How to limit IO metrics since they are duplicated/triplicated/quadrup

How to limit IO metrics since they are duplicated/triplicated/quadrup

|
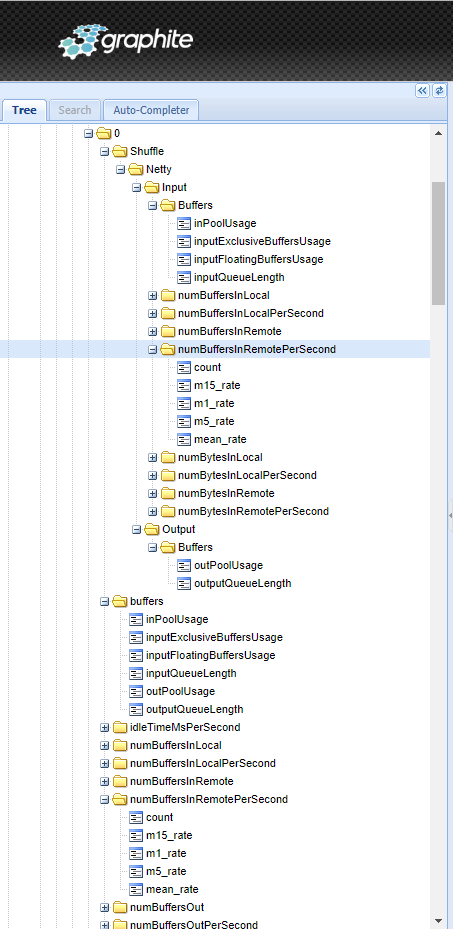
Hello, When using flink 1.11.1 all the I/O metrics are at least duplicated. Some of them even quadruplicated. Each IO metrics are available per each taskmanager per each operator which generates an insane amount of duplicated data. Here is an example when using graphite (picture 1):
same goes for numRecordsIn, numRecordsOut, numBytesIn. picture 1: shows we have each IO type twice with the same data 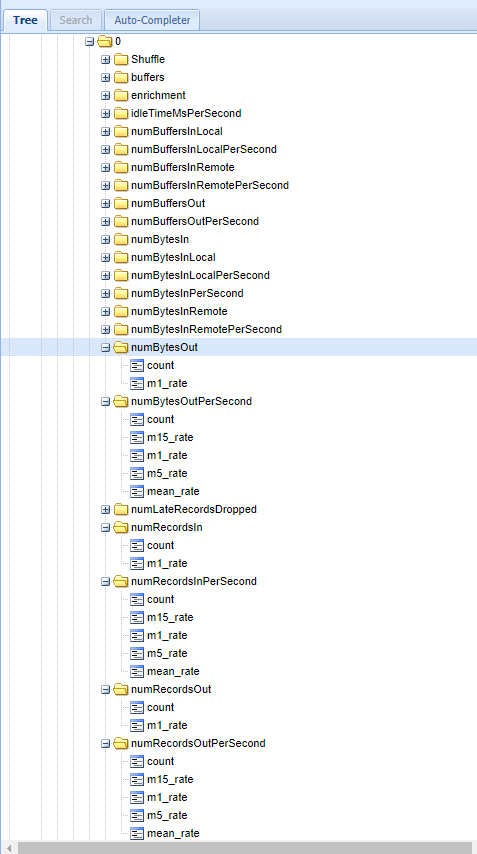 When you take a look for remote buffers things get even worse: the data is available on 4 different places (picture 2)
and buffer specific is available on 2 different places:
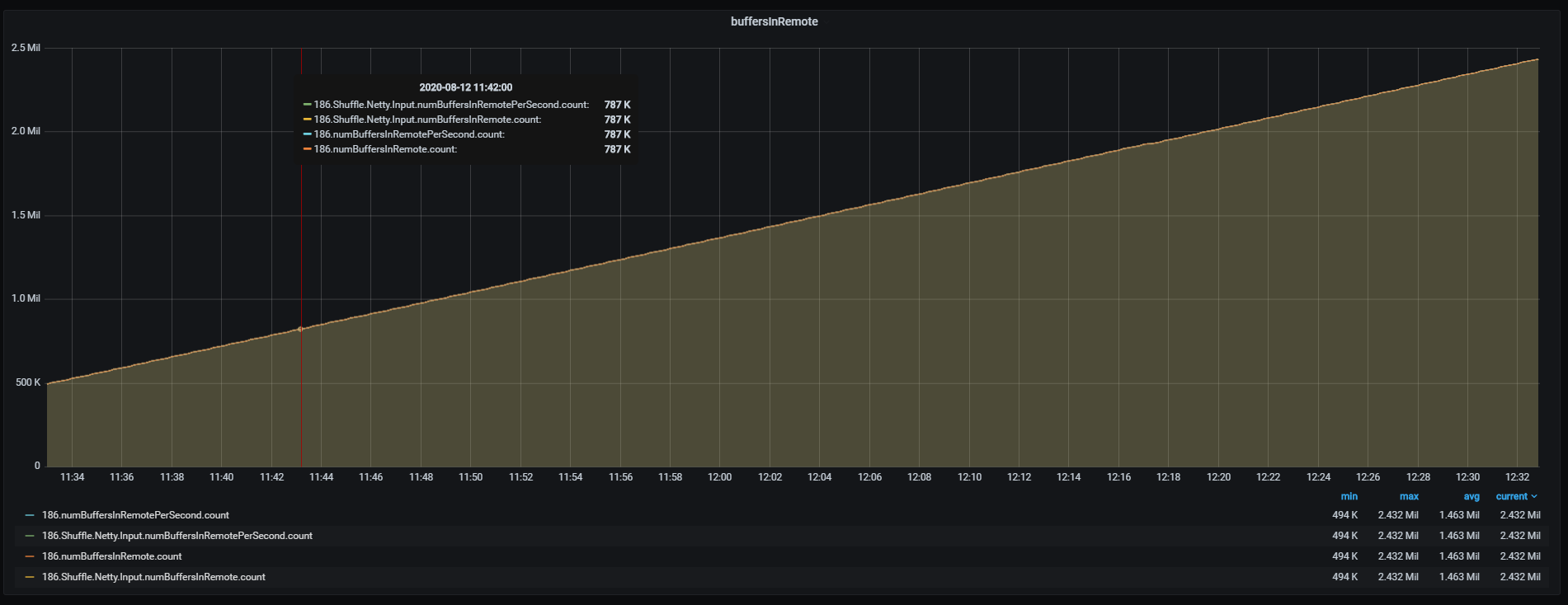
