Fwd: Duplicate tasks for the same query


|
Hi Team,
I'm doing a POC with flink to understand if it's a good fit for my use case. As part of the process, I need to filter duplicate items and created below query to get only the latest records based on timestamp. For instance, I have "Users" table which may contain multiple messages for the same "userId". So I wrote below query to get only the latest message for a given "userId" Table uniqueUsers = tEnv.sqlQuery("SELECT * FROM Users WHERE (userId, userTimestamp) IN (SELECT userId, MAX(userTimestamp) FROM Users GROUP BY userId)"); The above query works as expected and contains only the latest users based on timestamp. The issue is when I use "uniqueUsers" table multiple times in a JOIN operation, I see multiple tasks in the flink dashboard for the same query that is creating "uniqueUsers" table. It is simply creating as many tasks as many times I'm using the table. Below is the JOIN query. tEnv.registerTable("uniqueUsersTbl", uniqueUsers); Table joinOut = tEnv.sqlQuery("SELECT * FROM Car c LEFT JOIN uniqueUsersTbl aa ON c.userId = aa.userId LEFT JOIN uniqueUsersTbl ab ON c.ownerId = ab.userId LEFT JOIN uniqueUsersTbl ac ON c.sellerId = ac.userId LEFT JOIN uniqueUsersTbl ad ON c.buyerId = ad.userId"); Could someone please help me understand how I can avoid these duplicate tasks? Thanks, R Kandoji |
Re: Duplicate tasks for the same query
|
|
Hi RKandoji~
Could you provide more info about your poc environment? Stream or batch? Flink planner or blink planner? AFAIK, blink planner has done some optimization to deal such duplicate task for one same query. You can have a try with blink planner : https://ci.apache.org/projects/flink/flink-docs-master/dev/table/common.html#create-a-tableenvironment Best, Terry Wang
|
Re: Duplicate tasks for the same query
|
|
Hi RKandoji, FYI: Blink-planner subplan reusing: [1] 1.9 available. Join Join Best, Jingsong Lee On Mon, Dec 30, 2019 at 12:28 PM Terry Wang <[hidden email]> wrote:
Best, Jingsong Lee |
|
|
Thanks Terry and Jingsong, Currently I'm on 1.8 version using Flink planner for stream proessing, I'll switch to 1.9 version to try out blink planner. Could you please point me to any examples (Java preferred) using SubplanReuser? Thanks, RK On Sun, Dec 29, 2019 at 11:32 PM Jingsong Li <[hidden email]> wrote:
|
Re: Duplicate tasks for the same query
|
|
Hi RKandoji, In theory, you don't need to do something. First, the optimizer will optimize by doing duplicate nodes. Second, after SQL optimization, if the optimized plan still has duplicate nodes, the planner will automatically reuse them. There are config options to control whether we should reuse plan, their default value is true. So you don't need modify them. - table.optimizer.reuse-sub-plan-enabled - table.optimizer.reuse-source-enabled Best, Jingsong Lee On Tue, Dec 31, 2019 at 6:29 AM RKandoji <[hidden email]> wrote:
