the same rows between the first and second minute will you then for 2min have < 2GiB checkpoints (assuming throughput is constant)? Or another way of phrasing this is, does mutating the same state multiple times cause it to collapse to 1 change in an incremental checkpoint or does it store all changes? Thanks On Fri, Jan 15, 2021 at 4:55 AM Arvid Heise <[hidden email]> wrote:
-- Rex Fenley | Software Engineer - Mobile and Backend Remind.com | BLOG | FOLLOW US | LIKE US |
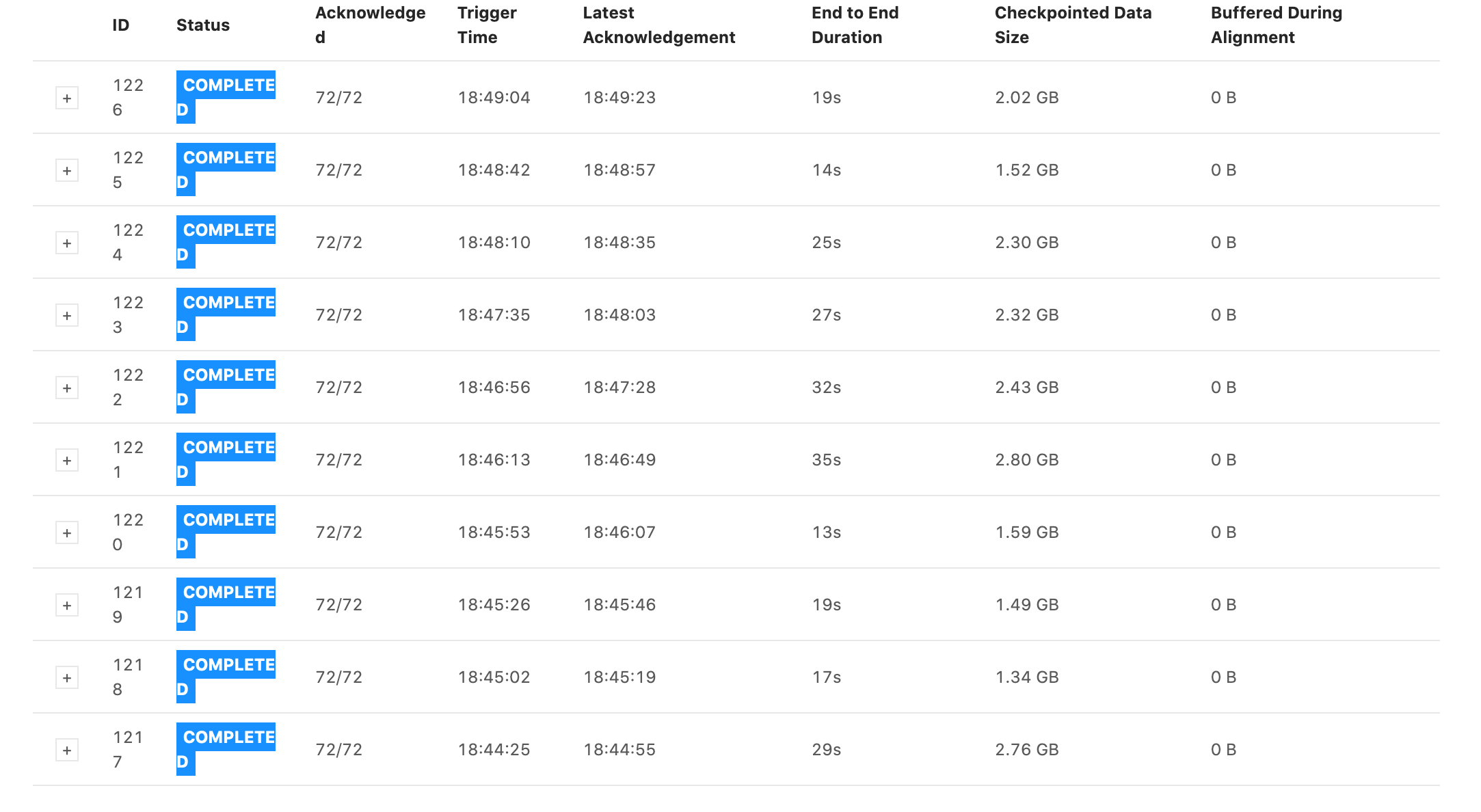
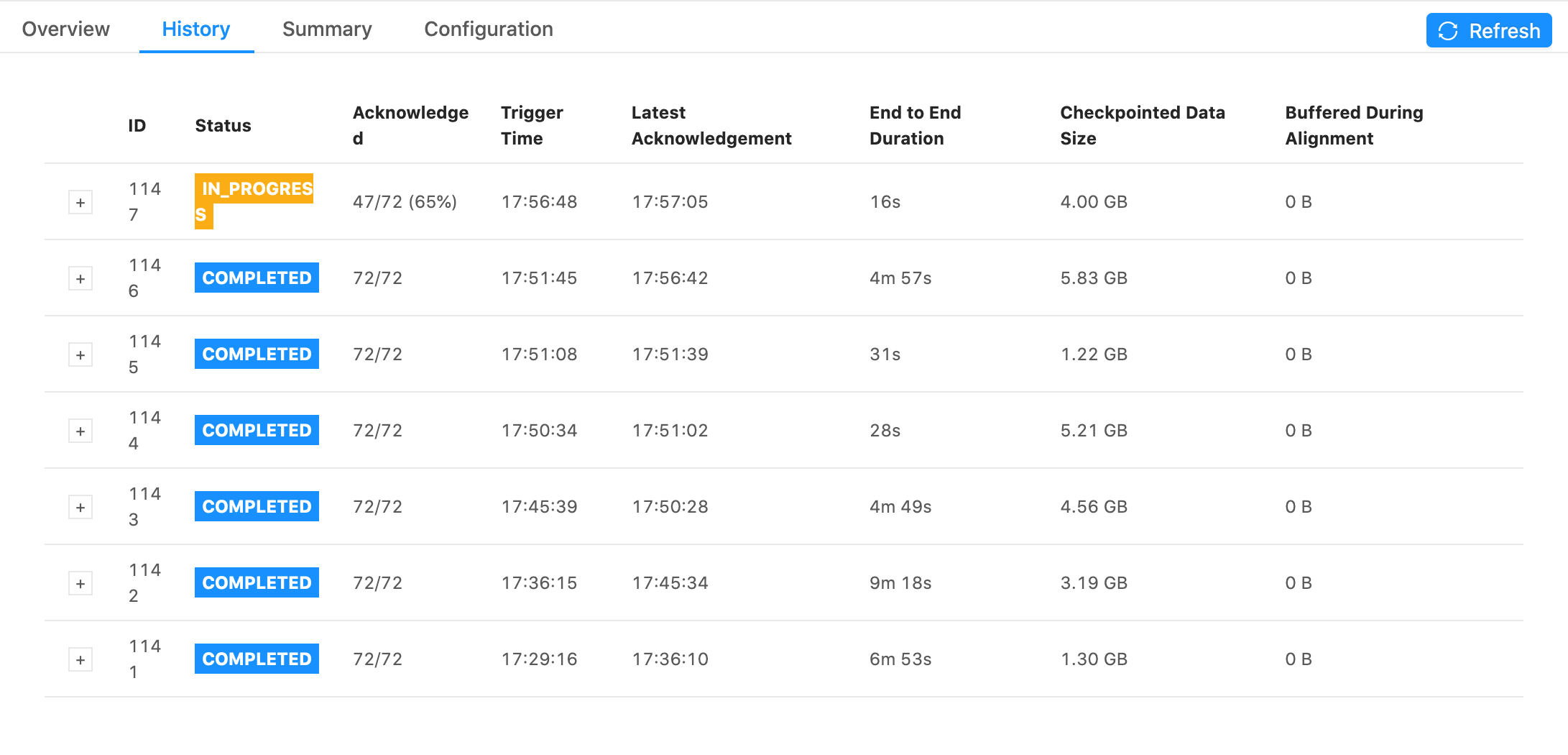
