Hi Flink Users,
I am running Flink 1.9 stream job on yarn - AWS EMR.
The job does operations like
stream1 - stream 2 join -> stream 3
stream 3 - stream 4 join -> sink
So basically stream1 is fast moving data, stream 2 & 4 are less frequent data. I am using KeyedProcessFunction to do the joins. We have other operations also like dynamic keying the data from stream 1 based on event type, filtering the data if the mandatory data is not available.
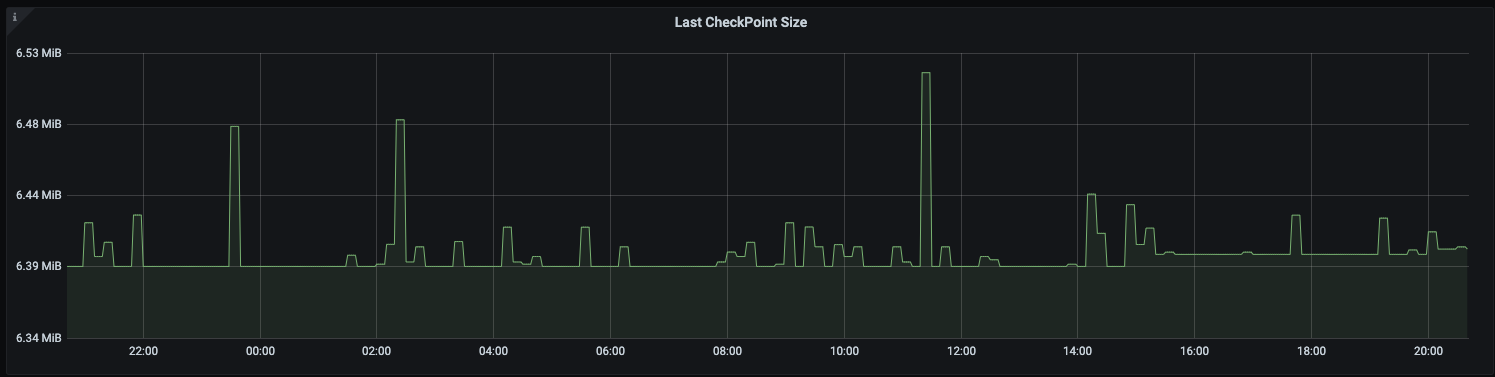
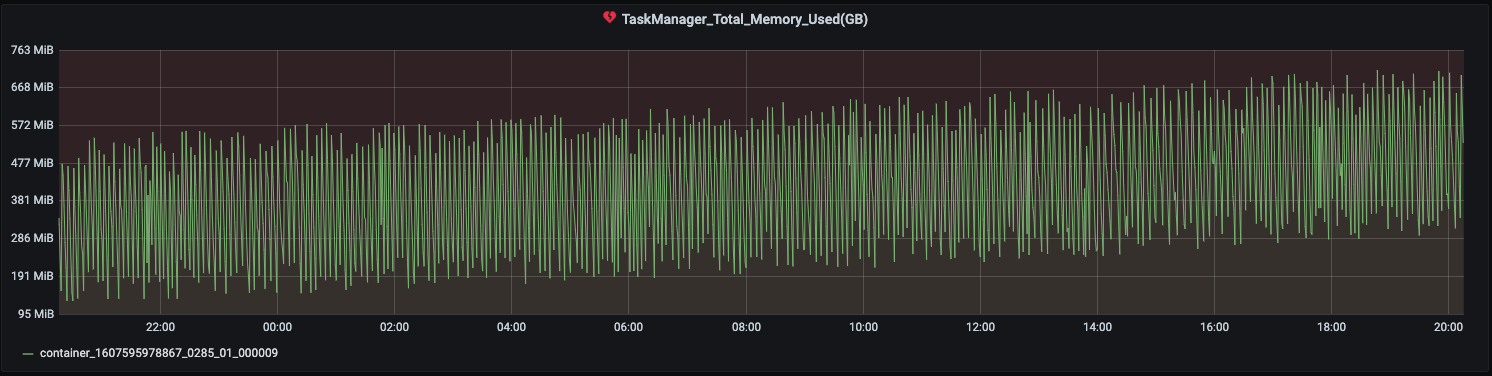
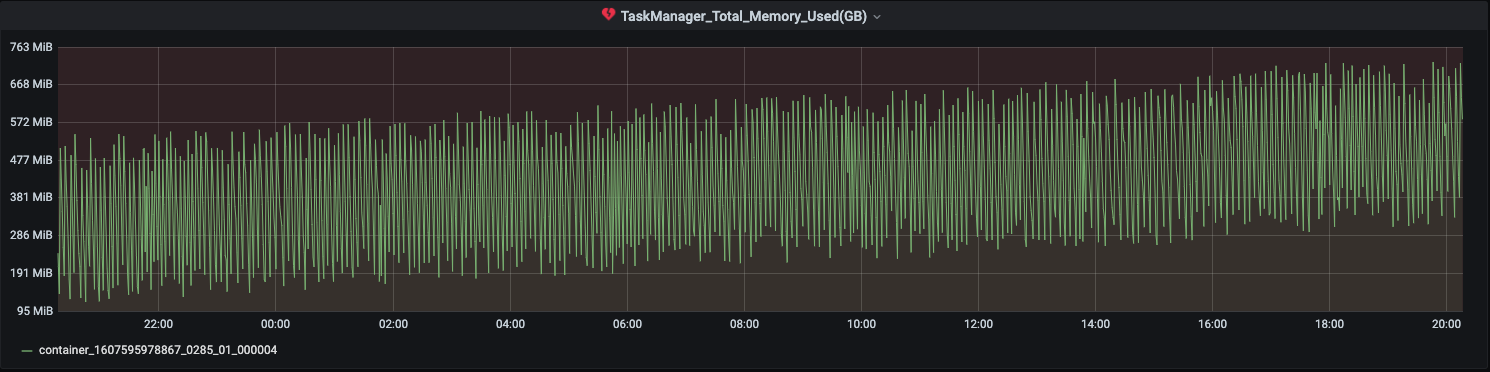
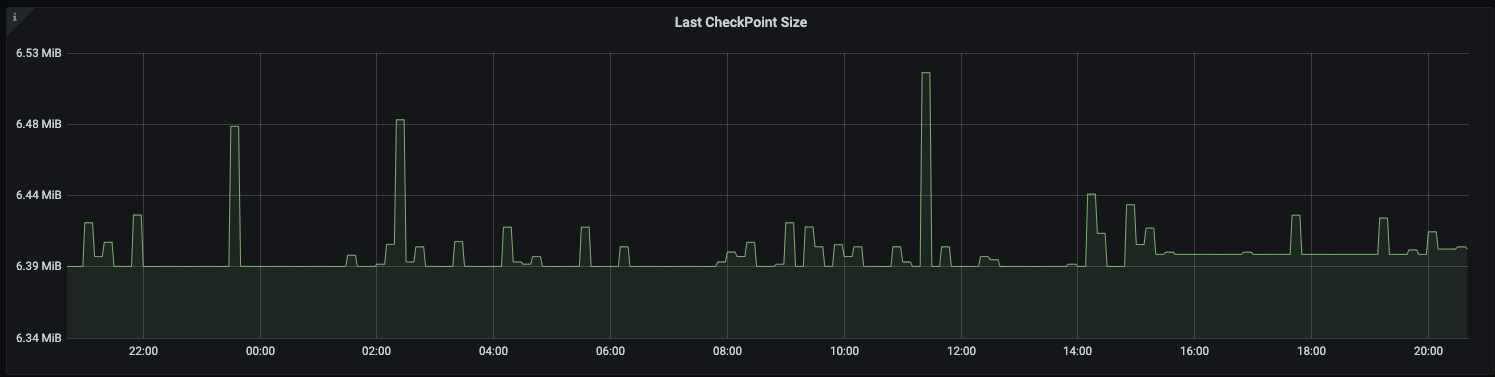