picture 2: shows the amount of metrics related to buffers 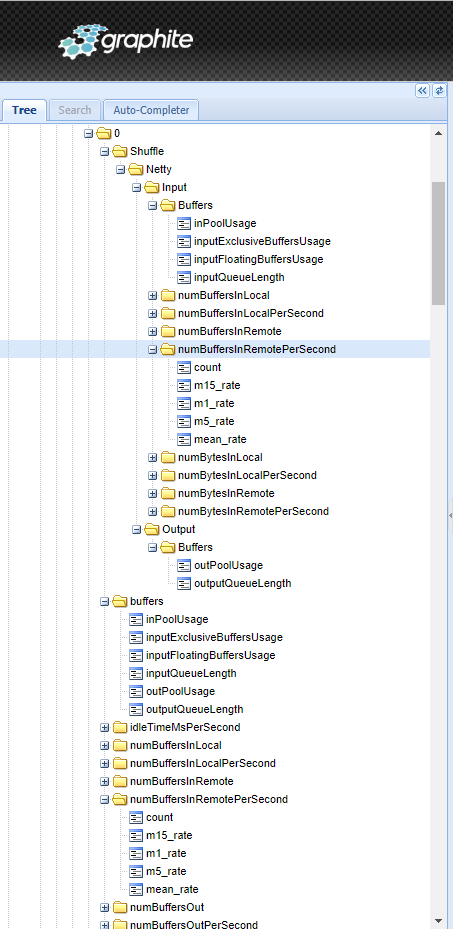 In all those examples "0" is the slot_id of a single operator. And all those metrics return the same data picture 3: shows that all the "numBuffersInRemote" related metrics produce the exact same number, but we store them 4 times 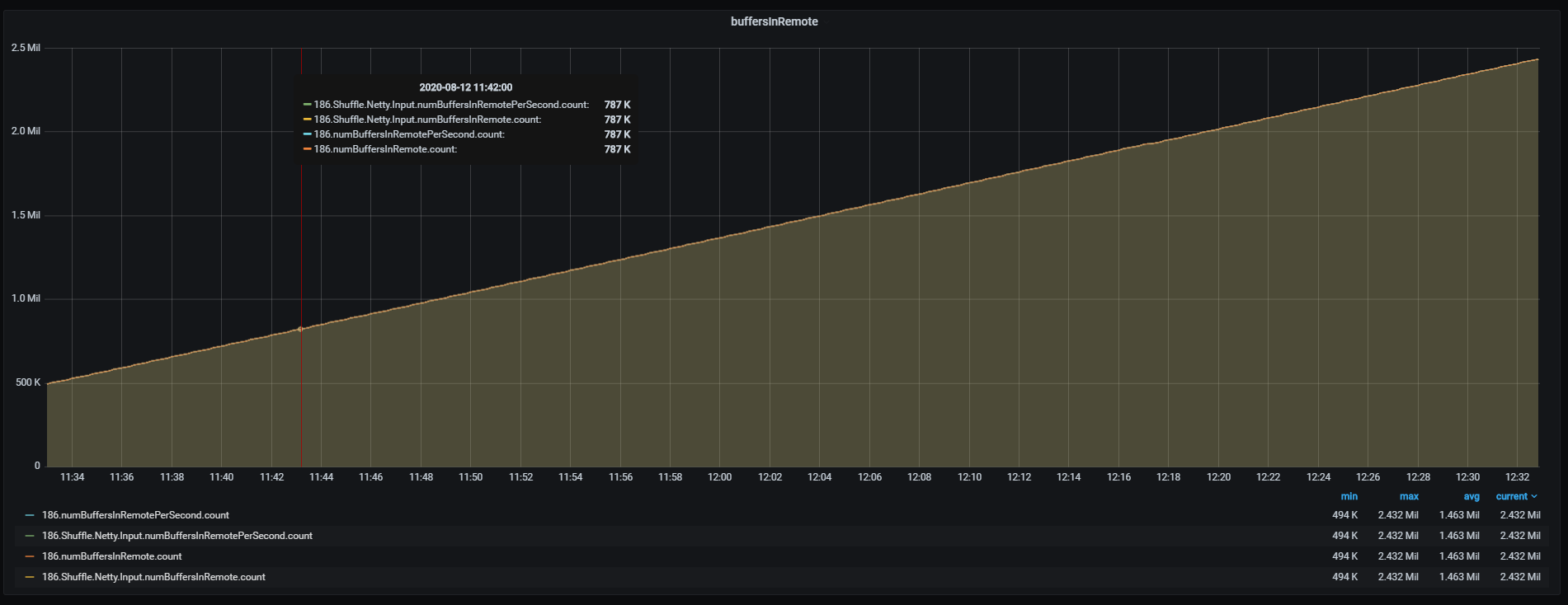 The conclusion from those examples and pictures is that our metrics cluster needs to handle 3-4 times more data than we need. So my questions are: Is there a way to not produce/limit all those metrics? Why is each metric sent with the post suffix "PerSecond" if it sends the same data? Why not just send a single metric? Regards ,Nikola Hrusov <a href="tel:%28%2B45%29%2060%2054%2032%2016" value="+4560543216" style="color:rgb(17,85,204)" target="_blank"> |
Re: How to limit IO metrics since they are duplicated/triplicated/quadrup
|
|
There is currently no built-in way to
disable metrics, apart from implementing your own / customizing an
existing reporter.
Metrics are measured both on an
operator and task level.
If you have a task containing a single
operator, then yes the numRecordsIn/Out metrics are duplicated.
The "0" is the subtask index. If your
operator with a parallelism greater than 1 you will naturally get
these metrics N times, and they may or may not be different.
Flink differentiates between counters
(providing counts) and meters (providing rates).
The GraphiteReporter re-uses the
io.dropwizard implementation which (unfortunately for us) also
exposes the count of events for each meter, duplicating the
counter data.
There is no easy way for us to change
this apart from re-implementing the whole thing.
There are also indeed some metrics that
are registered under multiple names for backwards-compatibility,
an example being numBuffersInRemote.
On 12/08/2020 14:15, Nikola Hrusov
wrote:
|
«
Return to (DEPRECATED) Apache Flink User Mailing List archive.
|
1 view|%1 views
| Free forum by Nabble | Edit this page |