Fwd: Flink memory leak

12
12

|
|
|
|
Hey Ebru, the memory usage might be increasing as long as a job is running. This is expected (also in the case of multiple running jobs). The screenshots are not helpful in that regard. :-( What kind of stateful operations are you using? Depending on your use case, you have to manually call `clear()` on the state instance in order to release the managed state. Best, Ufuk On Tue, Nov 7, 2017 at 12:43 PM, ebru <[hidden email]> wrote:
|

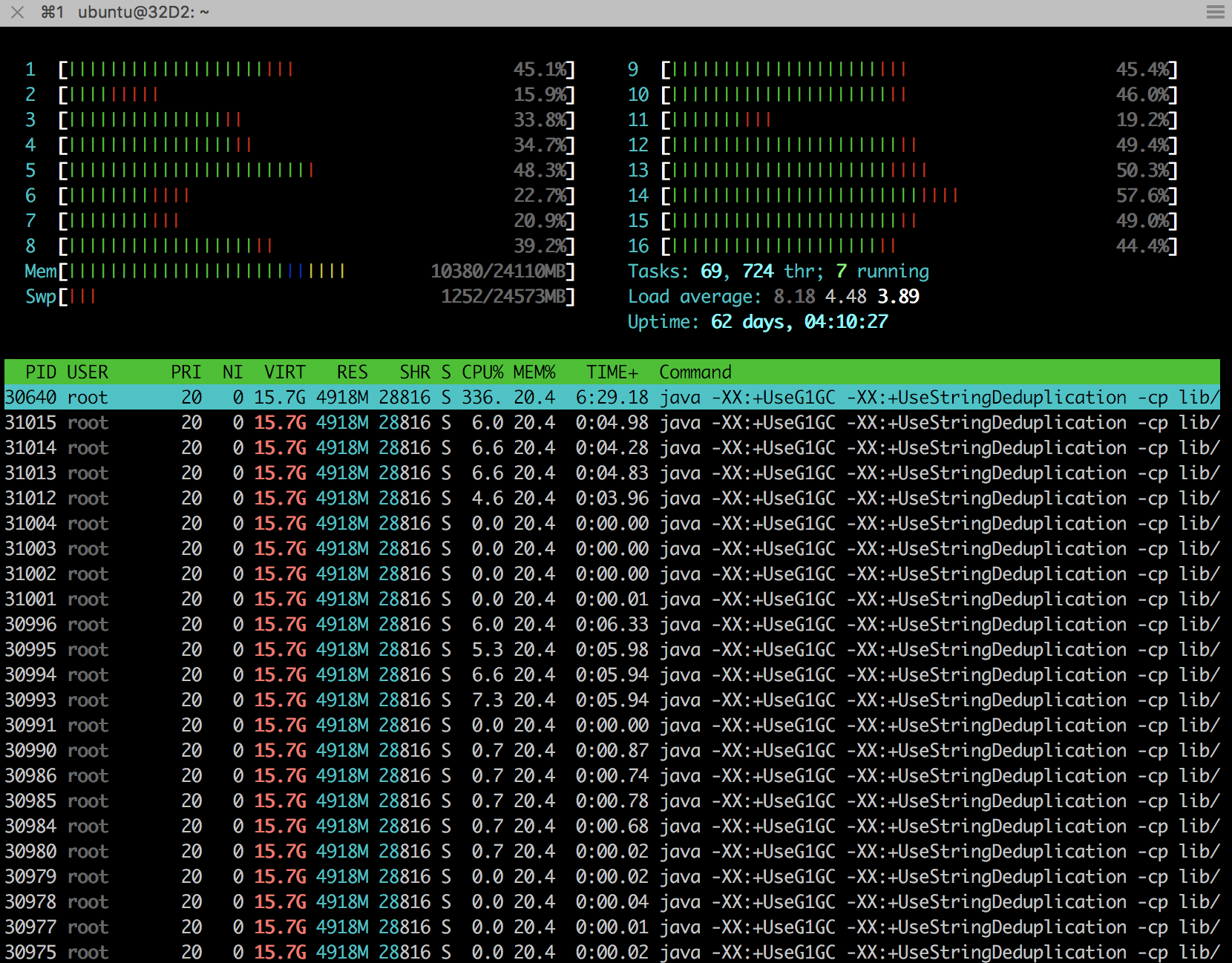
|
|
Hi Ufuk,
We don’t explicitly define any state descriptor. We only use map and filters operator. We thought that gc handle clearing the flink’s internal states. So how can we manage the memory if it is always increasing? - Ebru
|
|
|
Do you use any windowing? If yes, could you please share that code? If
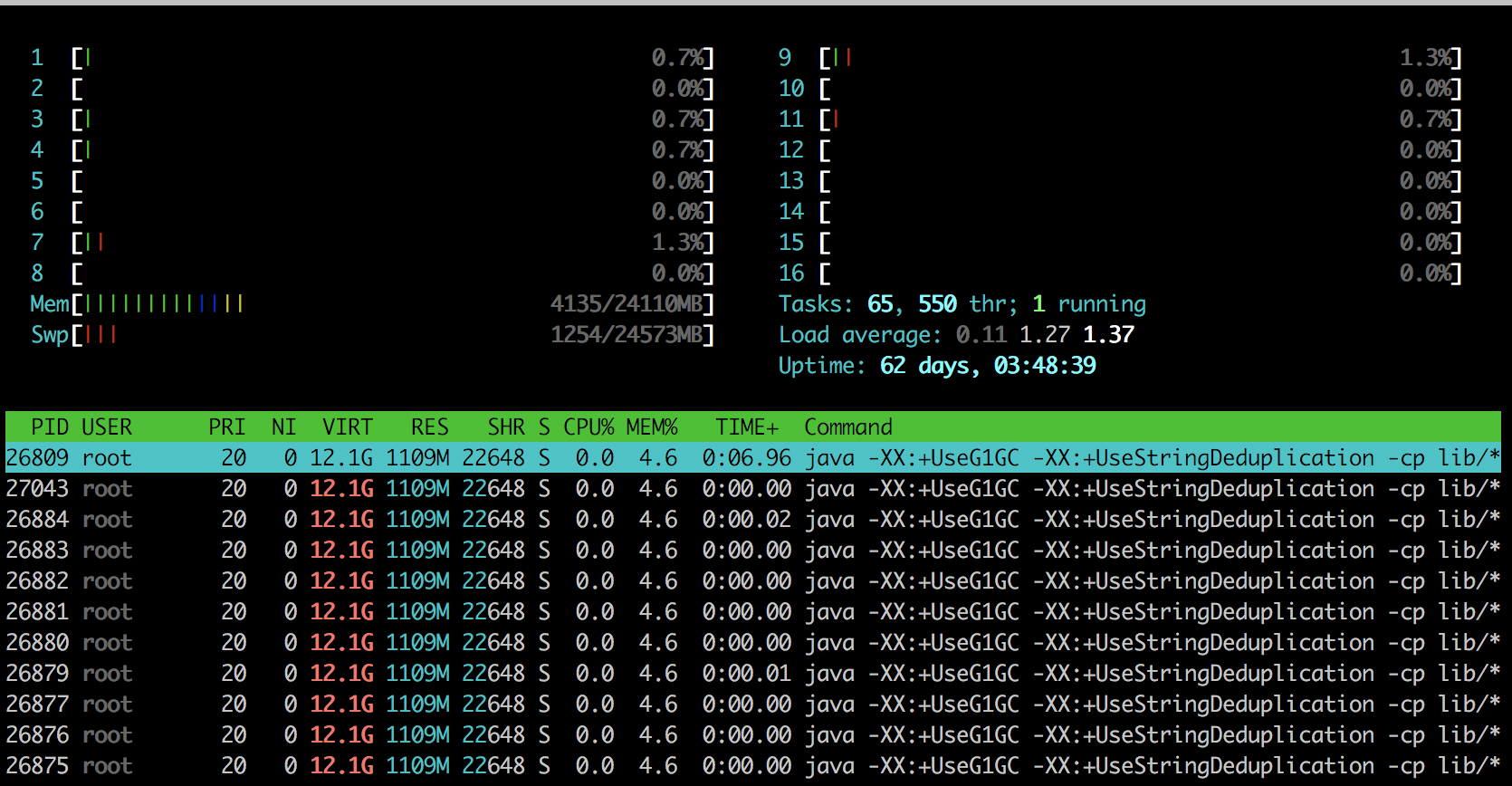
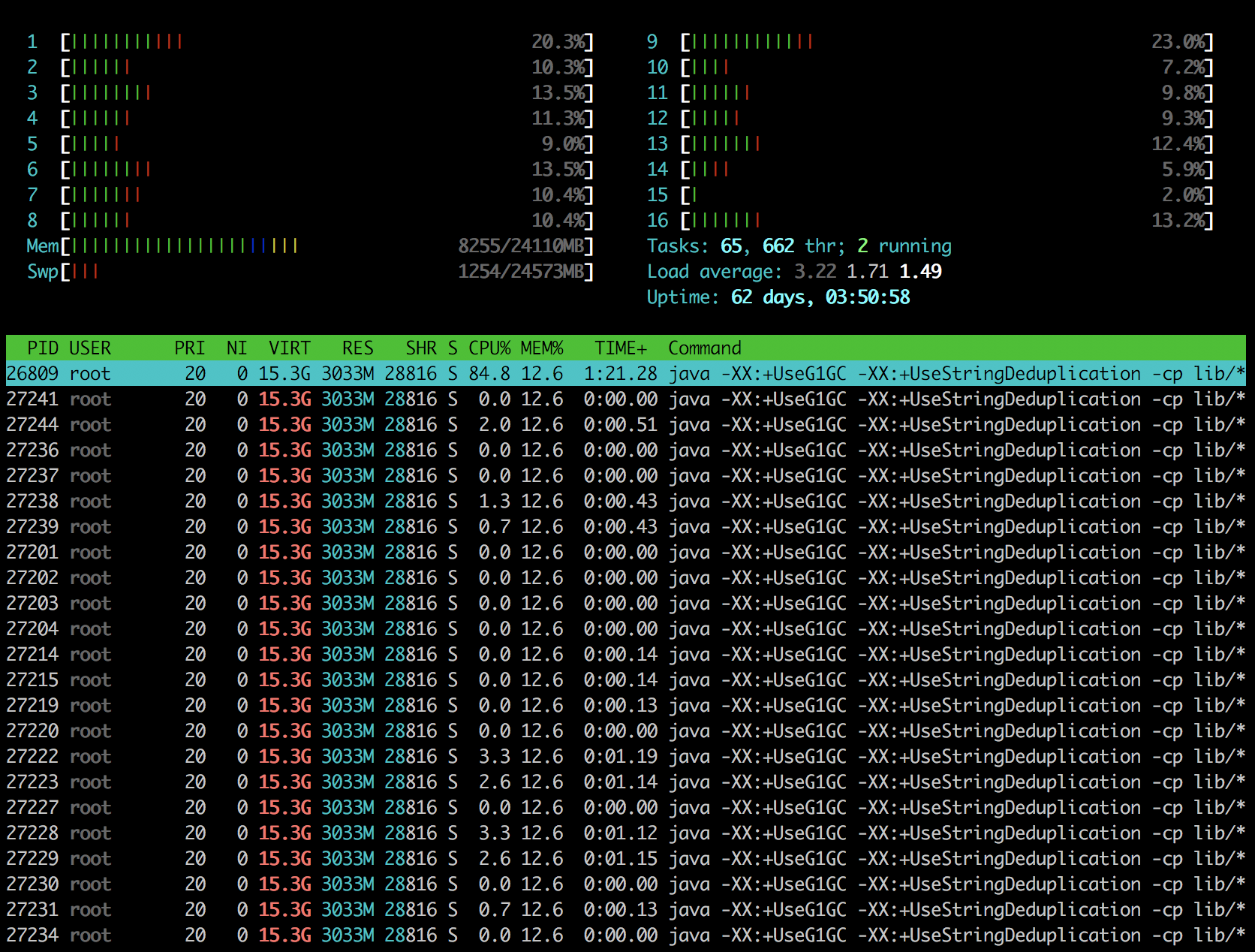
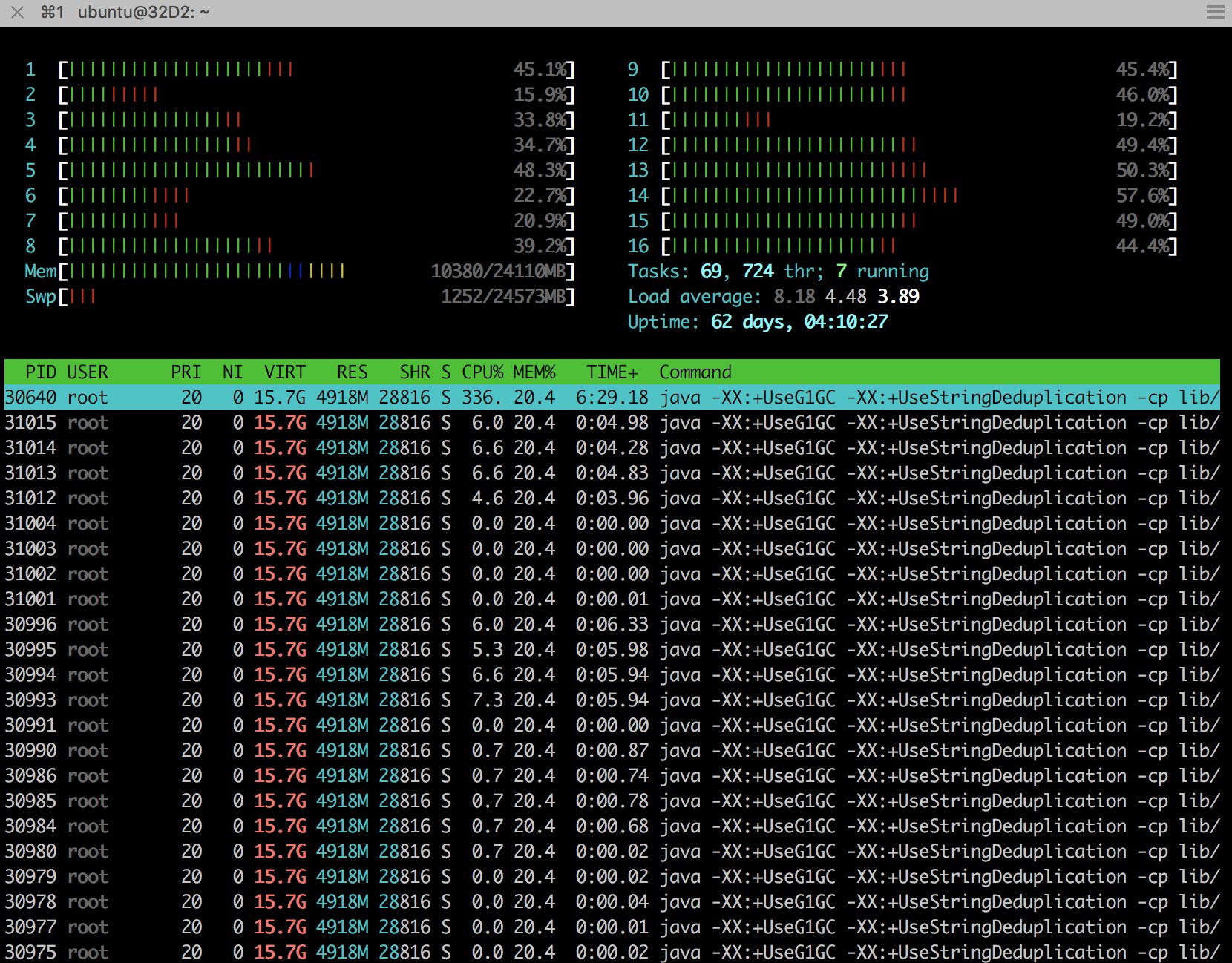
there is no stateful operation at all, it's strange where the list state instances are coming from. On Tue, Nov 7, 2017 at 2:35 PM, ebru <[hidden email]> wrote: > Hi Ufuk, > > We don’t explicitly define any state descriptor. We only use map and filters > operator. We thought that gc handle clearing the flink’s internal states. > So how can we manage the memory if it is always increasing? > > - Ebru > > On 7 Nov 2017, at 16:23, Ufuk Celebi <[hidden email]> wrote: > > Hey Ebru, the memory usage might be increasing as long as a job is running. > This is expected (also in the case of multiple running jobs). The > screenshots are not helpful in that regard. :-( > > What kind of stateful operations are you using? Depending on your use case, > you have to manually call `clear()` on the state instance in order to > release the managed state. > > Best, > > Ufuk > > On Tue, Nov 7, 2017 at 12:43 PM, ebru <[hidden