How to partition within same physical node in Flink

How to partition within same physical node in Flink

|
Hi, Need to partition by cameraWithCube.getCam() 1st using parallelCamTasks(passed in as args). Then within each partition, need to partition again by cameraWithCube.getTs() but need to make sure each of the 2nd partition by getTS() runs on the same physical node ? How do I achieve that ? TIA |
Re: How to partition within same physical node in Flink
|
|
Hi, Flink distributes task instances to slots and does not expose physical machines. Records are partitioned to task instances by hash partitioning. It is also not possible to guarantee that the records in two different operators are send to the same slot. Sharing information by side-passing it (e.g., via a file on a machine or in a static object) is an anti-pattern and should be avoided. Best, Fabian 2018-06-24 20:52 GMT+02:00 Vijay Balakrishnan <[hidden email]>:
|
Re: How to partition within same physical node in Flink
|
|
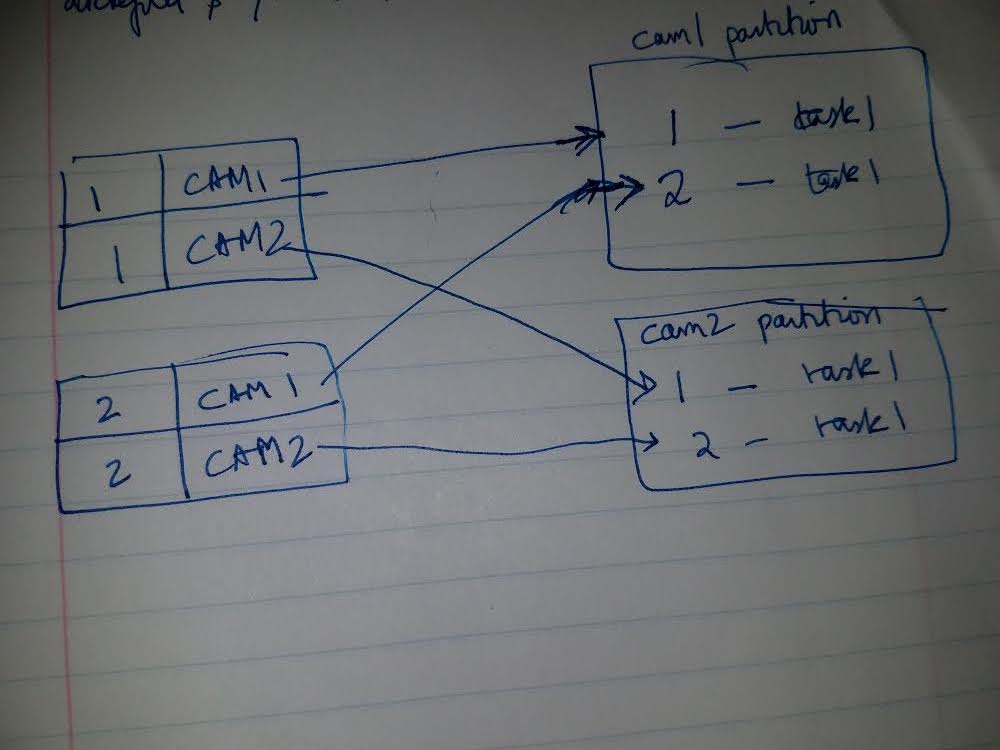
Thanks, Fabian. Been reading your excellent book on Flink Streaming.Can't wait for more chapters. Attached a pic. 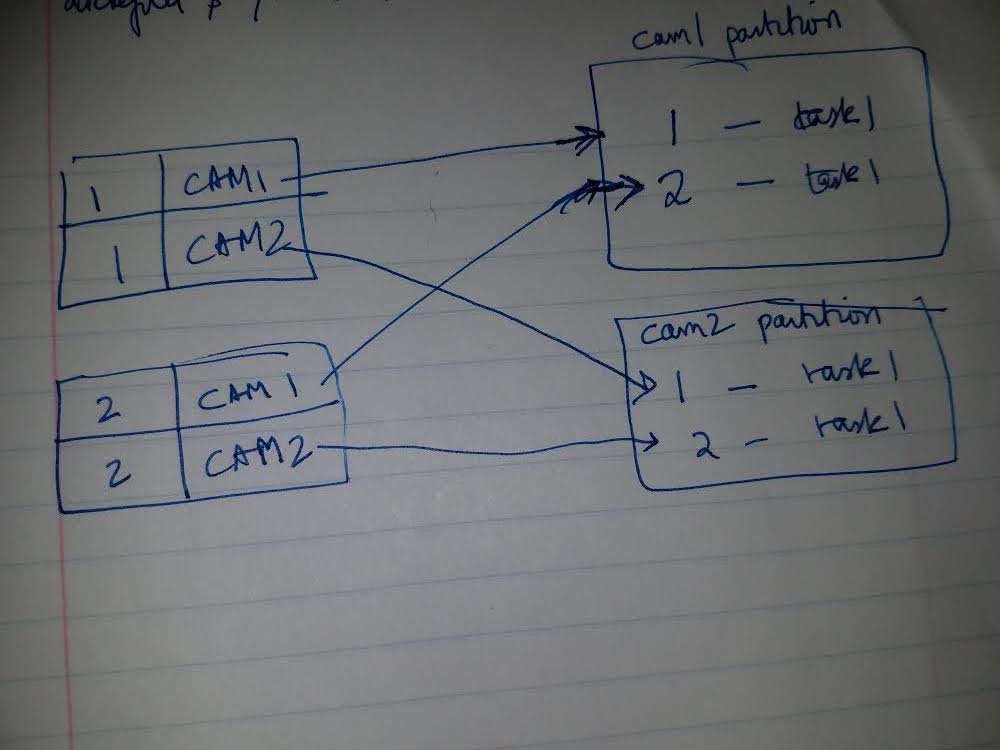 I have records with seq# 1 and cam1 and cam2. I also have records with varying seq#'s. By partitioning on cam field first(keyBy(cam)), I can get cam1 partition on the same task manager instance/slot/vCore(???) Can I then have seq# 1 and seq# 2 for cam1 partition run in different slots/threads on the same Task Manager instance(aka cam1 partition) using keyBy(seq#) & setParallelism() ? Can forward Strategy be used to achieve this ? TIA On Mon, Jun 25, 2018 at 1:03 AM Fabian Hueske <[hidden email]> wrote:
|
Re: How to partition within same physical node in Flink
|
|
I see a .slotSharingGroup for SingleOutputStreamOperator which can put parallel instances of operations in same TM slot. I also see a CoLocationGroup but do not see a .coLocationGroup for SingleOutputStreamOperator to put a task on the same slot.Seems CoLocationGroup is defined at JobVertex level and has nothing to do with for SingleOutputStreamOperator. TaskManager has many slots. Slots have many threads within it. I want to be able to put the cam1 partition(keyBy(cam) in 1 slot and then use a keyBy(seq#) to run on many threads within that cam1 slot. Vijay On Mon, Jun 25, 2018 at 10:10 AM Vijay Balakrishnan <[hidden email]> wrote:
|
Re: How to partition within same physical node in Flink
|
|
Hi, keyBy() does not work hierarchically. Each keyBy() overrides the previous partitioning. You can keyBy(cam, seq#) which guarantees that all records with the same (cam, seq#) are processed by the same parallel instance. However, Flink does not give any guarantees about how the (cam, seq#) partitions are distributed across slots (or even physical nodes). Btw. why is it important that all records of the same cam are processed by the same physical node? Fabian 2018-06-25 21:36 GMT+02:00 Vijay Balakrishnan <[hidden email]>:
|
Re: How to partition within same physical node in Flink
|
|