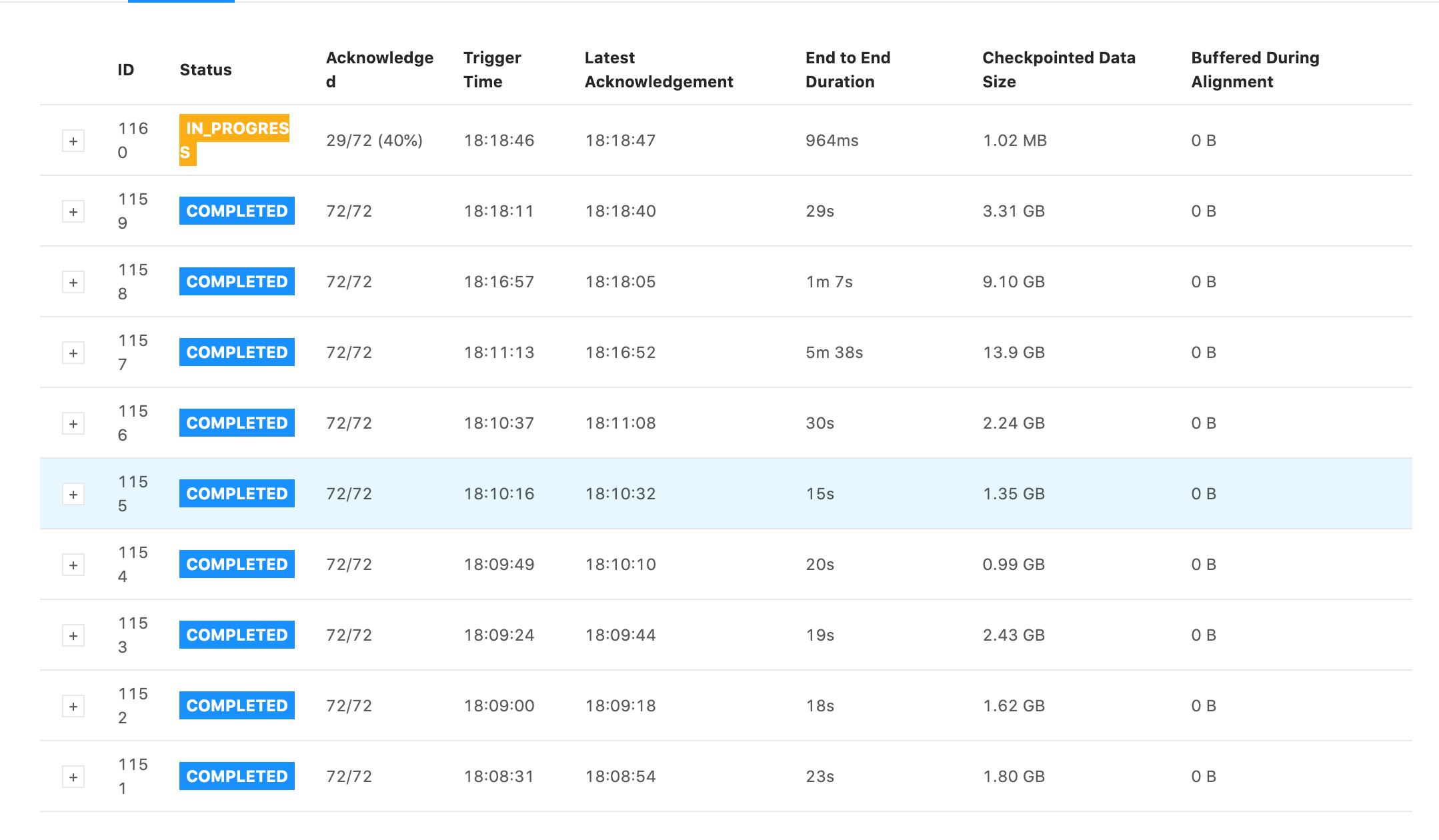
Re: Interpretting checkpoint data size
|
|
Hi Rex, I agree with Arvid, incremental checkpoint size highly depends on the nature of the updates. It can also depend on the operators in your graph. Do you have any windowing or some timers? Can you share per-operator stats? What checkpoint sizes do you get when you use non-incremental checkpoints? > Is there any compaction mechanism for the checkpoints? Yes, whenever RocksDB performs a compaction (locally), the old SST files are deleted and no longer referenced from further checkpoints. And when the old checkpoints are subsumed these old files are deleted from S3/DFS as well. > does mutating the same state multiple times cause it to collapse to 1 change in an incremental checkpoint or does it store all changes? It depends on whether these changes stay in the memtable or (if flushed) get compacted before the checkpoint. I guess it depends on RocksDB settings. I'm also pulling in Yun Tang as he might know better. Regards,
Roman On Fri, Jan 15, 2021 at 9:38 PM Rex Fenley <[hidden email]> wrote:
|
| Free forum by Nabble | Edit this page |