email]> wrote: >> >> >> >> Begin forwarded message: >> >> From: ebru <[hidden email]> >> Subject: Re: Flink memory leak >> Date: 7 November 2017 at 14:09:17 GMT+3 >> To: Ufuk Celebi <[hidden email]> >> >> Hi Ufuk, >> >> There are there snapshots of htop output. >> 1. snapshot is initial state. >> 2. snapshot is after submitted one job. >> 3. Snapshot is the output of the one job with 15000 EPS. And the memory >> usage is always increasing over time. >> >> >> >> >> <1.png><2.png><3.png> >> >> On 7 Nov 2017, at 13:34, Ufuk Celebi <[hidden email]> wrote: >> >> Hey Ebru, >> >> let me pull in Aljoscha (CC'd) who might have an idea what's causing this. >> >> Since multiple jobs are running, it will be hard to understand to >> which job the state descriptors from the heap snapshot belong to. >> - Is it possible to isolate the problem and reproduce the behaviour >> with only a single job? >> >> – Ufuk >> >> >> On Tue, Nov 7, 2017 at 10:27 AM, ÇETİNKAYA EBRU ÇETİNKAYA EBRU >> <[hidden email]> wrote: >> >> Hi, >> >> We are using Flink 1.3.1 in production, we have one job manager and 3 task >> managers in standalone mode. Recently, we've noticed that we have memory >> related problems. We use docker container to serve Flink cluster. We have >> 300 slots and 20 jobs are running with parallelism of 10. Also the job >> count >> may be change over time. Taskmanager memory usage always increases. After >> job cancelation this memory usage doesn't decrease. We've tried to >> investigate the problem and we've got the task manager jvm heap snapshot. >> According to the jam heap analysis, possible memory leak was Flink list >> state descriptor. But we are not sure that is the cause of our memory >> problem. How can we solve the problem? >> >> >> > > |
|
|
I agree with Ufuk, it would be helpful to know what stateful operations are in the jobs (including windowing).
