How to run a per-job cluster for a Beam pipeline w/ FlinkRunner on YARN

How to run a per-job cluster for a Beam pipeline w/ FlinkRunner on YARN

|
Hi, I'm trying to run a per-job cluster for a Beam pipeline w/ FlinkRunner on YARN as follows: flink run -m yarn-cluster -d \ my-beam-pipeline.jar \ Instead of creating a per-job cluster as wished, the above command seems to create a session cluster and then submit a job onto the cluster. I doubt it because (1) In the attached file, there's "Submit New Job" which is not shown in other per-job applications that are written in Flink APIs and submitted to YARN similar to the above command. 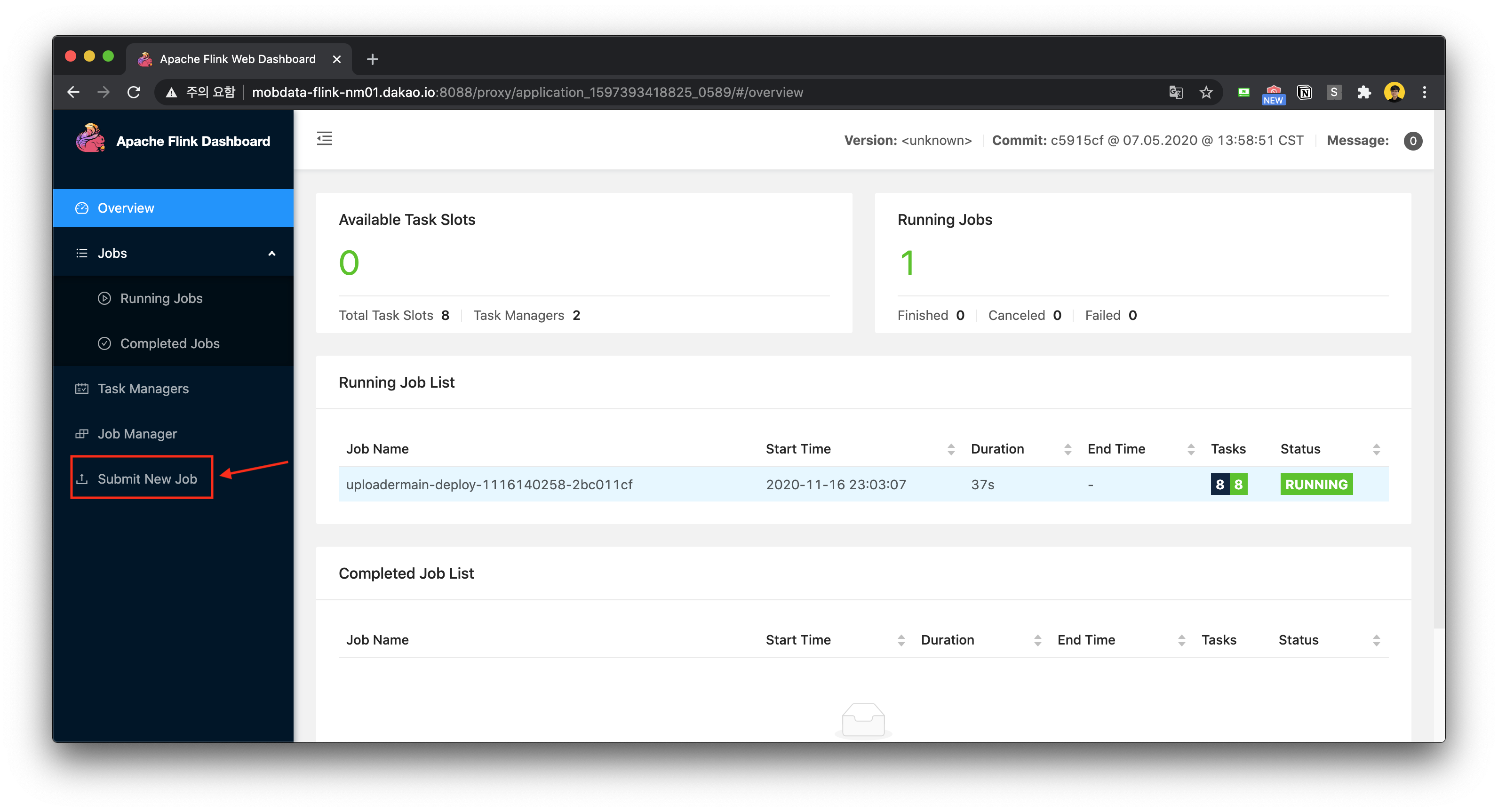 (2) When the job is finished, the YARN application is still in its RUNNING state without being terminated. I had to kill the YARN application manually. FYI, I'm using - Beam v2.24.0 (Flink 1.10) - Hadoop v3.1.1 Thanks in advance, Best, Dongwon |
Re: How to run a per-job cluster for a Beam pipeline w/ FlinkRunner on YARN
|
|
Hi, Not sure if this question would be more suitable for the Apache Beam mailing lists, but I'm pulling in Aljoscha (CC'ed) who would know more about Beam and whether or not this is an expected behaviour. Cheers, Gordon On Mon, Nov 16, 2020 at 10:35 PM Dongwon Kim <[hidden email]> wrote:
|
Re: How to run a per-job cluster for a Beam pipeline w/ FlinkRunner on YARN
|
|
Hi,
to ensure that we really are using per-job mode, could you try and use $ flink run -t yarn-per-job -d <...> This will directly specify that we want to use the YARN per-job executor, which bypasses some of the logic in the older YARN code paths that differentiate between YARN session mode and YARN per-job mode. Best, Aljoscha On 17.11.20 07:02, Tzu-Li (Gordon) Tai wrote: > Hi, > > Not sure if this question would be more suitable for the Apache Beam > mailing lists, but I'm pulling in Aljoscha (CC'ed) who would know more > about Beam and whether or not this is an expected behaviour. > > Cheers, > Gordon > > On Mon, Nov 16, 2020 at 10:35 PM Dongwon Kim <[hidden email]> wrote: > >> Hi, >> >> I'm trying to run a per-job cluster for a Beam pipeline w/ FlinkRunner on >> YARN as follows: >> >>> flink run -m yarn-cluster -d \ >> >> my-beam-pipeline.jar \ >>> --runner=FlinkRunner \ >>> --flinkMaster=[auto] \ >>> --parallelism=8 >> >> >> Instead of creating a per-job cluster as wished, the above command seems >> to create a session cluster and then submit a job onto the cluster. >> >> I doubt it because >> (1) In the attached file, there's "Submit New Job" which is not shown in >> other per-job applications that are written in Flink APIs and submitted to >> YARN similar to the above command. >> >> [image: beam on yarn.png] >> (2) When the job is finished, the YARN application is still in its RUNNING >> state without being terminated. I had to kill the YARN application manually. >> >> FYI, I'm using >> - Beam v2.24.0 (Flink 1.10) >> - Hadoop v3.1.1 >> >> Thanks in advance, >> >> Best, >> >> Dongwon >> > |
Re: How to run a per-job cluster for a Beam pipeline w/ FlinkRunner on YARN
|
|
