Heap Problem with Checkpoints

Heap Problem with Checkpoints

|
Hi, in this email thread here, i tried to set up S3 as a filesystem backend for checkpoints. Now everything is working (Flink V1.5.0), but the JobMaster is accumulating Heap space, with eventually killing itself with HeapSpace OOM after several hours. If I don't enable Checkpointing, then everything is fine. I'm using the Flink S3 Shaded Libs (tried both the Hadoop and the Presto lib, no difference in this regard) from the tutorial. my checkpoint settings are this (job level):
env.enableCheckpointing(1000); env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE); env.getCheckpointConfig().setMinPauseBetweenCheckpoints(5000); env.getCheckpointConfig().setCheckpointTimeout(60000); env.getCheckpointConfig().setMaxConcurrentCheckpoints(1); Another clue why i suspect the S3 Checkpointing is that the heapspace dump contains a lot of char[] objects with some logs about S3 operations. anyone has an idea where to look further on this? Cheers -- Fabian Wollert Zalando SE E-Mail: [hidden email] Tamara-Danz-Straße 1 10243 Berlin Fax: +49 (0)30 2759 46 93 E-mail: [hidden email] Notifications of major holdings (Sec. 33, 38, 39 WpHG): +49 (0)30 2000889349 Management Board: Robert Gentz, David Schneider, Rubin Ritter Chairman of the Supervisory Board: Lothar Lanz Person responsible for providing the contents of Zalando SE acc. to Art. 55 RStV [Interstate Broadcasting Agreement]: Rubin Ritter Registered at the Local Court Charlottenburg Berlin, HRB 158855 B VAT registration number: DE 260543043 |
Re: Heap Problem with Checkpoints
|
|
Hi,
What kind of messages are those “logs about S3 operations”? Did you try to google search them? Maybe it’s a known S3 issue? Another approach is please use some heap space analyser from which you can backtrack classes that are referencing those “memory leaks” and again try to google any known memory issues. It also could just mean, that it’s not a memory leak, but you just need to allocate more heap space for your JVM (and memory consumption will stabilise at some point). Piotrek
|
Re: Heap Problem with Checkpoints
|
|
Hi Piotrek, thx a lot for your answer and sry for the late response. I was running some more tests, but i still got the same problem. I was analyzing a heap dump already with VisualVM, and thats how i got to the intention that it was some S3 logging, but seems like i was wrong. on the newer tests, the heap dump says the following (this time i used Eclipse MemoryAnalyzer): 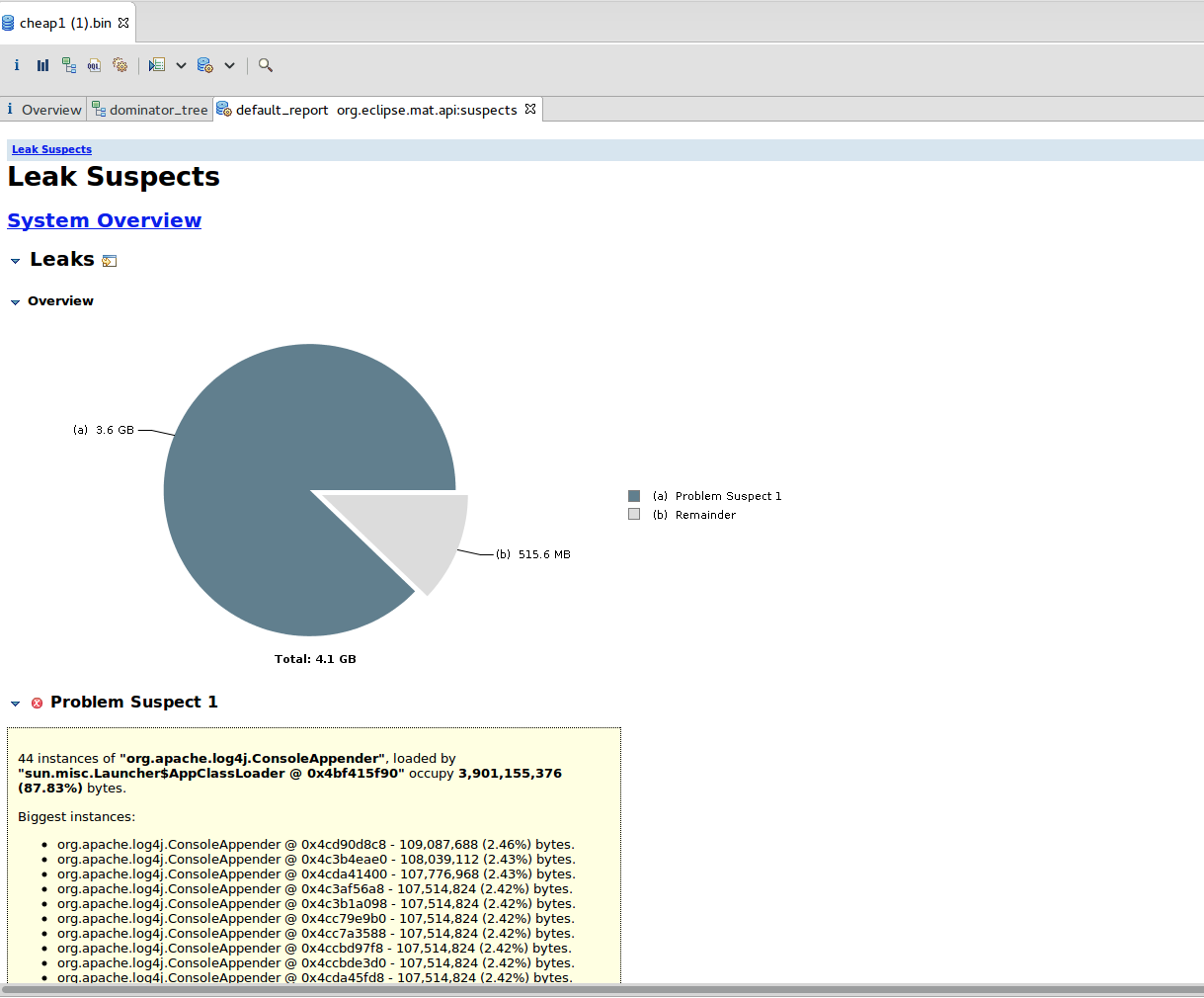 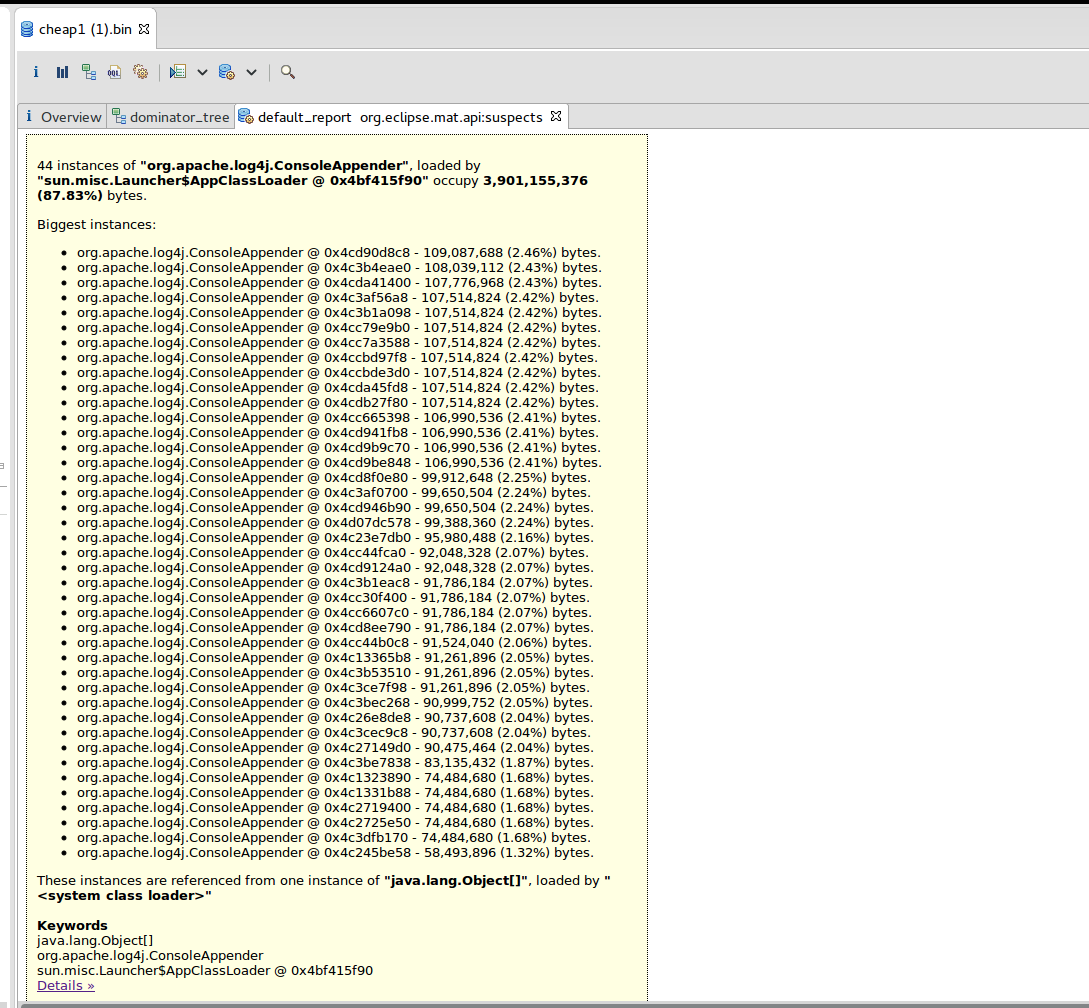 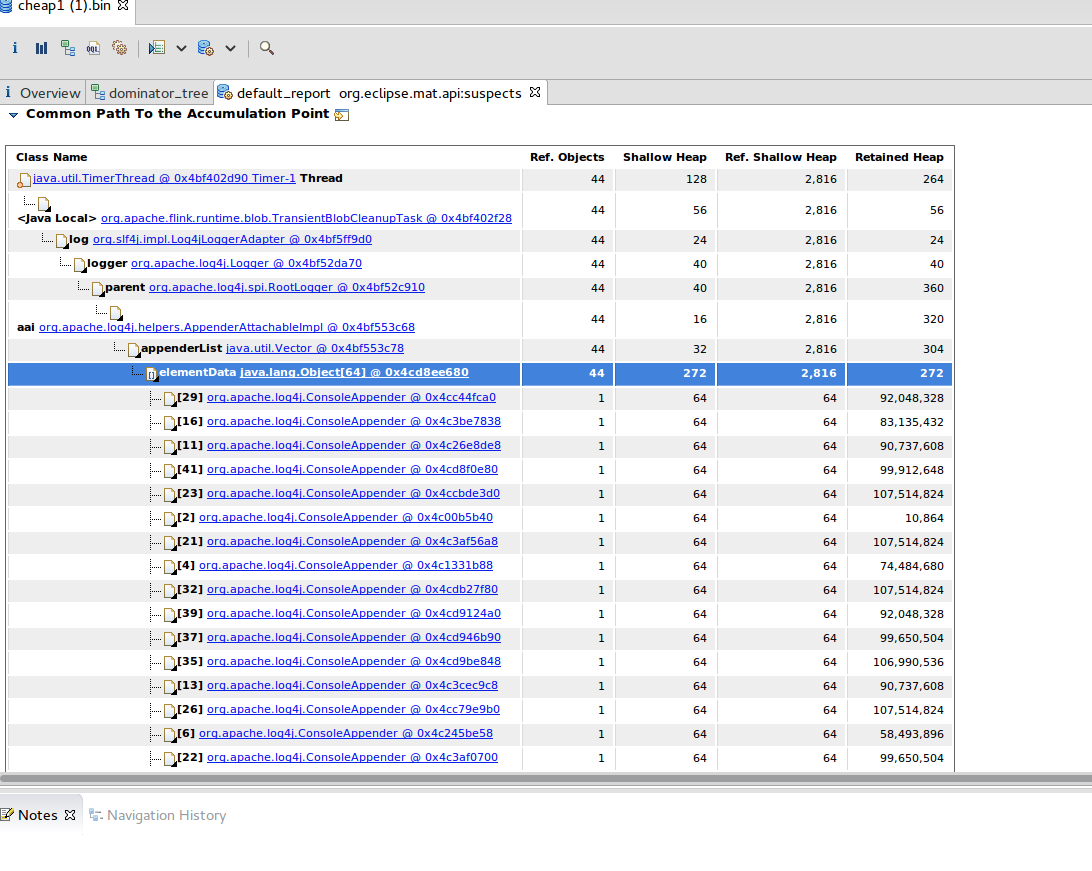 Are you aware of problems with the BlobServer not cleaning up properly? I tried also using a bigger instance, but this never stabilizes, it just keeps increasing (gave it already 10GB+ Heap) ... Cheers Am Mo., 11. Juni 2018 um 10:46 Uhr schrieb Piotr Nowojski <[hidden email]>:
|
Re: Heap Problem with Checkpoints
|
|
Hi,
Can you search the logs/std err/std output for log entries like: log.warn("Failed to locally delete blob “ …) ? I see in the code, that if file deletion fails for whatever the reason, TransientBlobCleanupTask can loop indefinitely trying to remove it over and over again. That might be ok, however it’s doing it without any back off time as fast as possible. To confirm this, could you take couple of thread dumps and check whether some thread is spinning in org.apache.flink.runtime.blob.TransientBlobCleanupTask#run ? If that’s indeed a case, the question would be why file deletion fails? Piotrek
|
Re: Heap Problem with Checkpoints
|
|
Hi Piotr, thx for the hints. I checked the logs of this stack where the previous Heap Dump was from, there are no error messages from the BlobServer, it seems to work properly. But I found another issue in my setup, I had the logging not set up properly, so everything was logging in the default console appender. I changed this now to: log4j.rootLogger=INFO, FILE log4j.logger.akka=INFO, FILE log4j.logger.org.apache.kafka=INFO, FILE log4j.logger.org.apache.hadoop=INFO, FILE log4j.logger.org.apache.zookeeper=INFO, FILE # Log all info in the given file log4j.appender.FILE=org.apache.log4j.RollingFileAppender log4j.appender.FILE.File=/opt/flink/log/flink.log log4j.appender.FILE.MaxFileSize=100MB log4j.appender.FILE.MaxBackupIndex=2 log4j.appender.FILE.layout=org.apache.log4j.PatternLayout log4j.appender.FILE.layout.ConversionPattern=%d{yyyy-MM-dd HH:mm:ss,SSS} %-5p %c:%L - %m%n # suppress the irrelevant (wrong) warnings from the netty channel handler log4j.logger.org.jboss.netty.channel.DefaultChannelPipeline=ERROR, FILE though I have this setup now, I still see memory increases, but this time it seems again like my first suspicion is valid: 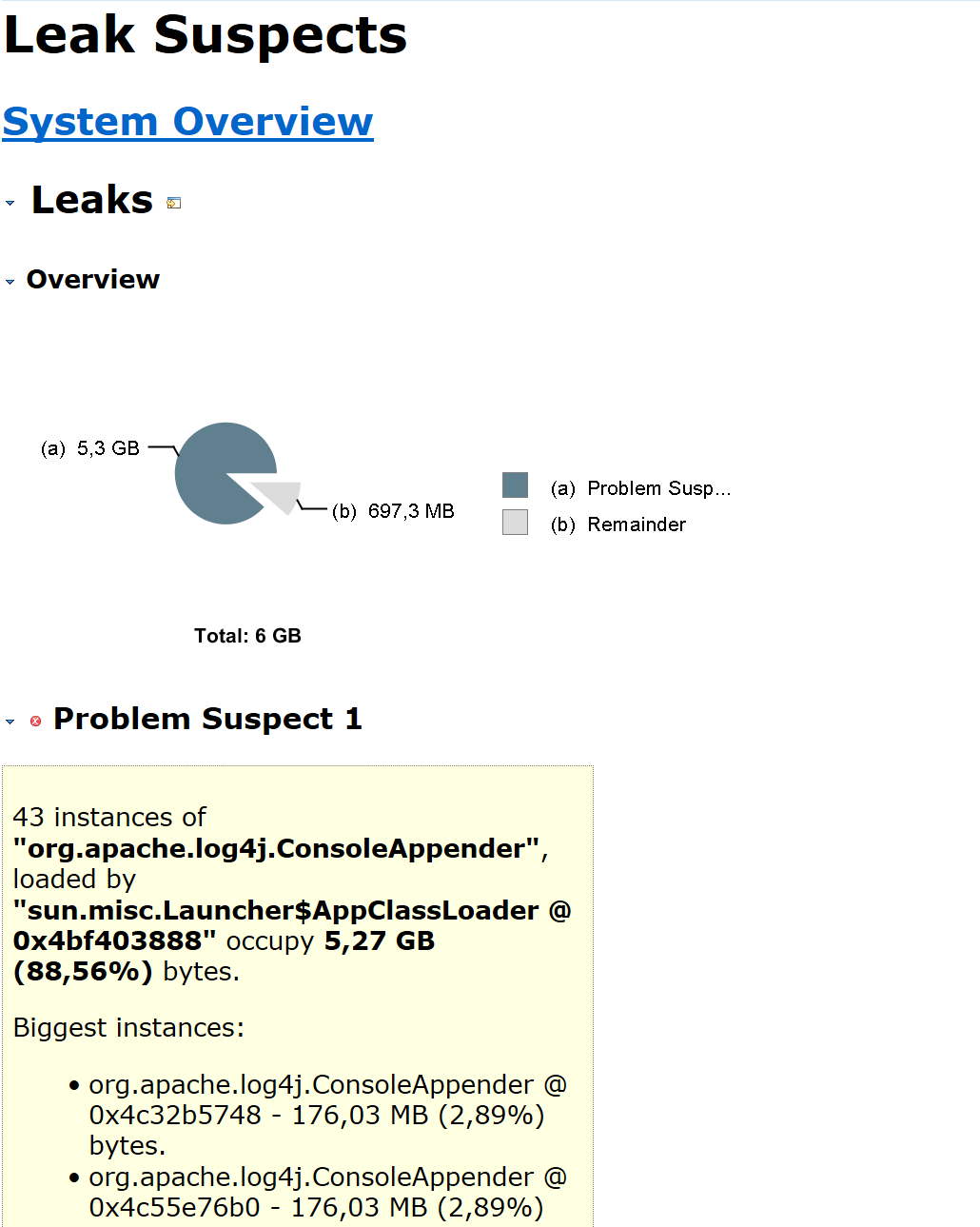 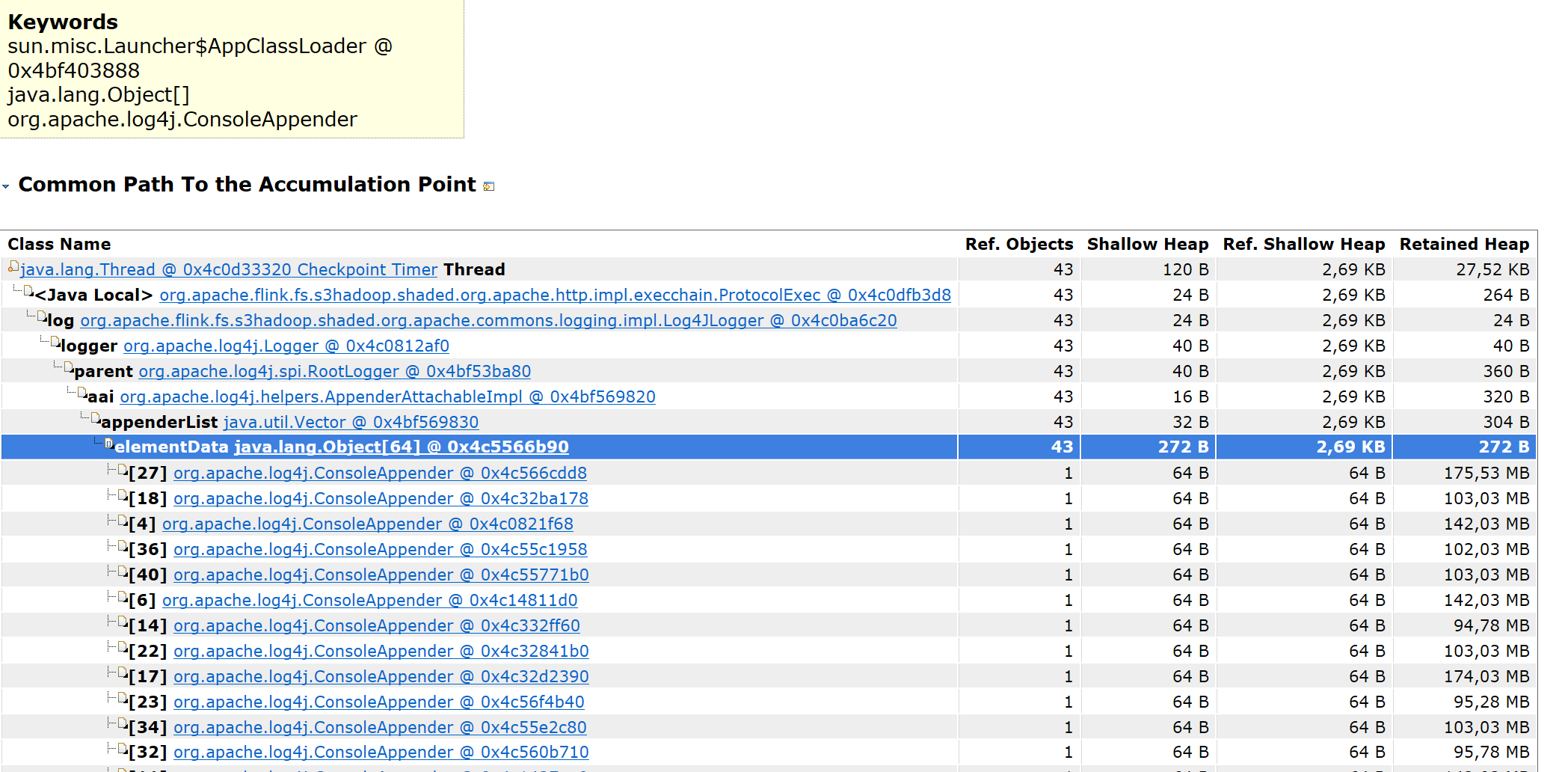 What I'm here mostly wondering now: Why is still a ConsoleAppender used although I defined RollingFileAppender? Sry for the back and forth between different parts of the code. But your help is highly appreciated! Cheers -- Fabian Wollert Zalando SE E-Mail: [hidden email] Am Di., 19. Juni 2018 um 11:55 Uhr schrieb Piotr Nowojski <[hidden email]>:
|
Re: Heap Problem with Checkpoints
|
|
Hi,
I was looking in this more, and I have couple of suspicions, but it’s still hard to tell which is correct. Could you for example place a breakpoint (or add a code there to print a stack trace) in org.apache.log4j.helpers.AppenderAttachableImpl#addAppender And check who is calling it? Since it seems like this method is responsible for the growing number of ConsoleAppenders consumption. Piotrek
|
Re: Heap Problem with Checkpoints
|
|
Btw, side questions. Could it be, that you are accessing two different Hadoop file systems (two different schemas) or even the same one from two different users (encoded in the file system URI) within the same Flink JobMaster?