> On 7. Nov 2017, at 14:53, Ufuk Celebi <[hidden email]> wrote: > > Do you use any windowing? If yes, could you please share that code? If > there is no stateful operation at all, it's strange where the list > state instances are coming from. > > On Tue, Nov 7, 2017 at 2:35 PM, ebru <[hidden email]> wrote: >> Hi Ufuk, >> >> We don’t explicitly define any state descriptor. We only use map and filters >> operator. We thought that gc handle clearing the flink’s internal states. >> So how can we manage the memory if it is always increasing? >> >> - Ebru >> >> On 7 Nov 2017, at 16:23, Ufuk Celebi <[hidden email]> wrote: >> >> Hey Ebru, the memory usage might be increasing as long as a job is running. >> This is expected (also in the case of multiple running jobs). The >> screenshots are not helpful in that regard. :-( >> >> What kind of stateful operations are you using? Depending on your use case, >> you have to manually call `clear()` on the state instance in order to >> release the managed state. >> >> Best, >> >> Ufuk >> >> On Tue, Nov 7, 2017 at 12:43 PM, ebru <[hidden email]> wrote: >>> >>> >>> >>> Begin forwarded message: >>> >>> From: ebru <[hidden email]> >>> Subject: Re: Flink memory leak >>> Date: 7 November 2017 at 14:09:17 GMT+3 >>> To: Ufuk Celebi <[hidden email]> >>> >>> Hi Ufuk, >>> >>> There are there snapshots of htop output. >>> 1. snapshot is initial state. >>> 2. snapshot is after submitted one job. >>> 3. Snapshot is the output of the one job with 15000 EPS. And the memory >>> usage is always increasing over time. >>> >>> >>> >>> >>> <1.png><2.png><3.png> >>> >>> On 7 Nov 2017, at 13:34, Ufuk Celebi <[hidden email]> wrote: >>> >>> Hey Ebru, >>> >>> let me pull in Aljoscha (CC'd) who might have an idea what's causing this. >>> >>> Since multiple jobs are running, it will be hard to understand to >>> which job the state descriptors from the heap snapshot belong to. >>> - Is it possible to isolate the problem and reproduce the behaviour >>> with only a single job? >>> >>> – Ufuk >>> >>> >>> On Tue, Nov 7, 2017 at 10:27 AM, ÇETİNKAYA EBRU ÇETİNKAYA EBRU >>> <[hidden email]> wrote: >>> >>> Hi, >>> >>> We are using Flink 1.3.1 in production, we have one job manager and 3 task >>> managers in standalone mode. Recently, we've noticed that we have memory >>> related problems. We use docker container to serve Flink cluster. We have >>> 300 slots and 20 jobs are running with parallelism of 10. Also the job >>> count >>> may be change over time. Taskmanager memory usage always increases. After >>> job cancelation this memory usage doesn't decrease. We've tried to >>> investigate the problem and we've got the task manager jvm heap snapshot. >>> According to the jam heap analysis, possible memory leak was Flink list >>> state descriptor. But we are not sure that is the cause of our memory >>> problem. How can we solve the problem? >>> >>> >>> >> >> |
|
|
In reply to this post by Ufuk Celebi
On 2017-11-07 16:53, Ufuk Celebi wrote:
> Do you use any windowing? If yes, could you please share that code? If > there is no stateful operation at all, it's strange where the list > state instances are coming from. > > On Tue, Nov 7, 2017 at 2:35 PM, ebru <[hidden email]> > wrote: >> Hi Ufuk, >> >> We don’t explicitly define any state descriptor. We only use map and >> filters >> operator. We thought that gc handle clearing the flink’s internal >> states. >> So how can we manage the memory if it is always increasing? >> >> - Ebru >> >> On 7 Nov 2017, at 16:23, Ufuk Celebi <[hidden email]> wrote: >> >> Hey Ebru, the memory usage might be increasing as long as a job is >> running. >> This is expected (also in the case of multiple running jobs). The >> screenshots are not helpful in that regard. :-( >> >> What kind of stateful operations are you using? Depending on your use >> case, >> you have to manually call `clear()` on the state instance in order to >> release the managed state. >> >> Best, >> >> Ufuk >> >> On Tue, Nov 7, 2017 at 12:43 PM, ebru <[hidden email]> >> wrote: >>> >>> >>> >>> Begin forwarded message: >>> >>> From: ebru <[hidden email]> >>> Subject: Re: Flink memory leak >>> Date: 7 November 2017 at 14:09:17 GMT+3 >>> To: Ufuk Celebi <[hidden email]> >>> >>> Hi Ufuk, >>> >>> There are there snapshots of htop output. >>> 1. snapshot is initial state. >>> 2. snapshot is after submitted one job. >>> 3. Snapshot is the output of the one job with 15000 EPS. And the >>> memory >>> usage is always increasing over time. >>> >>> >>> >>> >>> <1.png><2.png><3.png> >>> >>> On 7 Nov 2017, at 13:34, Ufuk Celebi <[hidden email]> wrote: >>> >>> Hey Ebru, >>> >>> let me pull in Aljoscha (CC'd) who might have an idea what's causing >>> this. >>> >>> Since multiple jobs are running, it will be hard to understand to >>> which job the state descriptors from the heap snapshot belong to. >>> - Is it possible to isolate the problem and reproduce the behaviour >>> with only a single job? >>> >>> – Ufuk >>> >>> >>> On Tue, Nov 7, 2017 at 10:27 AM, ÇETİNKAYA EBRU ÇETİNKAYA EBRU >>> <[hidden email]> wrote: >>> >>> Hi, >>> >>> We are using Flink 1.3.1 in production, we have one job manager and 3 >>> task >>> managers in standalone mode. Recently, we've noticed that we have >>> memory >>> related problems. We use docker container to serve Flink cluster. We >>> have >>> 300 slots and 20 jobs are running with parallelism of 10. Also the >>> job >>> count >>> may be change over time. Taskmanager memory usage always increases. >>> After >>> job cancelation this memory usage doesn't decrease. We've tried to >>> investigate the problem and we've got the task manager jvm heap >>> snapshot. >>> According to the jam heap analysis, possible memory leak was Flink >>> list >>> state descriptor. But we are not sure that is the cause of our memory >>> problem. How can we solve the problem? >>> >>> >>> >> We have two types of Flink job. One has no state full operator >> contains only maps and filters and the other has time window with >> count trigger. * Then, we analysed the jvm heap snapshot when the flink job that has no state full operator is running. And according to the results, leak suspect was NetworkBufferPool (image 2) * Last analys, there were both two types of jobs running and leak suspect was again NetworkBufferPool. (image 3) In our system jobs are regularly cancelled and resubmitted so we noticed that when job is submitted some amount of memory allocated and after cancelation this allocated memory never freed. So over time memory usage is always increasing and exceeded the limits. >> |
|
|
We also have the same problem in production. At the moment the solution is to restart the entire Flink cluster after every job..
We've tried to reproduce this problem with a test (see https://issues.apache.org/jira/browse/FLINK-7845) but we don't know whether the error produced by the test and the leak are correlated.. Best, Flavio On Wed, Nov 8, 2017 at 9:51 AM, ÇETİNKAYA EBRU ÇETİNKAYA EBRU <[hidden email]> wrote: On 2017-11-07 16:53, Ufuk Celebi wrote: |
|
|
@Nico & @Piotr Could you please have a look at this? You both recently worked on the network stack and might be most familiar with this.
|
|
|
Hi, We have been facing a similar problem. We have tried some different configurations, as proposed in other email thread by Flavio and Kien, but it didn't work. We have a workaround similar to the one that Flavio has, we restart the taskmanagers once they reach a memory threshold. We created a small test to remove all of our dependencies and leave only flink native libraries. This test reads data from a Kafka topic and writes it back to another topic in Kafka. We cancel the job and start another every 5 seconds. After ~30 minutes of doing this process, the cluster reaches the OS memory limit and dies. Currently, we have a test cluster with 8 workers and 8 task slots per node. We have one job that uses 56 slots, and we cannot execute that job 5 times in a row because the whole cluster dies. If you want, we can publish our test job. Regards, On 8 November 2017 at 11:20, Aljoscha Krettek <[hidden email]> wrote:
|
|
|
Hi Javier, Which configurations did you try?
-Ebru
|
|
|
Hi Ebru and Javier, Yes, if you could share this example job it would be helpful. Ebru: could you explain in a little more details how does your Job(s) look like? Could you post some code? If you are just using maps and filters there shouldn’t be any network transfers involved, aside from Source and Sink functions. Piotrek
|
|
|
On 2017-11-08 15:20, Piotr Nowojski wrote:
> Hi Ebru and Javier, > > Yes, if you could share this example job it would be helpful. > > Ebru: could you explain in a little more details how does your Job(s) > look like? Could you post some code? If you are just using maps and > filters there shouldn’t be any network transfers involved, aside > from Source and Sink functions. > > Piotrek > >> On 8 Nov 2017, at 12:54, ebru <[hidden email]> wrote: >> >> Hi Javier, >> >> It would be helpful if you share your test job with us. >> Which configurations did you try? >> >> -Ebru >> >> On 8 Nov 2017, at 14:43, Javier Lopez <[hidden email]> >> wrote: >> >> Hi, >> >> We have been facing a similar problem. We have tried some different >> configurations, as proposed in other email thread by Flavio and >> Kien, but it didn't work. We have a workaround similar to the one >> that Flavio has, we restart the taskmanagers once they reach a >> memory threshold. We created a small test to remove all of our >> dependencies and leave only flink native libraries. This test reads >> data from a Kafka topic and writes it back to another topic in >> Kafka. We cancel the job and start another every 5 seconds. After >> ~30 minutes of doing this process, the cluster reaches the OS memory >> limit and dies. >> >> Currently, we have a test cluster with 8 workers and 8 task slots >> per node. We have one job that uses 56 slots, and we cannot execute >> that job 5 times in a row because the whole cluster dies. If you >> want, we can publish our test job. >> >> Regards, >> >> On 8 November 2017 at 11:20, Aljoscha Krettek <[hidden email]> >> wrote: >> >> @Nico & @Piotr Could you please have a look at this? You both >> recently worked on the network stack and might be most familiar with >> this. >> >> On 8. Nov 2017, at 10:25, Flavio Pompermaier <[hidden email]> >> wrote: >> >> We also have the same problem in production. At the moment the >> solution is to restart the entire Flink cluster after every job.. >> We've tried to reproduce this problem with a test (see >> https://issues.apache.org/jira/browse/FLINK-7845 [1]) but we don't >> know whether the error produced by the test and the leak are >> correlated.. >> >> Best, >> Flavio >> >> On Wed, Nov 8, 2017 at 9:51 AM, ÇETİNKAYA EBRU ÇETİNKAYA EBRU >> <[hidden email]> wrote: >> On 2017-11-07 16:53, Ufuk Celebi wrote: >> Do you use any windowing? If yes, could you please share that code? >> If >> there is no stateful operation at all, it's strange where the list >> state instances are coming from. >> >> On Tue, Nov 7, 2017 at 2:35 PM, ebru <[hidden email]> >> wrote: >> Hi Ufuk, >> >> We don’t explicitly define any state descriptor. We only use map >> and filters >> operator. We thought that gc handle clearing the flink’s internal >> states. >> So how can we manage the memory if it is always increasing? >> >> - Ebru >> >> On 7 Nov 2017, at 16:23, Ufuk Celebi <[hidden email]> wrote: >> >> Hey Ebru, the memory usage might be increasing as long as a job is >> running. >> This is expected (also in the case of multiple running jobs). The >> screenshots are not helpful in that regard. :-( >> >> What kind of stateful operations are you using? Depending on your >> use case, >> you have to manually call `clear()` on the state instance in order >> to >> release the managed state. >> >> Best, >> >> Ufuk >> >> On Tue, Nov 7, 2017 at 12:43 PM, ebru >> <[hidden email]> wrote: >> >> Begin forwarded message: >> >> From: ebru <[hidden email]> >> Subject: Re: Flink memory leak >> Date: 7 November 2017 at 14:09:17 GMT+3 >> To: Ufuk Celebi <[hidden email]> >> >> Hi Ufuk, >> >> There are there snapshots of htop output. >> 1. snapshot is initial state. >> 2. snapshot is after submitted one job. >> 3. Snapshot is the output of the one job with 15000 EPS. And the >> memory >> usage is always increasing over time. >> >> <1.png><2.png><3.png> >> >> On 7 Nov 2017, at 13:34, Ufuk Celebi <[hidden email]> wrote: >> >> Hey Ebru, >> >> let me pull in Aljoscha (CC'd) who might have an idea what's causing >> this. >> >> Since multiple jobs are running, it will be hard to understand to >> which job the state descriptors from the heap snapshot belong to. >> - Is it possible to isolate the problem and reproduce the behaviour >> with only a single job? >> >> – Ufuk >> >> On Tue, Nov 7, 2017 at 10:27 AM, ÇETİNKAYA EBRU ÇETİNKAYA EBRU >> <[hidden email]> wrote: >> >> Hi, >> >> We are using Flink 1.3.1 in production, we have one job manager and >> 3 task >> managers in standalone mode. Recently, we've noticed that we have >> memory >> related problems. We use docker container to serve Flink cluster. We >> have >> 300 slots and 20 jobs are running with parallelism of 10. Also the >> job >> count >> may be change over time. Taskmanager memory usage always increases. >> After >> job cancelation this memory usage doesn't decrease. We've tried to >> investigate the problem and we've got the task manager jvm heap >> snapshot. >> According to the jam heap analysis, possible memory leak was Flink >> list >> state descriptor. But we are not sure that is the cause of our >> memory >> problem. How can we solve the problem? >> >> We have two types of Flink job. One has no state full operator >> contains only maps and filters and the other has time window with >> count trigger. > * We've analysed the jvm heaps again in different conditions. First > we analysed the snapshot when no flink jobs running on cluster. (image > 1) > * Then, we analysed the jvm heap snapshot when the flink job that has > no state full operator is running. And according to the results, leak > suspect was NetworkBufferPool (image 2) > * Last analys, there were both two types of jobs running and leak > suspect was again NetworkBufferPool. (image 3) > In our system jobs are regularly cancelled and resubmitted so we > noticed that when job is submitted some amount of memory allocated and > after cancelation this allocated memory never freed. So over time > memory usage is always increasing and exceeded the limits. > >>> > > > > Links: > ------ > [1] https://issues.apache.org/jira/browse/FLINK-7845 There are two types of jobs. In first, we use Kafka source and Kafka sink, there isn't any window operator. In second job, we use Kafka source, filesystem sink and elastic search sink and window operator for buffering. |
|
|
Hi, This is the test flink job we created to trigger this leak https://gist.github.com/javieredo/c6052404dbe6cc602e99f4669a09f7d6 And this is the python script we are using to execute the job thousands of times to get the OOM problem https://gist.github.com/javieredo/4825324d5d5f504e27ca6c004396a107 The cluster we used for this has this configuration:
We have tried several things, increasing the heap, reducing the heap, more memory fraction, changes this value in the taskmanager.sh "TM_MAX_OFFHEAP_SIZE="2G"; and nothing seems to work. Thanks for your help. On 8 November 2017 at 13:26, ÇETİNKAYA EBRU ÇETİNKAYA EBRU <[hidden email]> wrote:
|
|
|
Hi,
Thanks for sharing this job. Do I need to feed some data to the Kafka to reproduce this issue with your script? Does this OOM issue also happen when you are not using the Kafka source/sink? Piotrek
|
|
|
Hi, You don't need data. With data it will die faster. I tested as well with a small data set, using the fromElements source, but it will take some time to die. It's better with some data. On 8 November 2017 at 14:54, Piotr Nowojski <[hidden email]> wrote:
|
|
|
Thanks for quick answer. So it will also fail after some time with `fromElements` source instead of Kafka, right? Did you try it also without a Kafka producer? Piotrek
|
|
|
Yes, I tested with just printing the stream. But it could take a lot of time to fail.
On Wednesday, 8 November 2017, Piotr Nowojski <[hidden email]> wrote: > Thanks for quick answer. > So it will also fail after some time with `fromElements` source instead of Kafka, right? > Did you try it also without a Kafka producer? > Piotrek > > On 8 Nov 2017, at 14:57, Javier Lopez <[hidden email]> wrote: > Hi, > You don't need data. With data it will die faster. I tested as well with a small data set, using the fromElements source, but it will take some time to die. It's better with some data. > On 8 November 2017 at 14:54, Piotr Nowojski <[hidden email]> wrote: >> >> Hi, >> Thanks for sharing this job. >> Do I need to feed some data to the Kafka to reproduce this issue with your script? >> Does this OOM issue also happen when you are not using the Kafka source/sink? >> Piotrek >> >> On 8 Nov 2017, at 14:08, Javier Lopez <[hidden email]> wrote: >> Hi, >> This is the test flink job we created to trigger this leak https://gist.github.com/javieredo/c6052404dbe6cc602e99f4669a09f7d6 >> And this is the python script we are using to execute the job thousands of times to get the OOM problem https://gist.github.com/javieredo/4825324d5d5f504e27ca6c004396a107 >> The cluster we used for this has this configuration: >> >> Instance type: t2.large >> Number of workers: 2 >> HeapMemory: 5500 >> Number of task slots per node: 4 >> TaskMangMemFraction: 0.5 >> NumberOfNetworkBuffers: 2000 >> >> We have tried several things, increasing the heap, reducing the heap, more memory fraction, changes this value in the taskmanager.sh "TM_MAX_OFFHEAP_SIZE="2G"; and nothing seems to work. >> Thanks for your help. >> On 8 November 2017 at 13:26, ÇETİNKAYA EBRU ÇETİNKAYA EBRU <[hidden email]> wrote: >>> >>> On 2017-11-08 15:20, Piotr Nowojski wrote: >>>> >>>> Hi Ebru and Javier, >>>> >>>> Yes, if you could share this example job it would be helpful. >>>> >>>> Ebru: could you explain in a little more details how does your Job(s) >>>> look like? Could you post some code? If you are just using maps and >>>> filters there shouldn’t be any network transfers involved, aside >>>> from Source and Sink functions. >>>> >>>> Piotrek >>>> >>>>> On 8 Nov 2017, at 12:54, ebru <[hidden email]> wrote: >>>>> >>>>> Hi Javier, >>>>> >>>>> It would be helpful if you share your test job with us. >>>>> Which configurations did you try? >>>>> >>>>> -Ebru >>>>> >>>>> On 8 Nov 2017, at 14:43, Javier Lopez <[hidden email]> >>>>> wrote: >>>>> >>>>> Hi, >>>>> >>>>> We have been facing a similar problem. We have tried some different >>>>> configurations, as proposed in other email thread by Flavio and >>>>> Kien, but it didn't work. We have a workaround similar to the one >>>>> that Flavio has, we restart the taskmanagers once they reach a >>>>> memory threshold. We created a small test to remove all of our >>>>> dependencies and leave only flink native libraries. This test reads >>>>> data from a Kafka topic and writes it back to another topic in >>>>> Kafka. We cancel the job and start another every 5 seconds. After >>>>> ~30 minutes of doing this process, the cluster reaches the OS memory >>>>> limit and dies. >>>>> >>>>> Currently, we have a test cluster with 8 workers and 8 task slots >>>>> per node. We have one job that uses 56 slots, and we cannot execute >>>>> that job 5 times in a row because the whole cluster dies. If you >>>>> want, we can publish our test job. >>>>> >>>>> Regards, >>>>> >>>>> On 8 November 2017 at 11:20, Aljoscha Krettek <[hidden email]> >>>>> wrote: >>>>> >>>>> @Nico & @Piotr Could you please have a look at this? You both >>>>> recently worked on the network stack and might be most familiar with >>>>> this. >>>>> >>>>> On 8. Nov 2017, at 10:25, Flavio Pompermaier <[hidden email]> >>>>> wrote: >>>>> >>>>> We also have the same problem in production. At the moment the >>>>> solution is to restart the entire Flink cluster after every job.. >>>>> We've tried to reproduce this problem with a test (see >>>>> https://issues.apache.org/jira/browse/FLINK-7845 [1]) but we don't >>>>> know whether the error produced by the test and the leak are >>>>> correlated.. >>>>> >>>>> Best, >>>>> Flavio >>>>> >>>>> On Wed, Nov 8, 2017 at 9:51 AM, ÇETİNKAYA EBRU ÇETİNKAYA EBRU >>>>> <[hidden email]> wrote: >>>>> On 2017-11-07 16:53, Ufuk Celebi wrote: >>>>> Do you use any windowing? If yes, could you please share that code? >>>>> If >>>>> there is no stateful operation at all, it's strange where the list >>>>> state instances are coming from. >>>>> >>>>> On Tue, Nov 7, 2017 at 2:35 PM, ebru <[hidden email]> >>>>> wrote: >>>>> Hi Ufuk, >>>>> >>>>> We don’t explicitly define any state descriptor. We only use map >>>>> and filters >>>>> operator. We thought that gc handle clearing the flink’s internal >>>>> states. >>>>> So how can we manage the memory if it is always increasing? >>>>> >>>>> - Ebru >>>>> >>>>> On 7 Nov 2017, at 16:23, Ufuk Celebi <[hidden email]> wrote: >>>>> >>>>> Hey Ebru, the memory usage might be increasing as long as a job is >>>>> running. >>>>> This is expected (also in the case of multiple running jobs). The >>>>> screenshots are not helpful in that regard. :-( >>>>> >>>>> What kind of stateful operations are you using? Depending on your >>>>> use case, >>>>> you have to manually call `clear()` on the state instance in order >>>>> to >>>>> release the managed state. >>>>> >>>>> Best, >>>>> >>>>> Ufuk >>>>> >>>>> On Tue, Nov 7, 2017 at 12:43 PM, ebru >>>>> <[hidden email]> wrote: >>>>> >>>>> Begin forwarded message: >>>>> >>>>> From: ebru <[hidden email]> >>>>> Subject: Re: Flink memory leak >>>>> Date: 7 November 2017 at 14:09:17 GMT+3 >>>>> To: Ufuk Celebi <[hidden email]> >>>>> >>>>> Hi Ufuk, >>>>> >>>>> There are there snapshots of htop output. >>>>> 1. snapshot is initial state. >>>>> 2. snapshot is after submitted one job. >>>>> 3. Snapshot is the output of the one job with 15000 EPS. And the >>>>> memory >>>>> usage is always increasing over time. >>>>> >>>>> <1.png><2.png><3.png> >>>>> >>>>> On 7 Nov 2017, at 13:34, Ufuk Celebi <[hidden email]> wrote: >>>>> >>>>> Hey Ebru, >>>>> >>>>> let me pull in Aljoscha (CC'd) who might have an idea what's causing >>>>> this. >>>>> >>>>> Since multiple jobs are running, it will be hard to understand to >>>>> which job the state descriptors from the heap snapshot belong to. >>>>> - Is it possible to isolate the problem and reproduce the behaviour >>>>> with only a single job? >>>>> >>>>> – Ufuk >>>>> >>>>> On Tue, Nov 7, 2017 at 10:27 AM, ÇETİNKAYA EBRU ÇETİNKAYA EBRU >>>>> <[hidden email]> wrote: >>>>> >>>>> Hi, >>>>> >>>>> We are using Flink 1.3.1 in production, we have one job manager and >>>>> 3 task >>>>> managers in standalone mode. Recently, we've noticed that we have >>>>> memory >>>>> related problems. We use docker container to serve Flink cluster. We >>>>> have >>>>> 300 slots and 20 jobs are running with parallelism of 10. Also the >>>>> job >>>>> count >>>>> may be change over time. Taskmanager memory usage always increases. >>>>> After >>>>> job cancelation this memory usage doesn't decrease. We've tried to >>>>> investigate the problem and we've got the task manager jvm heap >>>>> snapshot. >>>>> According to the jam heap analysis, possible memory leak was Flink >>>>> list >>>>> state descriptor. But we are not sure that is the cause of our >>>>> memory >>>>> problem. How can we solve the problem? >>>>> >>>>> We have two types of Flink job. One has no state full operator >>>>> contains only maps and filters and the other has time window with >>>>> count trigger. >>>> >>>> * We've analysed the jvm heaps again in different conditions. First >>>> we analysed the snapshot when no flink jobs running on cluster. (image >>>> 1) >>>> * Then, we analysed the jvm heap snapshot when the flink job that has >>>> no state full operator is running. And according to the results, leak >>>> suspect was NetworkBufferPool (image 2) >>>> * Last analys, there were both two types of jobs running and leak >>>> suspect was again NetworkBufferPool. (image 3) >>>> In our system jobs are regularly cancelled and resubmitted so we >>>> noticed that when job is submitted some amount of memory allocated and >>>> after cancelation this allocated memory never freed. So over time >>>> memory usage is always increasing and exceeded the limits. >>>> >>>>>> >>>> >>>> >>>> >>>> Links: >>>> ------ >>>> [1] https://issues.apache.org/jira/browse/FLINK-7845 >>> >>> Hi Piotr, >>> >>> There are two types of jobs. >>> In first, we use Kafka source and Kafka sink, there isn't any window operator. >>> In second job, we use Kafka source, filesystem sink and elastic search sink and window operator for buffering. >> >> > > > |
|
|
I don’t know if this is relevant to this issue, but I was constantly getting failures trying to reproduce this leak using your Job, because you were using non deterministic getKey function: @Override And quoting Java doc of KeySelector: "If invoked multiple times on the same object, the returned key must be the same.” I’m trying to reproduce this issue with following job: Where IntegerSource is just an infinite source, DisardingSink is well just discarding incoming data. I’m cancelling the job every 5 seconds and so far (after ~15 minutes) my memory consumption is stable, well below maximum java heap size. Piotrek
|
|
|
Btw, Ebru:
I don’t agree that the main suspect is NetworkBufferPool. On your screenshots it’s memory consumption was reasonable and stable: 596MB -> 602MB -> 597MB. PoolThreadCache memory usage ~120MB is also reasonable. Do you experience any problems, like Out Of Memory errors/crashes/long GC pauses? Or just JVM process is using more memory over time? You are aware that JVM doesn’t like to release memory back to OS once it was used? So increasing memory usage until hitting some limit (for example JVM max heap size) is expected behaviour. Piotrek
|
|
|
On 2017-11-08 18:30, Piotr Nowojski wrote:
> Btw, Ebru: > > I don’t agree that the main suspect is NetworkBufferPool. On your > screenshots it’s memory consumption was reasonable and stable: 596MB > -> 602MB -> 597MB. > > PoolThreadCache memory usage ~120MB is also reasonable. > > Do you experience any problems, like Out Of Memory errors/crashes/long > GC pauses? Or just JVM process is using more memory over time? You are > aware that JVM doesn’t like to release memory back to OS once it was > used? So increasing memory usage until hitting some limit (for example > JVM max heap size) is expected behaviour. > > Piotrek > >> On 8 Nov 2017, at 15:48, Piotr Nowojski <[hidden email]> >> wrote: >> >> I don’t know if this is relevant to this issue, but I was >> constantly getting failures trying to reproduce this leak using your >> Job, because you were using non deterministic getKey function: >> >> @Override >> public Integer getKey(Integer event) { >> Random randomGen = new Random((new Date()).getTime()); >> return randomGen.nextInt() % 8; >> } >> >> And quoting Java doc of KeySelector: >> >> "If invoked multiple times on the same object, the returned key must >> be the same.” >> >> I’m trying to reproduce this issue with following job: >> >> https://gist.github.com/pnowojski/b80f725c1af7668051c773438637e0d3 >> >> Where IntegerSource is just an infinite source, DisardingSink is >> well just discarding incoming data. I’m cancelling the job every 5 >> seconds and so far (after ~15 minutes) my memory consumption is >> stable, well below maximum java heap size. >> >> Piotrek >> >>> On 8 Nov 2017, at 15:28, Javier Lopez <[hidden email]> >>> wrote: >>> Yes, I tested with just printing the stream. But it could take a >>> lot of time to fail. >>> >>> On Wednesday, 8 November 2017, Piotr Nowojski >>> <[hidden email]> wrote: >>>> Thanks for quick answer. >>>> So it will also fail after some time with `fromElements` source >>> instead of Kafka, right? >>>> Did you try it also without a Kafka producer? >>>> Piotrek >>>> >>>> On 8 Nov 2017, at 14:57, Javier Lopez <[hidden email]> >>> wrote: >>>> Hi, >>>> You don't need data. With data it will die faster. I tested as >>> well with a small data set, using the fromElements source, but it >>> will take some time to die. It's better with some data. >>>> On 8 November 2017 at 14:54, Piotr Nowojski >>> <[hidden email]> wrote: >>>>> >>>>> Hi, >>>>> Thanks for sharing this job. >>>>> Do I need to feed some data to the Kafka to reproduce this >>> issue with your script? >>>>> Does this OOM issue also happen when you are not using the >>> Kafka source/sink? >>>>> Piotrek >>>>> >>>>> On 8 Nov 2017, at 14:08, Javier Lopez <[hidden email]> >>> wrote: >>>>> Hi, >>>>> This is the test flink job we created to trigger this leak >>> https://gist.github.com/javieredo/c6052404dbe6cc602e99f4669a09f7d6 >>>>> And this is the python script we are using to execute the job >>> thousands of times to get the OOM problem >>> https://gist.github.com/javieredo/4825324d5d5f504e27ca6c004396a107 >>>>> The cluster we used for this has this configuration: >>>>> >>>>> Instance type: t2.large >>>>> Number of workers: 2 >>>>> HeapMemory: 5500 >>>>> Number of task slots per node: 4 >>>>> TaskMangMemFraction: 0.5 >>>>> NumberOfNetworkBuffers: 2000 >>>>> >>>>> We have tried several things, increasing the heap, reducing the >>> heap, more memory fraction, changes this value in the >>> taskmanager.sh "TM_MAX_OFFHEAP_SIZE="2G"; and