Hi Aljoscha, Thanks for the input. The '-t' option seems to be available as of flink-1.11 while the latest FlinkRunner is based on flink-1.10. So I use '-e' option which is available in 1.10: $ flink run -e yarn-per-job -d <...> A short question here is that this command ignores -yD and --yarnship options. Are these options only for yarn session mode? Best, Dongwon On Tue, Nov 17, 2020 at 5:16 PM Aljoscha Krettek <[hidden email]> wrote: Hi, |
Re: How to run a per-job cluster for a Beam pipeline w/ FlinkRunner on YARN
|
|
Yes, these options are yarn-specific, but you can specify arbitrary
options using -Dfoo=bar. And yes, sorry about the confusion but -e is the parameter to use on Flink 1.10, it's equivalent. Best, Aljoscha On 17.11.20 16:37, Dongwon Kim wrote: > Hi Aljoscha, > > Thanks for the input. > The '-t' option seems to be available as of flink-1.11 while the latest > FlinkRunner is based on flink-1.10. > So I use '-e' option which is available in 1.10: > > $ flink run -e yarn-per-job -d <...> > > > A short question here is that this command ignores *-yD* and *--yarnship* > options. > Are these options only for yarn session mode? > > Best, > > Dongwon > > > > > On Tue, Nov 17, 2020 at 5:16 PM Aljoscha Krettek <[hidden email]> > wrote: > >> Hi, >> >> to ensure that we really are using per-job mode, could you try and use >> >> $ flink run -t yarn-per-job -d <...> >> >> This will directly specify that we want to use the YARN per-job >> executor, which bypasses some of the logic in the older YARN code paths >> that differentiate between YARN session mode and YARN per-job mode. >> >> Best, >> Aljoscha >> >> On 17.11.20 07:02, Tzu-Li (Gordon) Tai wrote: >>> Hi, >>> >>> Not sure if this question would be more suitable for the Apache Beam >>> mailing lists, but I'm pulling in Aljoscha (CC'ed) who would know more >>> about Beam and whether or not this is an expected behaviour. >>> >>> Cheers, >>> Gordon >>> >>> On Mon, Nov 16, 2020 at 10:35 PM Dongwon Kim <[hidden email]> >> wrote: >>> >>>> Hi, >>>> >>>> I'm trying to run a per-job cluster for a Beam pipeline w/ FlinkRunner >> on >>>> YARN as follows: >>>> >>>>> flink run -m yarn-cluster -d \ >>>> >>>> my-beam-pipeline.jar \ >>>>> --runner=FlinkRunner \ >>>>> --flinkMaster=[auto] \ >>>>> --parallelism=8 >>>> >>>> >>>> Instead of creating a per-job cluster as wished, the above command seems >>>> to create a session cluster and then submit a job onto the cluster. >>>> >>>> I doubt it because >>>> (1) In the attached file, there's "Submit New Job" which is not shown in >>>> other per-job applications that are written in Flink APIs and submitted >> to >>>> YARN similar to the above command. >>>> >>>> [image: beam on yarn.png] >>>> (2) When the job is finished, the YARN application is still in its >> RUNNING >>>> state without being terminated. I had to kill the YARN application >> manually. >>>> >>>> FYI, I'm using >>>> - Beam v2.24.0 (Flink 1.10) >>>> - Hadoop v3.1.1 >>>> >>>> Thanks in advance, >>>> >>>> Best, >>>> >>>> Dongwon >>>> >>> >> >> > |
«
Return to (DEPRECATED) Apache Flink User Mailing List archive.
|
1 view|%1 views
| Free forum by Nabble | Edit this page |