How to divide streams on key basis and deliver them

How to divide streams on key basis and deliver them

|
Hi, this is my project purpose using Kafka and Flink:
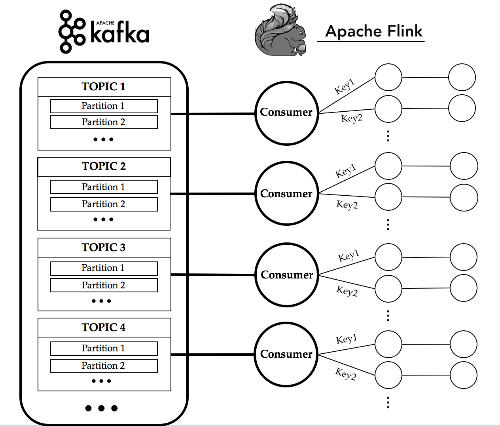 In kafka topics there are streams representing sensor lectures of different subjects. Each topic is reserved for a different sensor. Every messages are attached with a key using kafka keyed messages. The key represent a subject id and the attached sensor data belong to the highlighted subject. In Flink I want to: - Get these streams - Separate streams on key (subject) basis in order to build a node chain which evaluates always same sensor values of same subjects. Thanks to you, I have correctly implemented a custom deserializer in order to get data and key from Kafka. So now I need to separate streams on key basis. As you can see in schema image, in my mind each circle represents a different physical machine in a cluster I the deserializer runs over the bigger circles which separate streams and deliver them to different smaller circles on key basis. I read the doc and I think I have to use keyBy() operator on DataStream in order to obtain a KeyedStream. It carry me to my first question: - I tried to print datastream and keyedstream. The former give me this:  while the latter give me this:  What do the numbers before the record string means (the '3' in the latter case)? Then: - How can I 'deliver' the streams in following nodes (smaller circles) on key basis? Now I'm developing on a single machine just to try and learn but also I'm a bit confused about how to develop it on cluster. |
Re: How to divide streams on key basis and deliver them
|
|
Hi,
Let me try to explain this from another user’s perspective ☺ When you run your application, Flink will map your logical/application topology onto a number of task slots (documented in more detail here: https://ci.apache.org/projects/flink/flink-docs-release-1.3/internals/job_scheduling.html). Basically, if it is possible/unless told otherwise, Flink will create a number of copies of your functions that is On 6/14/17, 21:19, "AndreaKinn" <[hidden email]> wrote: Hi, this is my project purpose using Kafka and Flink: <http://apache-flink-user-mailing-list-archive.2336050.n4.nabble.com/file/n13743/schema_png.png> In kafka topics there are streams representing sensor lectures of different subjects. Each topic is reserved for a different sensor. Every messages are attached with a key using kafka keyed messages. The key represent a subject id and the attached sensor data belong to the highlighted subject. In Flink I want to: - Get these streams - Separate streams on key (subject) basis in order to build a node chain which evaluates always same sensor values of same subjects. Thanks to you, I have correctly implemented a custom deserializer in order to get data and key from Kafka. So now I need to separate streams on key basis. As you can see in schema image, in my mind each circle represents a different physical machine in a cluster I the deserializer runs over the bigger circles which separate streams and deliver them to different smaller circles on key basis. I read the doc and I think I have to use keyBy() operator on DataStream in order to obtain a KeyedStream. It carry me to my first question: - I tried to print datastream and keyedstream. The former give me this: <http://apache-flink-user-mailing-list-archive.2336050.n4.nabble.com/file/n13743/nokey.png> while the latter give me this: <http://apache-flink-user-mailing-list-archive.2336050.n4.nabble.com/file/n13743/withkey.png> What do the numbers before the record string means (the '3' in the latter case)? Then: - How can I 'deliver' the streams in following nodes (smaller circles) on key basis? Now I'm developing on a single machine just to try and learn but also I'm a bit confused about how to develop it on cluster. -- View this message in context: http://apache-flink-user-mailing-list-archive.2336050.n4.nabble.com/How-to-divide-streams-on-key-basis-and-deliver-them-tp13743.html Sent from the Apache Flink User Mailing List archive. mailing list archive at Nabble.com. |
Re: How to divide streams on key basis and deliver them
|
|
Ugh, accidentally pressed send already….
