I have some interesting result with my test code

I have some interesting result with my test code

|
Hi guys, I've been recently experimenting with end-to-end testing environment with Kafka and Flink (1.11)
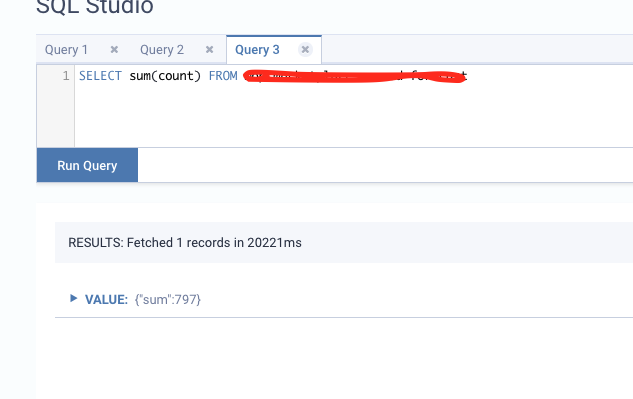
I've setup an infrastructure with Docker Compose composed of single Kafka broker / Flink (1.11) / MinIO for checkpoint saves Here's the test scenario 1. Send 1000 messages with manual timestamp assigned to each event increased by 100 milliseconds per loop (first message and last message has a difference of 100 seconds). There are 3 partitions for the topic I'm writing to. Below code is the test message producer using Confluent's Python SDK order_producer = get_order_producer() 2. Flink performs an SQL query on this stream and publishes it back to Kafka topic that has 3 partitions. Below is the SQL code | SELECT So I expect the sum of all the counts of the result to be equal to 1000 but it seems that a lot of messages are missing (797 as below). I can't seem to figure out why though. I'm using event time for the environment 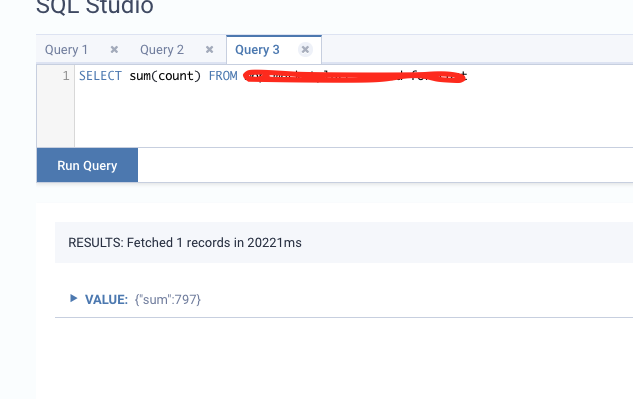 Below is the configuration code Here's the code for the consumer settings for Kafka private def initOrderConsumer(): FlinkKafkaConsumer[Order] = {
private def initProcessedModelProducer(): FlinkKafkaProducer[ProcessedModel] = { |
Re: I have some interesting result with my test code
|
|
Looks like the event time that I've specified in the consumer is not being respected. Does the timestamp assigner actually work in Kafka consumers? .withTimestampAssigner(new SerializableTimestampAssigner[Order] { On Tue, Nov 3, 2020 at 12:01 AM Kevin Kwon <[hidden email]> wrote:
|
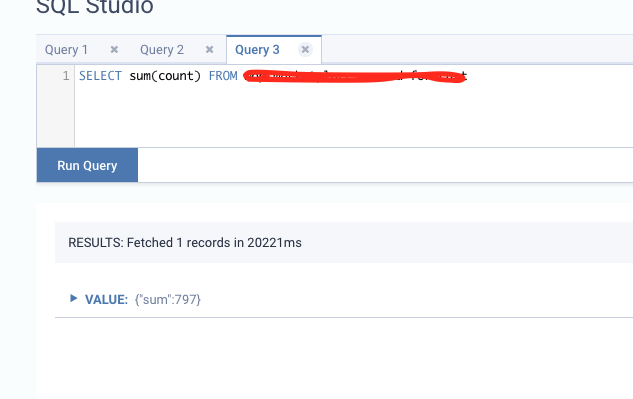
|
|
Hi Kevin, thanks a lot for posting this problem. I'm adding Jark to the thread, he or another committer working on Flink SQL can maybe provide some insights. On Tue, Nov 3, 2020 at 4:58 PM Kevin Kwon <[hidden email]> wrote:
|
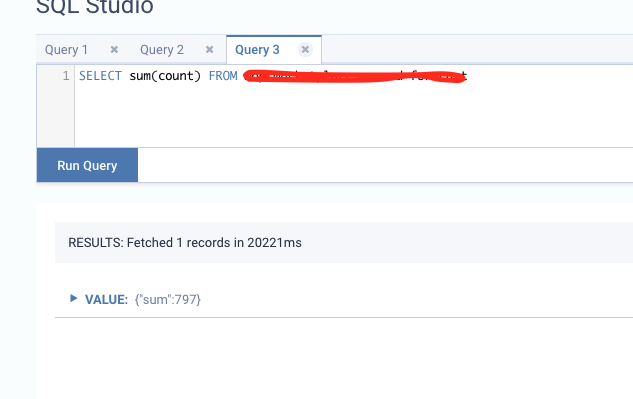
|
|
Hi Kevin, Could you share the code of how you register the FlinkKafkaConsumer as a table? Regarding your initialization of FlinkKafkaConsumer, I would recommend to setStartFromEarliest() to guarantee it consumes all the records in partitions. Regarding the flush(), it seems it is in the foreach loop? So it is not flushing after publishing ALL events? I'm not experienced with the flush() API, could this method block and the following random events can't be published to Kafka? Best, Jark On Wed, 4 Nov 2020 at 04:04, Robert Metzger <[hidden email]> wrote:
|
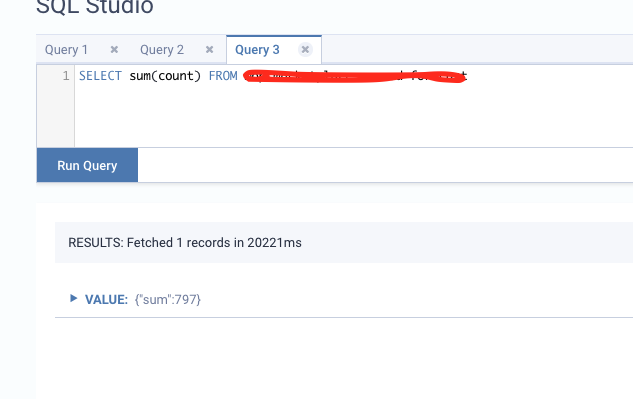
|
|
Great to hear it works! `setStartFromGroupOffset` [1] will start reading partitions from the consumer group’s (group.id setting in the consumer properties) committed offsets in Kafka brokers. If offsets could not be found for a partition, the 'auto.offset.reset' setting in the properties will be used. And the default value of 'auto.offset.reset' property is latest [2]. I think that's why `setStartFromGroupOffset` doesn't consume all the events. On Fri, 6 Nov 2020 at 07:04, Kevin Kwon <[hidden email]> wrote:
|
«
Return to (DEPRECATED) Apache Flink User Mailing List archive.
|
1 view|%1 views
| Free forum by Nabble | Edit this page |