Best, Jingsong Lee |
Re: Duplicate tasks for the same query
|
|
BTW, you could also have a more efficient version of deduplicating user table by using the topn feature [1]. Best, Kurt On Tue, Dec 31, 2019 at 9:24 AM Jingsong Li <[hidden email]> wrote:
|
|
|
Thanks Jingsong and Kurt for more details. Yes, I'm planning to try out DeDuplication when I'm done upgrading to version 1.9. Hopefully deduplication is done by only one task and reused everywhere else. One more follow-up question, I see "For production use cases, we recommend the old planner that was present before Flink 1.9 for now." warning here https://ci.apache.org/projects/flink/flink-docs-stable/dev/table/ This is actually the reason why started with version 1.8, could you please let me know your opinion about this? and do you think there is any production code running on version 1.9 Thanks, Reva On Mon, Dec 30, 2019 at 9:02 PM Kurt Young <[hidden email]> wrote:
|
Re: Duplicate tasks for the same query
|
|
Blink planner was introduced in 1.9. We recommend use blink planner after 1.9. After some bug fix, I think the latest version of 1.9 is OK. The production environment has also been set up in some places. Best, Jingsong Lee On Wed, Jan 1, 2020 at 3:24 AM RKandoji <[hidden email]> wrote:
Best, Jingsong Lee |
|
|
Ok thanks, does it mean version 1.9.2 is what I need to use? On Wed, Jan 1, 2020 at 10:25 PM Jingsong Li <[hidden email]> wrote:
|
Re: Duplicate tasks for the same query
|
|
Yes, 1.9.2 or Coming soon 1.10 Best, Jingsong Lee On Fri, Jan 3, 2020 at 12:43 AM RKandoji <[hidden email]> wrote:
Best, Jingsong Lee |
|
|
Thanks! On Thu, Jan 2, 2020 at 9:45 PM Jingsong Li <[hidden email]> wrote:
|
|
|
Hi, Thanks a ton for the help with earlier questions, I updated code to version 1.9 and started using Blink Planner (DeDuplication). This is working as expected! I have a new question, but thought of asking in the same email chain as this has more context about my use case etc. Workflow: Currently I'm reading from a couple of Kafka topics, DeDuplicating the input data, performing JOINs and writing the joined data to another Kafka topic. Issue: I set Parallelism to 8 and on analyzing the subtasks found that the data is not distributed well among 8 parallel tasks for the last Join query. One of a subtask is taking huge load, whereas others taking pretty low load. Tried a couple of things below, but no use. Not sure if they are actually related to the problem as I couldn't yet understand what's the issue here. 1. increasing the number of partitions of output Kafka topic. 2. tried adding keys to output so key partitioning happens at Kafka end. Below is a snapshot for reference: 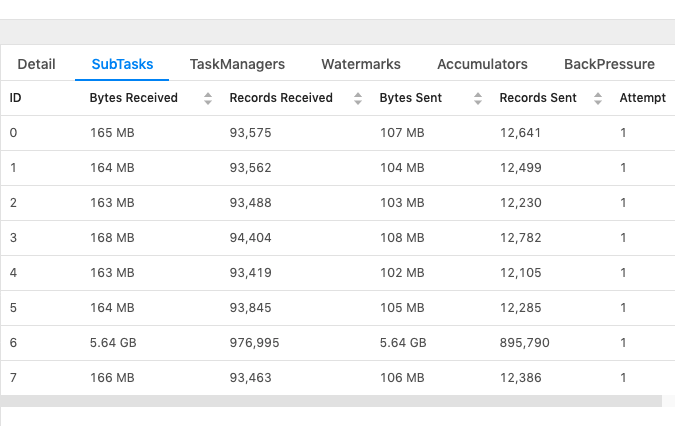 Below are the config changes I made: taskmanager.numberOfTaskSlots: 8 parallelism.default: 8 jobmanager.heap.size: 5000m taskmanager.heap.size: 5000m state.backend: rocksdb state.checkpoints.dir: file:///Users/username/flink-1.9.1/checkpoints state.backend.incremental: true I don't see any errors and job seems to be running smoothly (and slowly). I need to make it distribute the load well for faster processing, any pointers on what could be wrong and how to fix it would be very helpful. Thanks, RKandoji On Fri, Jan 3, 2020 at 1:06 PM RKandoji <[hidden email]> wrote:
|
Re: Duplicate tasks for the same query
|
|
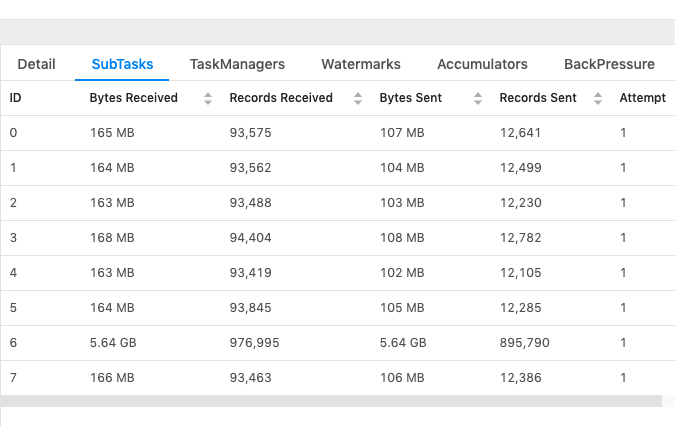
Hi RKandoji, It looks like you have a data skew issue with your input data. Some or maybe only one "userId" appears more frequent than others. For join operator to work correctly, Flink will apply "shuffle by join key" before the operator, so same "userId" will go to the same sub-task to perform join operation. In this case, I'm afraid there is nothing much you can do for now. BTW, for the DeDuplicate, do you keep the latest record or the earliest? If you keep the latest version, Flink will tigger retraction and then send the latest record again every time when your user table changes. Best, Kurt On Sat, Jan 4, 2020 at 5:09 AM RKandoji <[hidden email]> wrote:
|
|
|
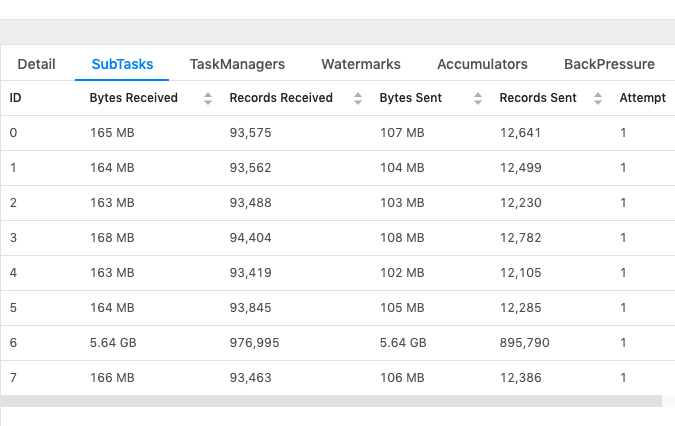
Hi Kurt, I understand what you mean, some userIds may appear more frequently than the others but this distribution doesn't look in proportionate with the data skew. Do you think of any other possible reasons or anything I can try out to investigate this more? For DeDuplication, I query for the latest record. Sorry I didn't follow above sentence, do you mean that for each update to user table the record(s) that were updated will be sent via retract stream.I think that's expected as I need to process latest records, as long as it is sending only the record(s) that's been updated. Thanks, RKandoji On Fri, Jan 3, 2020 at 9:57 PM Kurt Young <[hidden email]> wrote:
|
Re: Duplicate tasks for the same query
|
|
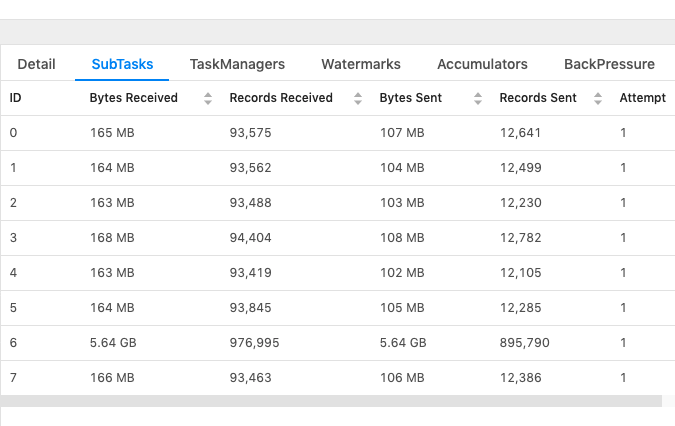
Another common skew case we've seen is null handling, the value of the join key is NULL. We will shuffle the NULL value into one task even if the join condition won't stand by definition. For DeDuplication, I just want to make sure this behavior meets your requirement. Because for some other usages, users might be only interested with the earliest records because the updating for the same key is purely redundant, like caused by upstream failure and process the same data again. In that case, each key will only have at most one record and you won't face any join key skewing issue. Best, Kurt On Mon, Jan 6, 2020 at 6:55 AM RKandoji <[hidden email]> wrote:
|
|
|
hi Kurt, Thanks for the additional info. RK On Sun, Jan 5, 2020 at 8:33 PM Kurt Young <[hidden email]> wrote:
|
|
|
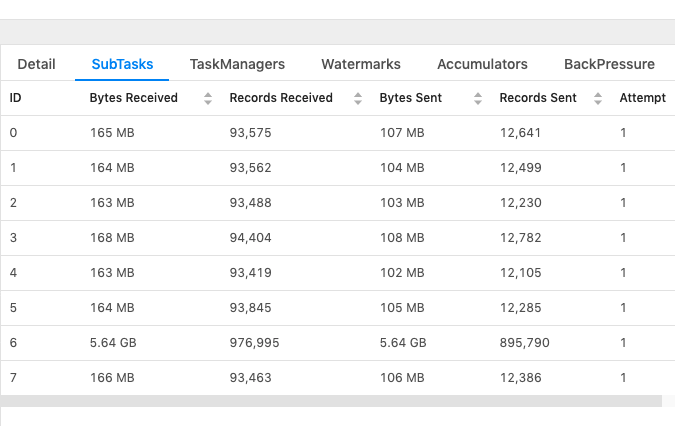
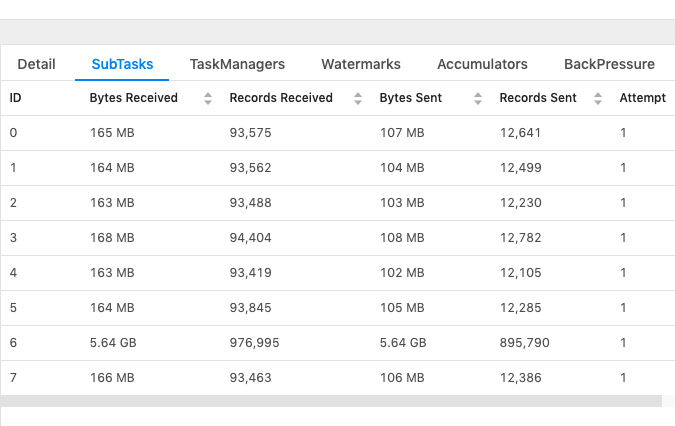
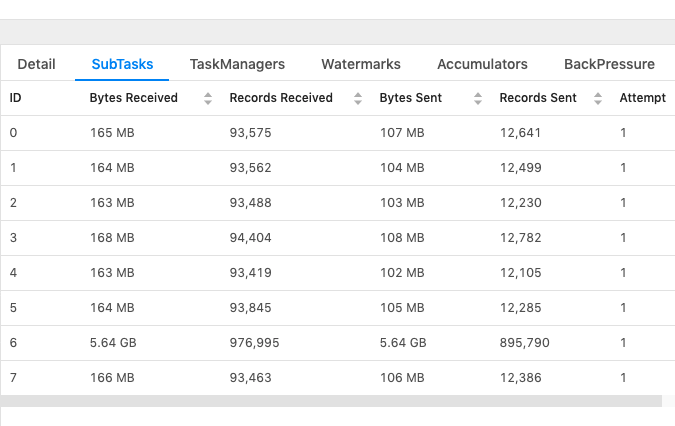
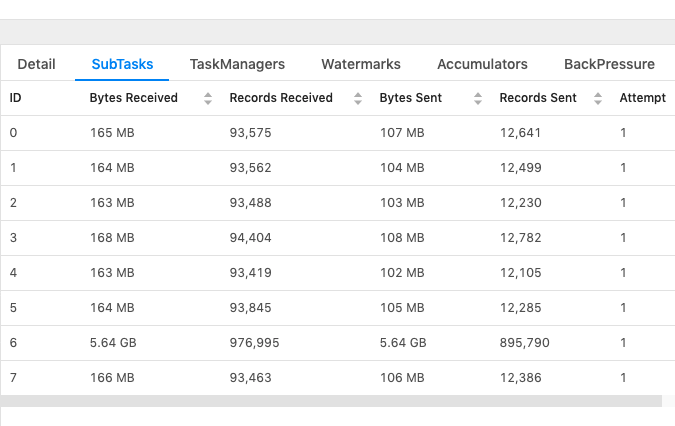