Hi Fabian, Thanks once again for your reply. I need to get the data from each cam/camera into 1 partition/slot and not move the gigantic video data around as much as I perform other operations on it. For eg, I can get seq#1 and seq#2 for cam1 in cam1 partition/slot and then combine, split,parse, stitch etc. operations on it in multiple threads within the same cam1 partition. I have the CameraKey defined as cam,seq# and then keyBy(cam) to get it in 1 partition(eg: cam1). The idea is to then work within the cam1 partition with various seq#'s 1,2 etc on various threads within the same slot/partition of TaskManager. The data is stored in EFS keyed based on seq#/cam# folder structure. Our actual problem is managing network bandwidth as a resource in each partition. We want to make sure that the processing of 1 camera(split into multiple seq# tasks) is not running on the same node as the processing of another camera as in that case, the required network bandwidth for storing the output of the process running in the partition would exceed the network bandwidth of the hardware. Camera processing is expected to run on the same hardware as the video decode step which is an earlier sequential process in the same Dataflow pipeline. I guess I might have to use a ThreadPool within each Slot(cam partition) to work on each seq# ?? TIA On Tue, Jun 26, 2018 at 1:06 AM Fabian Hueske <[hidden email]> wrote:
|
Re: How to partition within same physical node in Flink
|
|
Hi Vijay, Flink does not provide fine-grained control to place keys to certain slots or machines. When specifying a key, it is up to Flink (i.e., its internal hash function) where the data is processed. This works well for large key spaces, but can be difficult if you have only a few keys. So, even if you keyBy(cam) and handle the parallelization of seq# internally (which I would not recommend), it might still happen that the data of two cameras is processed on the same slot. The only way to change that would be to fiddle with the hash of your keys, but this might give you a completely different distribution when scaling out the application at a later point in time. Best, Fabian 2018-06-26 19:54 GMT+02:00 Vijay Balakrishnan <[hidden email]>:
|
Re: How to partition within same physical node in Flink
|
|
Fabian, All,
Along this same line, we have a datasource where we have parent key and child key. We need to first keyBy parent and then by child. If we want to have physical partitioning in a way where physical partiotioning happens first by parent key and localize grouping by child key, is there a need to using custom partitioner? Obviously we can keyBy twice but was wondering if we can minimize the re-partition stress. Thanks, Ashish
- Ashish On Thursday, June 28, 2018, 9:02 AM, Fabian Hueske <[hidden email]> wrote:
|
Re: How to partition within same physical node in Flink
|
|
Thanks for the clarification, Fabian. This is what I compromised on for my use-case-doesn't exactly do what I intended to do. Partition by a key, and then spawn threads inside that partition to do my task and then finally repartition again(for a subsequent connect). DataStream<CameraWithCube> keyedByCamCameraStream = env .addSource(new Source(....)) .keyBy((cameraWithCube) -> cameraWithCube.getCam() ); AsyncFunction<CameraWithCube, CameraWithCube> cameraWithCubeAsyncFunction = new SampleAsyncFunction(...., nThreads);//spawn threads here with the second key ts here DataStream<CameraWithCube> cameraWithCubeDataStreamAsync = AsyncDataStream.orderedWait(keyedByCamCameraStream, cameraWithCubeAsyncFunction, timeout, TimeUnit.MILLISECONDS, nThreads) .setParallelism(parallelCamTasks);//capacity=max # of inflight requests - how much; timeout - max time until considered failed DataStream<CameraWithCube> cameraWithCubeDataStream = cameraWithCubeDataStreamAsync.keyBy((cameraWithCube) -> cameraWithCube.getTs()); On Thu, Jun 28, 2018 at 9:22 AM ashish pok <[hidden email]> wrote:
