Hello!
I'm reposting this since the other thread had some formatting issues apparently. I hope this time it works.
I'm having performance problems with a Flink job. If there is anything valuable missing, please ask and I will try to answer ASAP. My job looks like this:
/*
Settings
*/
env.setParallelism(4)
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
/*
Operator Graph
*/
env
.addSource(new FlinkKafkaConsumer09("raw.my.topic", new SimpleStringSchema(), props)) // 100k msgs msgs/s
.map(new MyJsonDecoder) // 25k msgs/s
.map(new AddTypeToJsonForSplitting) // 20k msgs/s
.split(t => Seq(t._1.name))
.select(TYPE_A.name) // 18k msgs/s
.flatMap(new MapJsonToEntity) // 13k msgs/s
.flatMap(new MapEntityToMultipleEntities) // 10k msgs/s
.assignTimestampsAndWatermarks(/* Nothing special */) // 6-8k msgs/s
/*
Run
*/
env.execute()
First, I read data from Kafka. This is very fast at 100k msgs/s. The data is decoded, a type is added (we have multiple message types per Kafka topic). Then we select the TYPE_A messages, create a Scala entity out of if (a case class). Afterwards in the MapEntityToMultipleEntities the Scala entities are split into multiple. Finally a watermark is added.
As you can see the data is not keyed in any way yet.
Is there a way to make this faster?
Measurements were taken with
def writeToSocket[?](d: DataStream[?], port: Int): Unit = {
d.writeToSocket("localhost", port, new SerializationSchema[?] {
override def serialize(element: ?): Array[Byte] = {
"\n".getBytes(CharsetUtil.UTF_8)
}
})
}
and nc -lk PORT | pv --line-mode --rate --average-rate --format "Current: %r, Avg:%a, Total: %b" > /dev/null
I'm running this on a Intel i5-3470, 16G RAM, Ubuntu 16.04.1 LTS on Flink 1.1.4


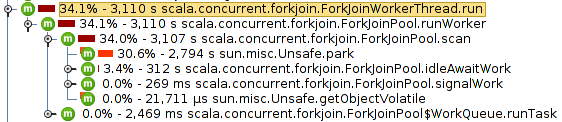 Also, the following code snippet executes unexpectedly slow:
Also, the following code snippet executes unexpectedly slow: