Hi,
I found some interesting results from comparison with spark-sql and flink. just for your information, spark-sql uses Hive QL on spark machine.
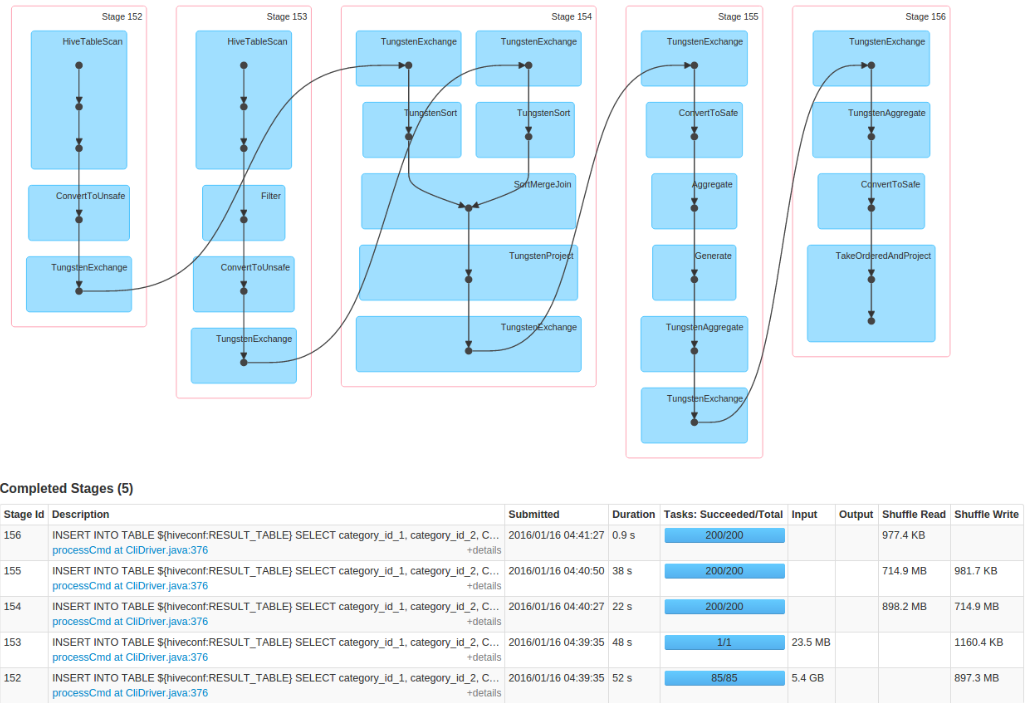
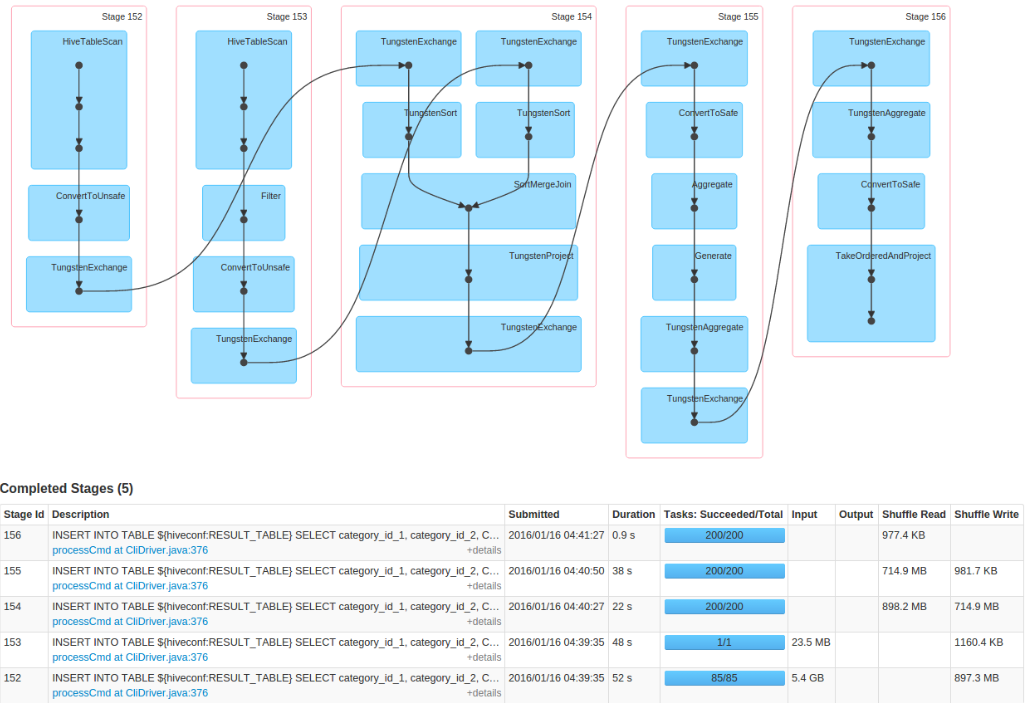
so as far as we know, when we run Flink job, the functions could be overlapped on pipelining like this picture.
likewise, spark supports pipelining as I read PPT of Spark. The function could be overlapped as well. but it seems like there is some boundary.
For example, in Flink, functions to read multiple inputs could be run together with join function like the above pic. but in Spark, to read multiple inputs can be together, but join function is seemingly sepearted to the reading functions. (you can see the starting time and duration, indicating join step is seperated)
This is why Spark is a Batch processing in memory, wherease Flink is a Streaming processing in memory?
Best,
Phil