Flink streaming sql是否支持两层group by聚合

Flink streaming sql是否支持两层group by聚合

|
Hi all: 我们有个streaming sql得到的结果不正确,现象是sink得到的数据一会大一会小,我们想确认下,这是否是个bug, 或者flink还不支持这种sql。 具体场景是:先group by A, B两个维度计算UV,然后再group by A 把维度B的UV sum起来,对应的SQL如下:(A -> dt, B -> pvareaid) SELECT dt, SUM(a.uv) AS uv sink接收到的数据对应日志为: 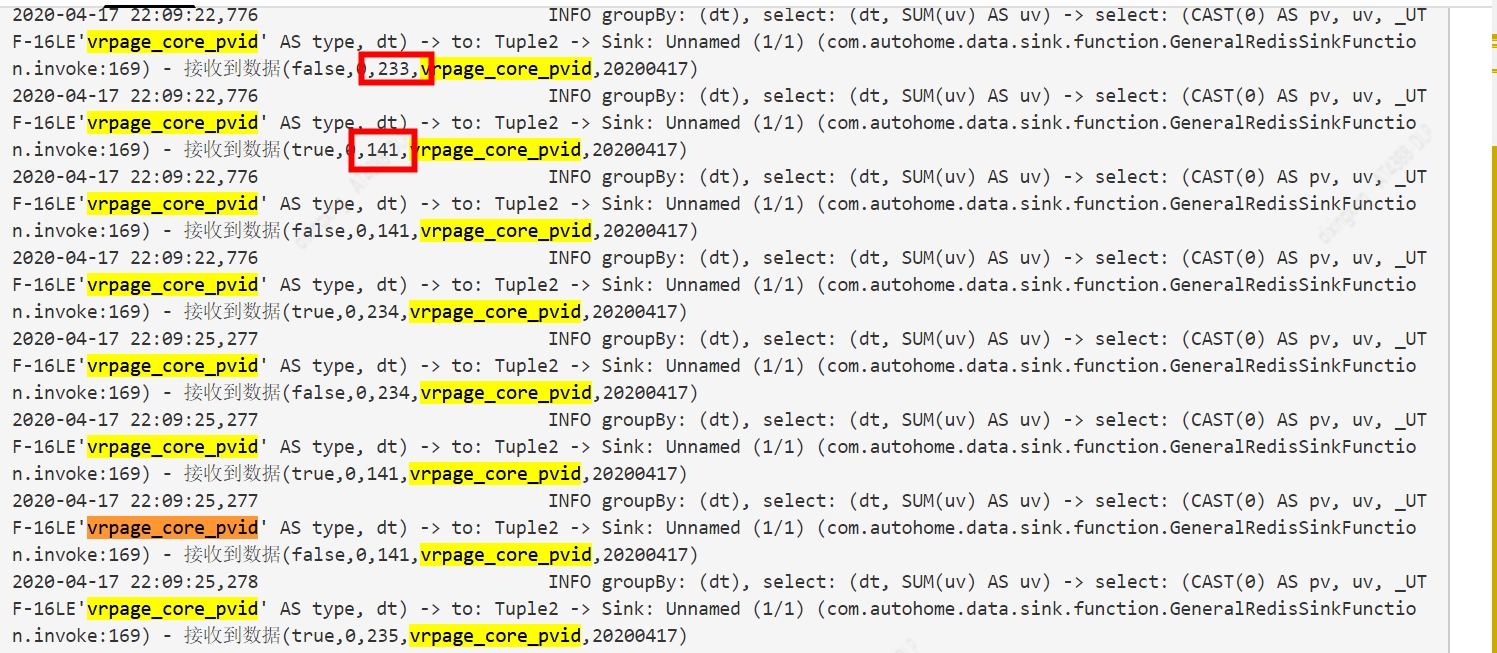 我们使用的是1.7.2, 测试作业的并行度为1。 这是对应的 issue: https://issues.apache.org/jira/browse/FLINK-17228 |
Flink streaming sql是否支持两层group by聚合
|
|
|
Re: Flink streaming sql是否支持两层group by聚合
|
|
Hi, 这个是支持的哈。 你看到的现象是因为group by会产生retract结果,也就是会先发送-[old],再发送+[new]. 如果是两层的话,就成了: 第一层-[old], 第二层-[cur], +[old] 第一层+[new], 第二层[-old], +[new]
Benchao Li School of Electronics Engineering and Computer Science, Peking University Tel:+86-15650713730 Email: [hidden email]; [hidden email] |
Re: Flink streaming sql是否支持两层group by聚合
|
|
多谢benchao, 我这个作业的结果预期结果是每天只有一个结果,这个结果应该是越来越大的,比如:20200417,86 20200417,90 20200417,130 20200417,131 而不应该是忽大忽小的,数字由大变小,这样的结果需求方肯定不能接受的: 20200417,90 20200417,86 20200417,130 20200417,86 20200417,131 我的疑问是内层的group by产生的retract流,会影响sink吗,我是在sink端打的日志。 如果flink支持这种两层group by的话,那这种结果变小的情况应该算是bug吧?