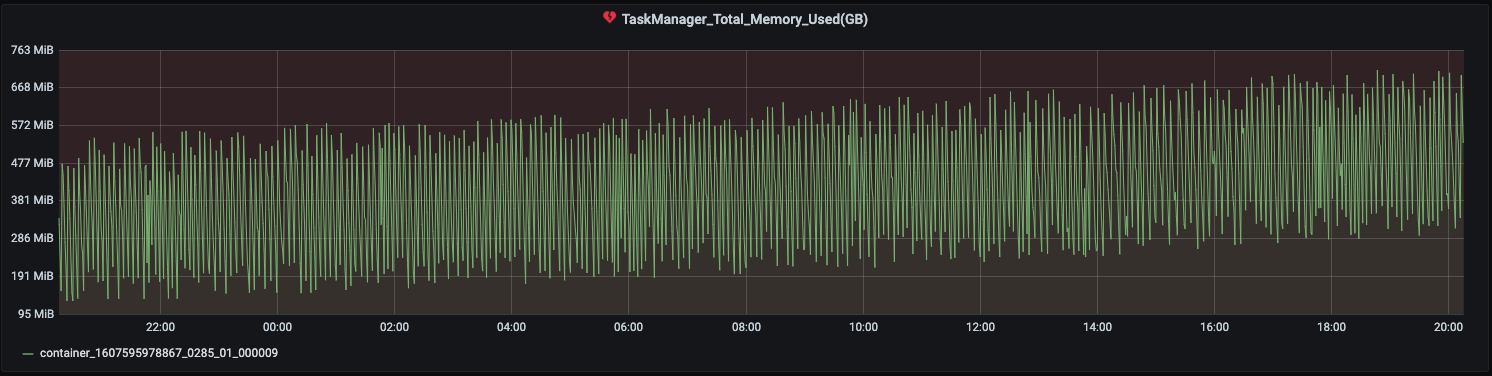
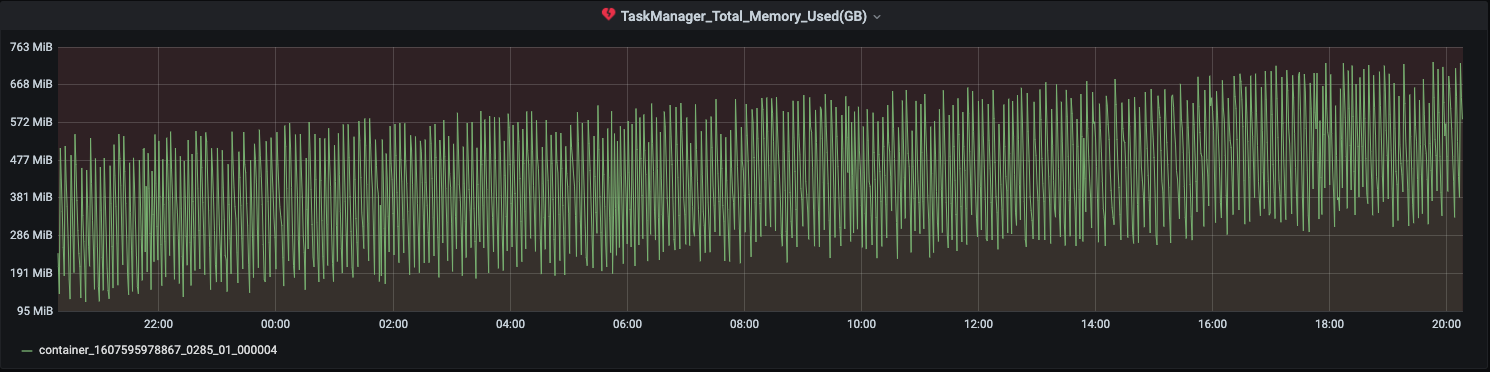
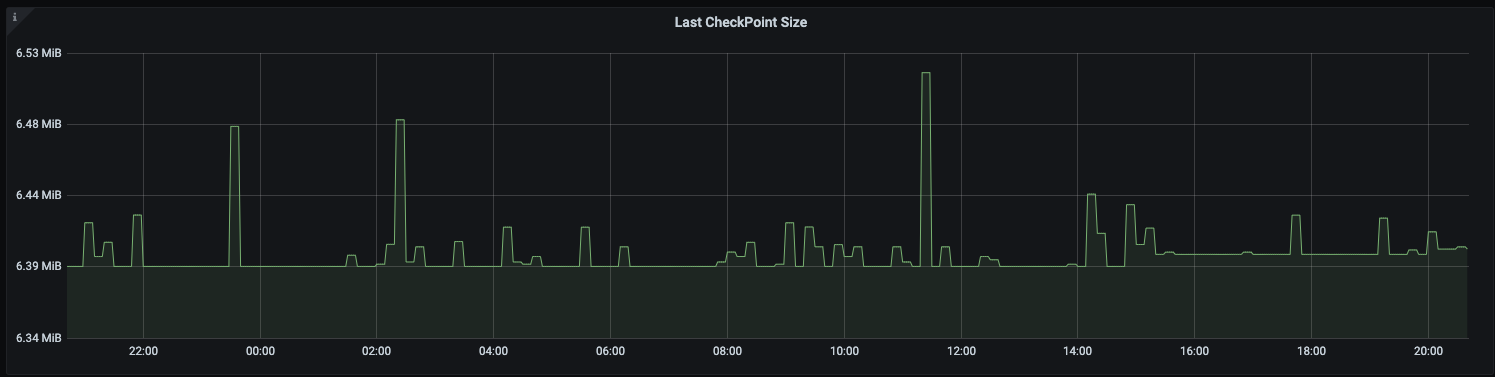
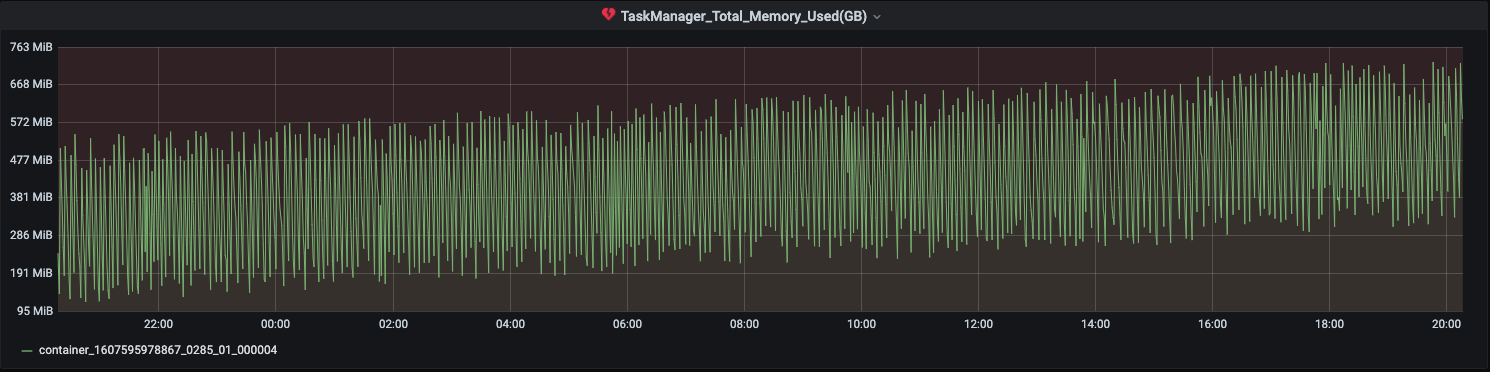
Job uses FsBackend on s3 for checkpointing. I am observing the heap usage grows over time.It is not growing that fast but gradual increase is observed. However in the same time the total checkpoint size has not increased significantly.
What could be cause for this. I understand heap dump can help but then the increase is over huge time difference what are the things that can be checked. Any pointers.
Checkpoint size -
Screenshot below for 2 of the task managers -
Thanks,
Hemant