If so, the answer might be this possible resource leak in Flink: Piotrek
|
Re: Heap Problem with Checkpoints
|
|
to that last one: i'm accessing S3 from one EC2 instance which has a IAM Role attached ... I'll get back to you when i have those stacktraces printed ... will have to build the project and package the custom version first, might take some time, and also some vacation is up next ... Cheers Am Mi., 20. Juni 2018 um 14:14 Uhr schrieb Piotr Nowojski <[hidden email]>:
|
Re: Heap Problem with Checkpoints
|
|
This post was updated on .
In reply to this post by Piotr Nowojski
Hello Piotr, I work with Fabian and have been investigating the memory leak
associated with issues mentioned in this thread. I took a heap dump of our master node and noticed that there was >1gb (and growing) worth of entries in the set, /files/, in class *java.io.DeleteOnExitHook*. Almost all the strings in this set look like, /tmp/hadoop-root/s3a/output-*****.tmp. This means that the checkpointing code, which uploads the data to s3, maintains it in a temporary local file, which is supposed to be deleted on exit of the JVM. In our case, the checkpointing is quite heavy and because we have a long running flink cluster, it causes this /set/ to grow unbounded, eventually cause an OOM. Please see these images: <http://apache-flink-user-mailing-list-archive.2336050.n4.nabble.com/file/t1624/Screen_Shot_2018-08-09_at_11.png>  The culprit seems to be *org.apache.hadoop.fs.s3a.S3AOutputStream*, which in-turn, calls *org.apache.hadoop.fs.s3a.S3AFileSystem.createTmpFileForWrite()*. If we follow the method call chain from there, we end up at *org.apache.hadoop.fs.LocalDirAllocator.createTmpFileForWrite()*, where we can see the temp file being created and the method deleteOnExit() being called. Maybe instead of relying on *deleteOnExit()* we can keep track of these tmp files, and as soon as they are no longer required, delete them ourself. -- Sent from: http://apache-flink-user-mailing-list-archive.2336050.n4.nabble.com/ |
Re: Heap Problem with Checkpoints
|
|
Hi,
Thanks for getting back with more information. Apparently this is a known bug of JDK since 2003 and is still not resolved: Code that is using this `deleteOnExit` is not part of a Flink, but an external library that we are using (hadoop-aws:2.8.x), so we can not fix it for them and this bug should be reported/forwarded to them (I have already done just that). More interesting S3AOutputStream is already manually deleting those files when they are not needed in `org.apache.hadoop.fs.s3a.S3AOutputStream#close`’s finally block: } finally { if (!backupFile.delete()) { LOG.warn("Could not delete temporary s3a file: {}", backupFile); } super.close(); } But this doesn’t remove the entry from DeleteOnExitHook. From what I see in the code, flink-s3-fs-presto filesystem implantation that we provide doesn’t use deleteOnExit, so if you can switch to this filesystem it would solve the problem for you. Piotrek
|
«
Return to (DEPRECATED) Apache Flink User Mailing List archive.
|
1 view|%1 views
| Free forum by Nabble | Edit this page |