Sent from my iPhone On Apr 18, 2020, at 10:08, Benchao Li <[hidden email]> wrote:
|
Re: Flink streaming sql是否支持两层group by聚合
|
|
这个按照目前的设计,应该不能算是bug,应该是by desigh的。 主要问题还是因为有两层agg,第一层的agg的retract会导致第二层的agg重新计算和下发结果。 dixingxing85 <[hidden email]>于2020年4月18日 周六上午11:38写道:
Benchao Li School of Electronics Engineering and Computer Science, Peking University Tel:+86-15650713730 Email: [hidden email]; [hidden email] |
|
|
Hi, I will use English because we are also sending to user@ ML. This behavior is as expected, not a bug. Benchao gave a good explanation about the reason. I will give some further explanation. In Flink SQL, we will split an update operation (such as uv from 100 -> 101) into two separate messages, one is -[key, 100], the other is +[key, 101]. Once these two messages arrive the downstream aggregation, it will also send two result messages (assuming the previous SUM(uv) is 500), one is [key, 400], the other is [key, 501]. But this problem is almost addressed since 1.9, if you enabled the mini-batch optimization [1]. Because mini-batch optimization will try best to the accumulate the separate + and - message in a single mini-batch processing. You can upgrade and have a try. Best, Jark On Sat, 18 Apr 2020 at 12:26, Benchao Li <[hidden email]> wrote:
|
Re: Re: Flink streaming sql是否支持两层group by聚合
|
|
@Benchao @Jark thank you very much. We have use flink 1.9 for a while , and we will try 1.9 + minibatch.
|
Re: Flink streaming sql是否支持两层group by聚合
|
|
In reply to this post by Jark Wu-3
Hi Jark and Benchao I have learned from your previous email on how to do pv/uv in flink sql. One is to make a yyyyMMdd grouping, the other is to make a day window. Thank you all. I have a question about the result output. For yyyyMMdd grouping, every minute the database would get a record, and many records would be in the database as time goes on, but there would be only a few records in the database according to the day window. for example, the pv would be 12:00,100 12:01,200 12:02,300 12:03,400 according to the yyyyMMdd grouping solution, for the day window solution, there would be only one record as
12:00,100 |12:01,200|12:02,300|12:03,400. I wonder, for the day window solution, is it possible to have the same result output as the yyyyMMdd solution? because the day window solution has no worry about the state retention. Thanks. Yours sincerely Josh On Sat, Apr 18, 2020 at 9:38 PM Jark Wu <[hidden email]> wrote:
|
Re: Flink streaming sql是否支持两层group by聚合
|
|
Hi Jark and Benchao, There are three more weird things about the pv uv in Flink SQL. As I described in the above email, I computed the pv uv in two method, I list them below: For the day grouping one, the sql is
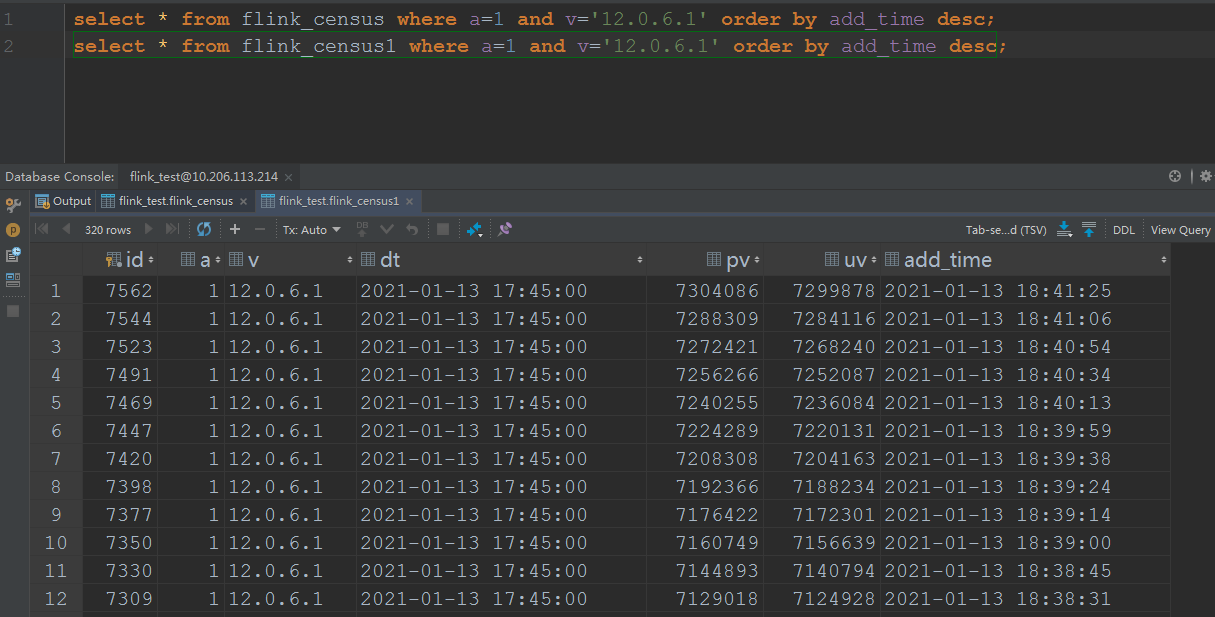
And the result of one dimension is 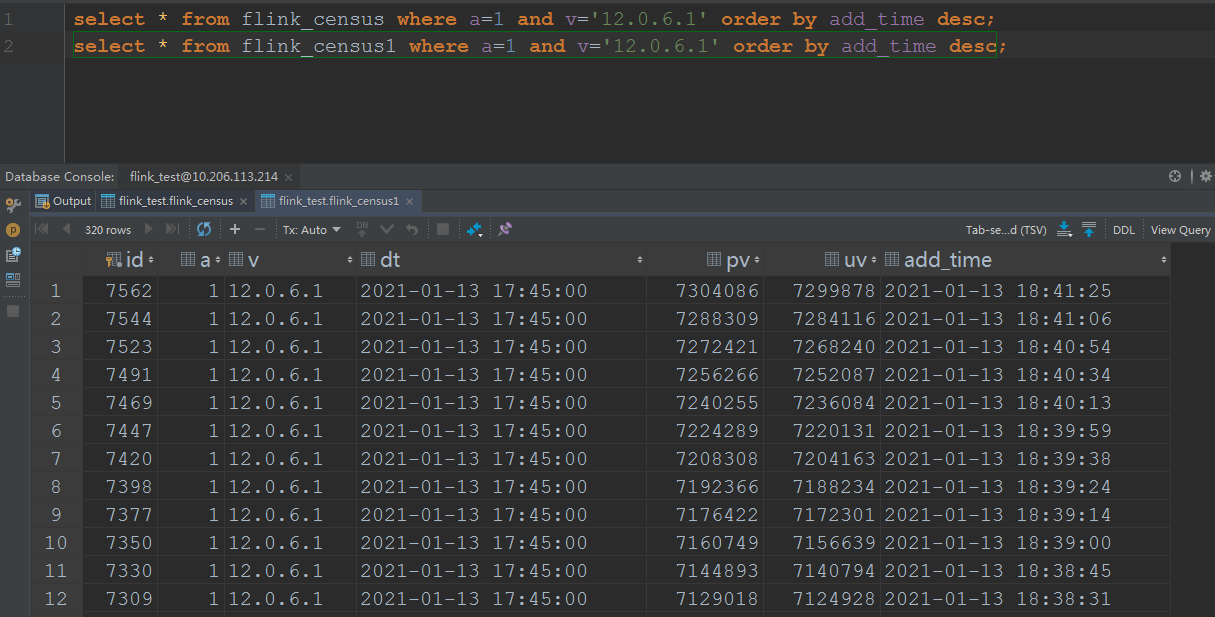 For the 1 day window one, the sql is insert into pvuv_sink select a,v,MAX(DATE_FORMAT(ts, 'yyyy-MM-dd HH:mm:00')) dt, COUNT(m2) AS pv, COUNT(DISTINCT m2) AS uv from kafkaTable GROUP BY tumble(ts, interval '1' day),a,v; And the result of one dimension is 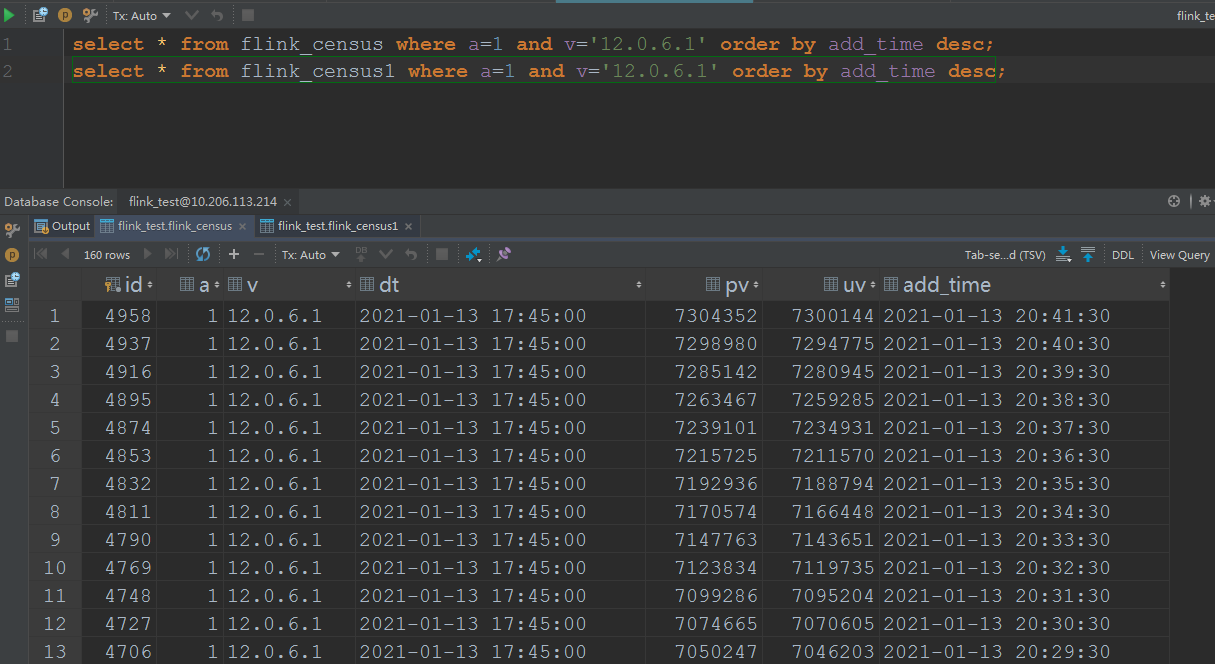 Here are the three questions: 1. According to the same cpu and memory and parallelism, but the day grouping solution is faster than the 1 day window solution, the day grouping solution cost 1 hour to consume all the data, but the 1 day window solution cost 4 hours