Improving performance throughput in operators


|
I’ve been trying to optimize performance of my application by playing around with the serialization process when sending data across operators.
Currently I’ve source stream(1) reading from Kafka Avro data, an operator(2) which converts avro and generates byte[] from POJO lastly an operator(3) to filter inputs. Operators 2 & 3 are extending from “ProcessFunction”.
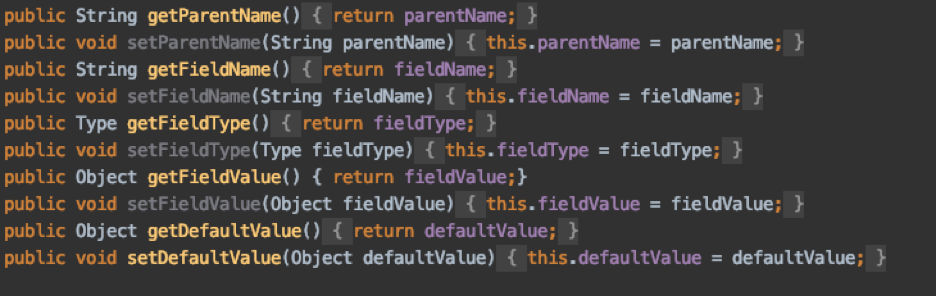
1. DataStream<byte[]> kafkaStream = env.addSource(flinkKafkaConsumer).setParallelism(KAFKA_PARALLELISM).name("KafkaConsumer");
2. AvroBytesConversionPerfProcess avroBytesConversionProcess = new AvroBytesConversionPerfProcess(schemaRegistryUrl) {}; SingleOutputStreamOperator<byte[]> avroProccesedStream = kafkaStream.process(avroBytesConversionProcess).setParallelism(AVRO_PARALLELISM).name("AvroStreamProcess");
3. ExtractTransformPerfProcess extractor = new ExtractTransformPerfProcess();
4. POJO public class CustomRecord { }
Throughput of Kafka records out/sec is around 4K TPS if I emit dummy byte[] e.g. bytes from milliseconds from operator 2 to 3 but moment I try to convert POJO to Avro & get byte[] out in operator 2 its performance drops to 1.5K TPS. Why does it drop so much even when operator 3 doesn’t do much? |
Re: Improving performance throughput in operators
|
|
Hi Arpith, things that I'd do: * Keep the parallelism uniform across all operators: By changing the parallelism, you are forcing Flink to send all records over the network and perform serialization. Unless you really have a compute intensive task, you want to keep everything the same to allow task chaining. [1] * enableObjectReuse [2]: If you have multiple operators all records are copied from one operator to another to eliminate side-effects by unsound user code. enableObjectReuse avoids this copying and significantly improves throughput for larger records. * Convert your records in the task to a POJO already. The basic setup with Avro from Kafka is to use the AvroDeserializationSchema [3] where you pass a POJO generated by Avro [4] (schema first approach). On Sun, Oct 4, 2020 at 8:25 AM Arpith P <[hidden email]> wrote:
-- Arvid Heise | Senior Java Developer Follow us @VervericaData -- Join Flink Forward - The Apache Flink Conference Stream Processing | Event Driven | Real Time -- Ververica GmbH | Invalidenstrasse 115, 10115 Berlin, Germany -- Ververica GmbHRegistered at Amtsgericht Charlottenburg: HRB 158244 B Managing Directors: Timothy Alexander Steinert, Yip Park Tung Jason, Ji (Toni) Cheng |
|
|
Thanks Arvid, I'll make those changes and see improvements. On Mon, Oct 5, 2020 at 2:58 PM Arvid Heise <[hidden email]> wrote:
|
| Free forum by Nabble | Edit this page |