|
Re: How to partition within same physical node in Flink
|
|
Hi Ashish, hi Vijay, Flink does not distinguish between different parts of a key (parent, child) in the public APIs. However, there is an internal concept of KeyGroups which is similar to what you call physical partitioning. A KeyGroup is a group of keys that are always processed on the same physical node. The motivation for this feature is operator scaling because all keys of a group are always processed by the same node and hence their state is always distributed together. However, AFAIK, KeyGroups are not exposed to the user API. Moreover, KeyGroups are distributed to slots, i.e., each KeyGroup is processed by a single slot, but each slot might processes multiple key groups. This distribution is done with hash partitioning and hence hard to tune. There might be a way to tweak this by implementing an own low-level operator but I'm not sure. Stefan (in CC) might be able to give some hints. Best, Fabian 2018-06-29 18:35 GMT+02:00 Vijay Balakrishnan <[hidden email]>:
|
Re: How to partition within same physical node in Flink
|
|
Thanks Fabian! It sounds like KeyGroup will do the trick if that can be made publicly accessible.
On Monday, July 2, 2018, 5:43:33 AM EDT, Fabian Hueske <[hidden email]> wrote:
Hi Ashish, hi Vijay, Flink does not distinguish between different parts of a key (parent, child) in the public APIs. However, there is an internal concept of KeyGroups which is similar to what you call physical partitioning. A KeyGroup is a group of keys that are always processed on the same physical node. The motivation for this feature is operator scaling because all keys of a group are always processed by the same node and hence their state is always distributed together. However, AFAIK, KeyGroups are not exposed to the user API. Moreover, KeyGroups are distributed to slots, i.e., each KeyGroup is processed by a single slot, but each slot might processes multiple key groups. This distribution is done with hash partitioning and hence hard to tune. There might be a way to tweak this by implementing an own low-level operator but I'm not sure. Stefan (in CC) might be able to give some hints. Best, Fabian 2018-06-29 18:35 GMT+02:00 Vijay Balakrishnan <[hidden email]>:
|
Re: How to partition within same physical node in Flink
|
|
Hi Ashish, I think we don't want to make it an official public API (at least not at this point), but maybe you can dig into the internal API and leverage it for your use case. I'm not 100% sure about all the implications, that's why I pulled in Stefan in this thread. Best, Fabian 2018-07-02 15:37 GMT+02:00 ashish pok <[hidden email]>:
|
Re: How to partition within same physical node in Flink
|
|
Thanks - I will wait for Stefan’s comments before I start digging in.
|
| Free forum by Nabble | Edit this page |