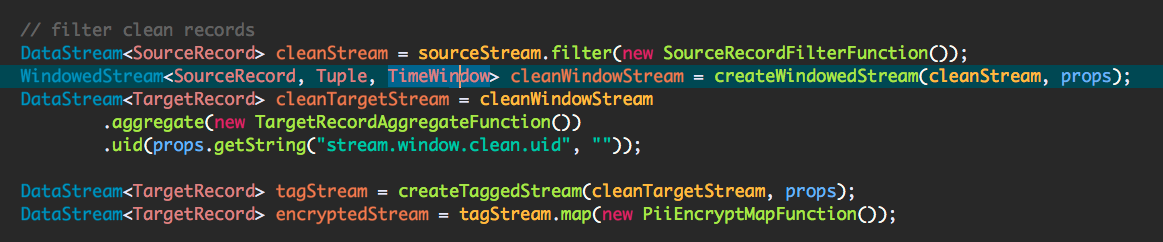
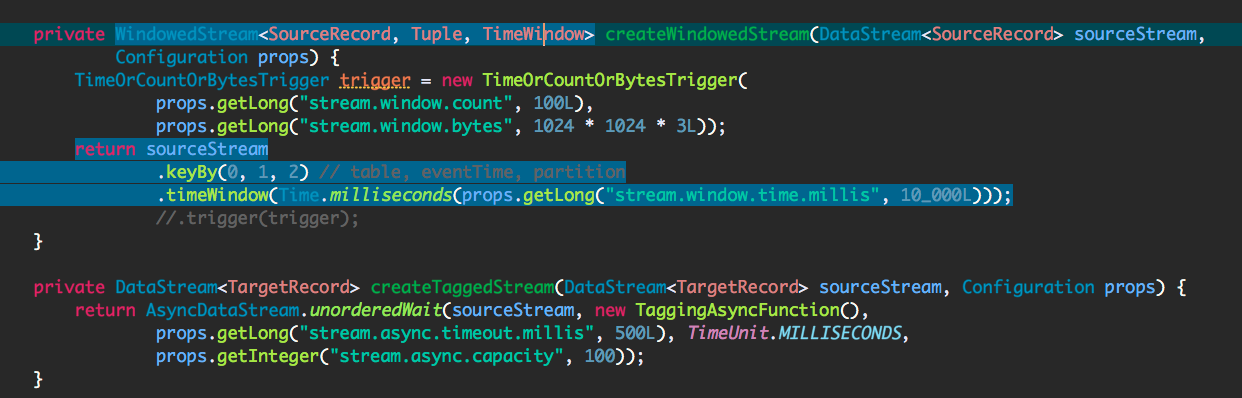
Hello all,
I am running a flink streaming job which consumes messages from Kafka and writes to S3 after performing the aggregation on source records. Something like below:
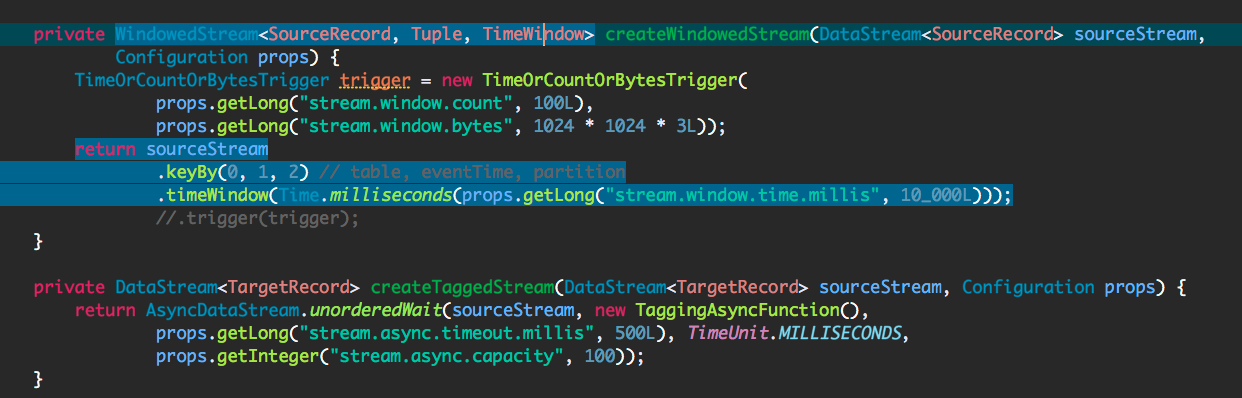
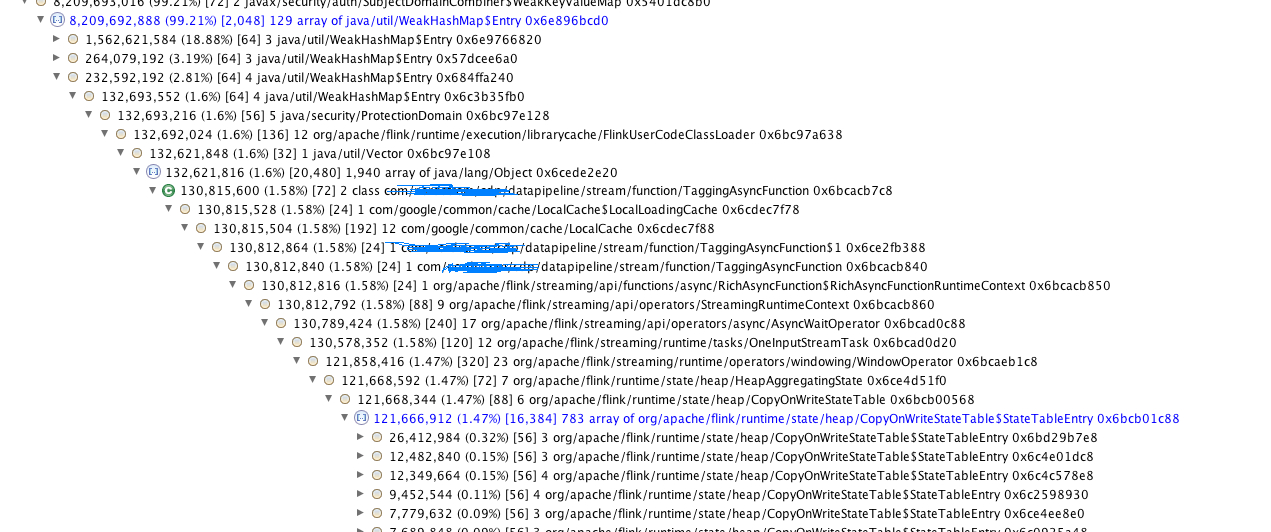
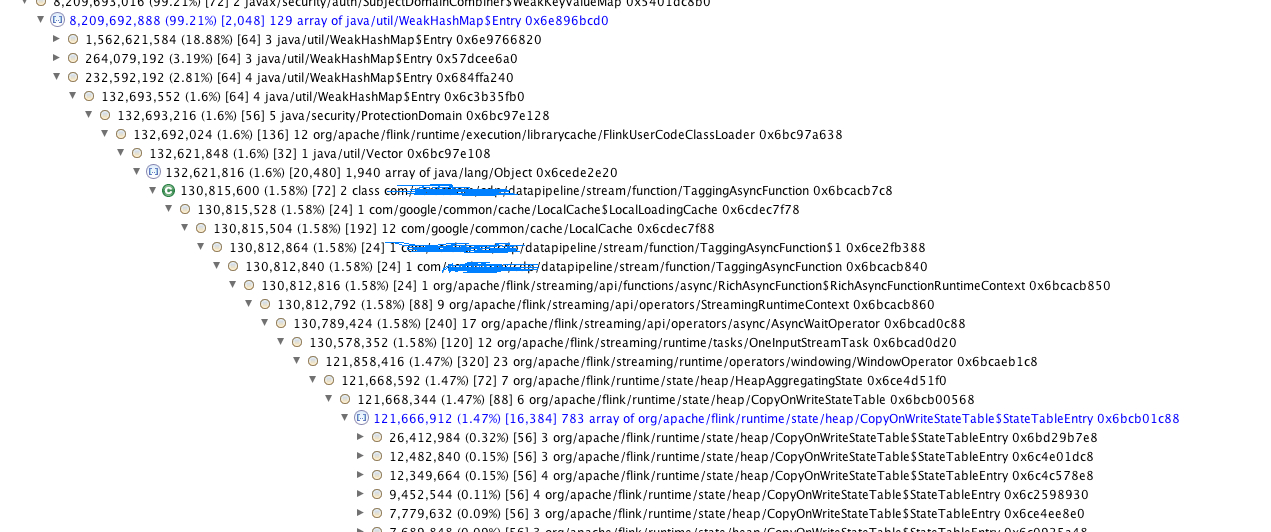
My TargetRecord is an ArrayList of byte arrays and they accumulate on the memory over time(after 4 days of continuous run). The below is the heap analysis taken on a machine which is taken before crash and 6GB/8GB is occupied by the byte array ArrayList.
Is there anything wrong I am doing here like passing my aggregate result to an async function and map function and then to sink.
Thanks for your time, much appreciated.
 ᐧ
ᐧ