When you run your application, Flink will map your logical/application topology onto a number of task slots (documented in more detail here: https://ci.apache.org/projects/flink/flink-docs-release-1.3/internals/job_scheduling.html). Basically, if it is possible/unless told otherwise, Flink will create a number of copies of your functions that is… … equal to the number of task slots: each copy of the function runs in a separate task slot. KeyBy partitions your data for further processing, so applying a function to the KeyedStream makes that function apply to all elements of the stream that have the same key. In addition, the KeyedStream gets distributed to different task managers. This is an answer for your question 1: the number before the record string is the id/sequence number of the copy of the print sink function that is processing that record. In the first case, there is no key, so the records go to arbitrary printer instances. In the second case, all records have the same key (subect), so they are routed to the same copy of the print function, in this case with id=3. If you had records with a different subject, changes are pretty good they would all be printed by a different print function. Regarding your second question, I already answered this a bit, but you might want to look at https://ci.apache.org/projects/flink/flink-docs-release-1.3/dev/windows.html: after keying your stream, you define the window of elements you want to process at a time, and then apply a function to the elements in each window, for each separate key. These functions would be your smaller circles, I suppose. As to local/cluster: since running Flink locally already gives you some parallelism (it defaults to the number of CPU cores on your machine, I believe), you already see a distributed version of your application. When you run on a cluster, the only thing that really changes is how you start the application (See, e.g. https://ci.apache.org/projects/flink/flink-docs-release-1.3/setup/cluster_setup.html for a cluster setup, but it depends on what cluster you have available). Flink abstracts away the specifics of per-node communication in its API already. Hope that helps, Carst On 6/15/17, 08:19, "Carst Tankink" <[hidden email]> wrote: Hi, Let me try to explain this from another user’s perspective ☺ When you run your application, Flink will map your logical/application topology onto a number of task slots (documented in more detail here: https://ci.apache.org/projects/flink/flink-docs-release-1.3/internals/job_scheduling.html). Basically, if it is possible/unless told otherwise, Flink will create a number of copies of your functions that is On 6/14/17, 21:19, "AndreaKinn" <[hidden email]> wrote: Hi, this is my project purpose using Kafka and Flink: <http://apache-flink-user-mailing-list-archive.2336050.n4.nabble.com/file/n13743/schema_png.png> In kafka topics there are streams representing sensor lectures of different subjects. Each topic is reserved for a different sensor. Every messages are attached with a key using kafka keyed messages. The key represent a subject id and the attached sensor data belong to the highlighted subject. In Flink I want to: - Get these streams - Separate streams on key (subject) basis in order to build a node chain which evaluates always same sensor values of same subjects. Thanks to you, I have correctly implemented a custom deserializer in order to get data and key from Kafka. So now I need to separate streams on key basis. As you can see in schema image, in my mind each circle represents a different physical machine in a cluster I the deserializer runs over the bigger circles which separate streams and deliver them to different smaller circles on key basis. I read the doc and I think I have to use keyBy() operator on DataStream in order to obtain a KeyedStream. It carry me to my first question: - I tried to print datastream and keyedstream. The former give me this: <http://apache-flink-user-mailing-list-archive.2336050.n4.nabble.com/file/n13743/nokey.png> while the latter give me this: <http://apache-flink-user-mailing-list-archive.2336050.n4.nabble.com/file/n13743/withkey.png> What do the numbers before the record string means (the '3' in the latter case)? Then: - How can I 'deliver' the streams in following nodes (smaller circles) on key basis? Now I'm developing on a single machine just to try and learn but also I'm a bit confused about how to develop it on cluster. -- View this message in context: http://apache-flink-user-mailing-list-archive.2336050.n4.nabble.com/How-to-divide-streams-on-key-basis-and-deliver-them-tp13743.html Sent from the Apache Flink User Mailing List archive. mailing list archive at Nabble.com. |
Re: How to divide streams on key basis and deliver them
|
|
Thank you a lot Carst, Flink runs at an higher level than I imagined.
I will try with some experiments! |
«
Return to (DEPRECATED) Apache Flink User Mailing List archive.
|
1 view|%1 views
| Free forum by Nabble | Edit this page |