Hi Everyone, Continuing to post my questions on the same email chain as it has more context for my use case, please let me know in case you prefer a new email. This is related to checkpointing, I'm trying to understand how much memory does checkpointing need? From my observation it looks way more than the amount of input data being fed. Below are more details: Job details: - Blink Planner - Job Parallelism = 26 - Based on my join query, I see total 17 tasks created (I'm not sure if "task" is the correct term, I'm referring to the number of operations shown in the main "Overview" page) - 4 of these are Source tasks reading data from different Kafka sources, 4 other tasks are performing DeDuplication for the Kafka source data and rest of the tasks are performing JOINs. At a given moment the total input data consumed by the job is less than 6GB (by combining individual "Bytes Sent" for Source tasks shown below), whereas the total storage consumed by checkpointing is 23GB.  I'm failing to understand why checkpointing is taking up so much space, is it because it stores the state of each task separately (and I have 17 tasks, with 26 parallelism)? Could someone please help me understand so I can plan memory requirement well. Thanks, RKandoji On Tue, Jan 7, 2020 at 5:42 PM RKandoji <[hidden email]> wrote:
|
|
|
Could someone please respond to my above question. Why does checkpointing take a lot more space than the actual amount of data its processing? And is there any way to estimate the amount of space checkpointing needs for planning purposes? Thanks, Reva On Wed, Jan 8, 2020 at 6:38 PM RKandoji <[hidden email]> wrote:
|

|
|
Hi Reva, Could you attach the job graph in the Overview page? From my point of view, the job takes up 23 GB checkpoint size is as expected. In Flink, each stateful operator will occupy some checkpoint size to store the state. The total checkpoint size is not only determined by the source, but the operators. If you want to calculate the state size of a stateful operator, you can image the stateful operator is a materialized view or persisted cache of the operator result, the state size is approximate to the persisted cache size. For example, - deduplicate by last row: the state size is approximate to the data size of last rows of input, assuming the operator input size is 5G, and the duplicate rate is 20%, the the state size is approximate to 4G. - stream-stream join: it will keep two states for each inputs, assuming each join input size is 5G, then the join state size is approximate to 10G. If we have 2 sources which both have 6G, then the total state size is approximate to 20G source1 source2 \ / deduplicate(5G) deduplicate(5G) \ / join (10G) Hope that will help you. Best, Jark On Sat, 8 Feb 2020 at 06:41, RKandoji <[hidden email]> wrote:
|

«
Return to (DEPRECATED) Apache Flink User Mailing List archive.
|
1 view|%1 views
| Free forum by Nabble | Edit this page |