nothing seems to >>> work. >>>>> Thanks for your help. >>>>> On 8 November 2017 at 13:26, ÇETİNKAYA EBRU ÇETİNKAYA EBRU >>> <[hidden email]> wrote: >>>>>> >>>>>> On 2017-11-08 15:20, Piotr Nowojski wrote: >>>>>>> >>>>>>> Hi Ebru and Javier, >>>>>>> >>>>>>> Yes, if you could share this example job it would be helpful. >>>>>>> >>>>>>> Ebru: could you explain in a little more details how does >>> your Job(s) >>>>>>> look like? Could you post some code? If you are just using >>> maps and >>>>>>> filters there shouldn’t be any network transfers involved, >>> aside >>>>>>> from Source and Sink functions. >>>>>>> >>>>>>> Piotrek >>>>>>> >>>>>>>> On 8 Nov 2017, at 12:54, ebru >>> <[hidden email]> wrote: >>>>>>>> >>>>>>>> Hi Javier, >>>>>>>> >>>>>>>> It would be helpful if you share your test job with us. >>>>>>>> Which configurations did you try? >>>>>>>> >>>>>>>> -Ebru >>>>>>>> >>>>>>>> On 8 Nov 2017, at 14:43, Javier Lopez >>> <[hidden email]> >>>>>>>> wrote: >>>>>>>> >>>>>>>> Hi, >>>>>>>> >>>>>>>> We have been facing a similar problem. We have tried some >>> different >>>>>>>> configurations, as proposed in other email thread by Flavio >>> and >>>>>>>> Kien, but it didn't work. We have a workaround similar to >>> the one >>>>>>>> that Flavio has, we restart the taskmanagers once they reach >>> a >>>>>>>> memory threshold. We created a small test to remove all of >>> our >>>>>>>> dependencies and leave only flink native libraries. This >>> test reads >>>>>>>> data from a Kafka topic and writes it back to another topic >>> in >>>>>>>> Kafka. We cancel the job and start another every 5 seconds. >>> After >>>>>>>> ~30 minutes of doing this process, the cluster reaches the >>> OS memory >>>>>>>> limit and dies. >>>>>>>> >>>>>>>> Currently, we have a test cluster with 8 workers and 8 task >>> slots >>>>>>>> per node. We have one job that uses 56 slots, and we cannot >>> execute >>>>>>>> that job 5 times in a row because the whole cluster dies. If >>> you >>>>>>>> want, we can publish our test job. >>>>>>>> >>>>>>>> Regards, >>>>>>>> >>>>>>>> On 8 November 2017 at 11:20, Aljoscha Krettek >>> <[hidden email]> >>>>>>>> wrote: >>>>>>>> >>>>>>>> @Nico & @Piotr Could you please have a look at this? You >>> both >>>>>>>> recently worked on the network stack and might be most >>> familiar with >>>>>>>> this. >>>>>>>> >>>>>>>> On 8. Nov 2017, at 10:25, Flavio Pompermaier >>> <[hidden email]> >>>>>>>> wrote: >>>>>>>> >>>>>>>> We also have the same problem in production. At the moment >>> the >>>>>>>> solution is to restart the entire Flink cluster after every >>> job.. >>>>>>>> We've tried to reproduce this problem with a test (see >>>>>>>> https://issues.apache.org/jira/browse/FLINK-7845 [1]) but we >>> don't >>>>>>>> know whether the error produced by the test and the leak are >>>>>>>> correlated.. >>>>>>>> >>>>>>>> Best, >>>>>>>> Flavio >>>>>>>> >>>>>>>> On Wed, Nov 8, 2017 at 9:51 AM, ÇETİNKAYA EBRU ÇETİNKAYA >>> EBRU >>>>>>>> <[hidden email]> wrote: >>>>>>>> On 2017-11-07 16:53, Ufuk Celebi wrote: >>>>>>>> Do you use any windowing? If yes, could you please share >>> that code? >>>>>>>> If >>>>>>>> there is no stateful operation at all, it's strange where >>> the list >>>>>>>> state instances are coming from. >>>>>>>> >>>>>>>> On Tue, Nov 7, 2017 at 2:35 PM, ebru >>> <[hidden email]> >>>>>>>> wrote: >>>>>>>> Hi Ufuk, >>>>>>>> >>>>>>>> We don’t explicitly define any state descriptor. We only >>> use map >>>>>>>> and filters >>>>>>>> operator. We thought that gc handle clearing the flink’s >>> internal >>>>>>>> states. >>>>>>>> So how can we manage the memory if it is always increasing? >>>>>>>> >>>>>>>> - Ebru >>>>>>>> >>>>>>>> On 7 Nov 2017, at 16:23, Ufuk Celebi <[hidden email]> wrote: >>>>>>>> >>>>>>>> Hey Ebru, the memory usage might be increasing as long as a >>> job is >>>>>>>> running. >>>>>>>> This is expected (also in the case of multiple running >>> jobs). The >>>>>>>> screenshots are not helpful in that regard. :-( >>>>>>>> >>>>>>>> What kind of stateful operations are you using? Depending on >>> your >>>>>>>> use case, >>>>>>>> you have to manually call `clear()` on the state instance in >>> order >>>>>>>> to >>>>>>>> release the managed state. >>>>>>>> >>>>>>>> Best, >>>>>>>> >>>>>>>> Ufuk >>>>>>>> >>>>>>>> On Tue, Nov 7, 2017 at 12:43 PM, ebru >>>>>>>> <[hidden email]> wrote: >>>>>>>> >>>>>>>> Begin forwarded message: >>>>>>>> >>>>>>>> From: ebru <[hidden email]> >>>>>>>> Subject: Re: Flink memory leak >>>>>>>> Date: 7 November 2017 at 14:09:17 GMT+3 >>>>>>>> To: Ufuk Celebi <[hidden email]> >>>>>>>> >>>>>>>> Hi Ufuk, >>>>>>>> >>>>>>>> There are there snapshots of htop output. >>>>>>>> 1. snapshot is initial state. >>>>>>>> 2. snapshot is after submitted one job. >>>>>>>> 3. Snapshot is the output of the one job with 15000 EPS. And >>> the >>>>>>>> memory >>>>>>>> usage is always increasing over time. >>>>>>>> >>>>>>>> <1.png><2.png><3.png> >>>>>>>> >>>>>>>> On 7 Nov 2017, at 13:34, Ufuk Celebi <[hidden email]> wrote: >>>>>>>> >>>>>>>> Hey Ebru, >>>>>>>> >>>>>>>> let me pull in Aljoscha (CC'd) who might have an idea what's >>> causing >>>>>>>> this. >>>>>>>> >>>>>>>> Since multiple jobs are running, it will be hard to >>> understand to >>>>>>>> which job the state descriptors from the heap snapshot >>> belong to. >>>>>>>> - Is it possible to isolate the problem and reproduce the >>> behaviour >>>>>>>> with only a single job? >>>>>>>> >>>>>>>> – Ufuk >>>>>>>> >>>>>>>> On Tue, Nov 7, 2017 at 10:27 AM, ÇETİNKAYA EBRU >>> ÇETİNKAYA EBRU >>>>>>>> <[hidden email]> wrote: >>>>>>>> >>>>>>>> Hi, >>>>>>>> >>>>>>>> We are using Flink 1.3.1 in production, we have one job >>> manager and >>>>>>>> 3 task >>>>>>>> managers in standalone mode. Recently, we've noticed that we >>> have >>>>>>>> memory >>>>>>>> related problems. We use docker container to serve Flink >>> cluster. We >>>>>>>> have >>>>>>>> 300 slots and 20 jobs are running with parallelism of 10. >>> Also the >>>>>>>> job >>>>>>>> count >>>>>>>> may be change over time. Taskmanager memory usage always >>> increases. >>>>>>>> After >>>>>>>> job cancelation this memory usage doesn't decrease. We've >>> tried to >>>>>>>> investigate the problem and we've got the task manager jvm >>> heap >>>>>>>> snapshot. >>>>>>>> According to the jam heap analysis, possible memory leak was >>> Flink >>>>>>>> list >>>>>>>> state descriptor. But we are not sure that is the cause of >>> our >>>>>>>> memory >>>>>>>> problem. How can we solve the problem? >>>>>>>> >>>>>>>> We have two types of Flink job. One has no state full >>> operator >>>>>>>> contains only maps and filters and the other has time window >>> with >>>>>>>> count trigger. >>>>>>> >>>>>>> * We've analysed the jvm heaps again in different >>> conditions. First >>>>>>> we analysed the snapshot when no flink jobs running on >>> cluster. (image >>>>>>> 1) >>>>>>> * Then, we analysed the jvm heap snapshot when the flink job >>> that has >>>>>>> no state full operator is running. And according to the >>> results, leak >>>>>>> suspect was NetworkBufferPool (image 2) >>>>>>> * Last analys, there were both two types of jobs running >>> and leak >>>>>>> suspect was again NetworkBufferPool. (image 3) >>>>>>> In our system jobs are regularly cancelled and resubmitted so >>> we >>>>>>> noticed that when job is submitted some amount of memory >>> allocated and >>>>>>> after cancelation this allocated memory never freed. So over >>> time >>>>>>> memory usage is always increasing and exceeded the limits. >>>>>>> >>>>>>>>> >>>>>>> >>>>>>> >>>>>>> >>>>>>> Links: >>>>>>> ------ >>>>>>> [1] https://issues.apache.org/jira/browse/FLINK-7845 >>>>>> >>>>>> Hi Piotr, >>>>>> >>>>>> There are two types of jobs. >>>>>> In first, we use Kafka source and Kafka sink, there isn't any >>> window operator. >>>>>> In second job, we use Kafka source, filesystem sink and >>> elastic search sink and window operator for buffering. >>>>> >>>>> >>>> >>>> >>>> Thanks for your reply. We've tested our link cluster again. We have 360 slots, and our cluster configuration is like this; jobmanager.rpc.address: %JOBMANAGER% jobmanager.rpc.port: 6123 jobmanager.heap.mb: 1536 taskmanager.heap.mb: 1536 taskmanager.numberOfTaskSlots: 120 taskmanager.memory.preallocate: false parallelism.default: 1 jobmanager.web.port: 8081 state.backend: filesystem state.backend.fs.checkpointdir: file:///storage/%CHECKPOINTDIR% state.checkpoints.dir: file:///storage/%CHECKPOINTDIR% taskmanager.network.numberOfBuffers: 5000 We are using docker based Flink cluster. WE submitted 36 jobs with the parallelism of 10. After all slots became full. Memory usage were increasing by the time and one by one task managers start to die. And the exception was like this; Taskmanager1 log: Uncaught error from thread [flink-akka.actor.default-dispatcher-17] shutting down JVM since 'akka.jvm-exit-on-fatal-error' is enabled for ActorSystem[flink] java.lang.NoClassDefFoundError: org/apache/kafka/common/metrics/stats/Rate$1 at org.apache.kafka.common.metrics.stats.Rate.convert(Rate.java:93) at org.apache.kafka.common.metrics.stats.Rate.measure(Rate.java:62) at org.apache.kafka.common.metrics.KafkaMetric.value(KafkaMetric.java:61) at org.apache.kafka.common.metrics.KafkaMetric.value(KafkaMetric.java:52) at org.apache.flink.streaming.connectors.kafka.internals.metrics.KafkaMetricWrapper.getValue(KafkaMetricWrapper.java:35) at org.apache.flink.streaming.connectors.kafka.internals.metrics.KafkaMetricWrapper.getValue(KafkaMetricWrapper.java:26) at org.apache.flink.runtime.metrics.dump.MetricDumpSerialization.serializeGauge(MetricDumpSerialization.java:213) at org.apache.flink.runtime.metrics.dump.MetricDumpSerialization.access$200(MetricDumpSerialization.java:50) at org.apache.flink.runtime.metrics.dump.MetricDumpSerialization$MetricDumpSerializer.serialize(MetricDumpSerialization.java:138) at org.apache.flink.runtime.metrics.dump.MetricQueryService.onReceive(MetricQueryService.java:109) at akka.actor.UntypedActor$$anonfun$receive$1.applyOrElse(UntypedActor.scala:167) at akka.actor.Actor$class.aroundReceive(Actor.scala:467) at akka.actor.UntypedActor.aroundReceive(UntypedActor.scala:97) at akka.actor.ActorCell.receiveMessage(ActorCell.scala:516) at akka.actor.ActorCell.invoke(ActorCell.scala:487) at akka.dispatch.Mailbox.processMailbox(Mailbox.scala:238) at akka.dispatch.Mailbox.run(Mailbox.scala:220) at akka.dispatch.ForkJoinExecutorConfigurator$AkkaForkJoinTask.exec(AbstractDispatcher.scala:397) at scala.concurrent.forkjoin.ForkJoinTask.doExec(ForkJoinTask.java:260) at scala.concurrent.forkjoin.ForkJoinPool$WorkQueue.runTask(ForkJoinPool.java:1339) at scala.concurrent.forkjoin.ForkJoinPool.runWorker(ForkJoinPool.java:1979) at scala.concurrent.forkjoin.ForkJoinWorkerThread.run(ForkJoinWorkerThread.java:107) Caused by: java.lang.ClassNotFoundException: org.apache.kafka.common.metrics.stats.Rate$1 at java.net.URLClassLoader.findClass(URLClassLoader.java:381) at java.lang.ClassLoader.loadClass(ClassLoader.java:424) at java.lang.ClassLoader.loadClass(ClassLoader.java:357) ... 22 more Taskmanager2 log: Uncaught error from thread [flink-akka.actor.default-dispatcher-17] shutting down JVM since 'akka.jvm-exit-on-fatal-error' is enabled for ActorSystem[flink] Java.lang.NoClassDefFoundError: org/apache/flink/streaming/connectors/kafka/internals/AbstractFetcher$1 at org.apache.flink.streaming.connectors.kafka.internals.AbstractFetcher$OffsetGauge.getValue(AbstractFetcher.java:492) at org.apache.flink.streaming.connectors.kafka.internals.AbstractFetcher$OffsetGauge.getValue(AbstractFetcher.java:480) at org.apache.flink.runtime.metrics.dump.MetricDumpSerialization.serializeGauge(MetricDumpSerialization.java:213) at org.apache.flink.runtime.metrics.dump.MetricDumpSerialization.access$200(MetricDumpSerialization.java:50) at org.apache.flink.runtime.metrics.dump.MetricDumpSerialization$MetricDumpSerializer.serialize(MetricDumpSerialization.java:138) at org.apache.flink.runtime.metrics.dump.MetricQueryService.onReceive(MetricQueryService.java:109) at akka.actor.UntypedActor$$anonfun$receive$1.applyOrElse(UntypedActor.scala:167) at akka.actor.Actor$class.aroundReceive(Actor.scala:467) at akka.actor.UntypedActor.aroundReceive(UntypedActor.scala:97) at akka.actor.ActorCell.receiveMessage(ActorCell.scala:516) at akka.actor.ActorCell.invoke(ActorCell.scala:487) at akka.dispatch.Mailbox.processMailbox(Mailbox.scala:238) at akka.dispatch.Mailbox.run(Mailbox.scala:220) at akka.dispatch.ForkJoinExecutorConfigurator$AkkaForkJoinTask.exec(AbstractDispatcher.scala:397) at scala.concurrent.forkjoin.ForkJoinTask.doExec(ForkJoinTask.java:260) at scala.concurrent.forkjoin.ForkJoinPool$WorkQueue.runTask(ForkJoinPool.java:1339) at scala.concurrent.forkjoin.ForkJoinPool.runWorker(ForkJoinPool.java:1979) at scala.concurrent.forkjoin.ForkJoinWorkerThread.run(ForkJoinWorkerThread.java:107) Caused by: java.lang.ClassNotFoundException: org.apache.flink.streaming.connectors.kafka.internals.AbstractFetcher$1 at java.net.URLClassLoader.findClass(URLClassLoader.java:381) at java.lang.ClassLoader.loadClass(ClassLoader.java:424) at java.lang.ClassLoader.loadClass(ClassLoader.java:357) ... 18 more -Ebru |
«
Return to (DEPRECATED) Apache Flink User Mailing List archive.
|
1 view|%1 views
| Free forum by Nabble | Edit this page |