to consume all the data. 2. The final result is not the same, the pv/uv of the day grouping is 7304086/7299878, but the pv/uv of the 1 day window is 7304352/7300144, I think both of the result is not accurate, but approximate? So, how about the loss of accuracy? What is the algorithm below the count distinct? 3. As the picture of the 1 day window shows, there are many records of the a=1, v=12.0.6.1, dt=2021-01-13 17:45:00, but in my last mail, I noticed the records changed always when the job begin to execute, and one record per dimension, now on the final time, it popped up so many records per dimension, it's weird. Any advice will be fully appreciated. Yours sincerely Josh
On Wed, Jan 13, 2021 at 7:24 PM Joshua Fan <[hidden email]> wrote:
|
|
|
In reply to this post by Joshua Fan
Hi I have learned from the community on how to do pv/uv in flink sql. One is to make a yyyyMMdd grouping, the other is to make a day window. Thank you all. I have a question about the result output. For yyyyMMdd grouping, every minute the database would get a record, and many records would be in the database as time goes on, but there would be only a few records in the database according to the day window. for example, the pv would be 12:00,100 12:01,200 12:02,300 12:03,400 according to the yyyyMMdd grouping solution, for the day window solution, there would be only one record as
12:00,100 |12:01,200|12:02,300|12:03,400. I wonder, for the day window solution, is it possible to have the same result output as the yyyyMMdd solution? because the day window solution has no worry about the state retention. Thanks. Yours sincerely Josh |
Re: Problems about pv uv in flink sql
|
|
There are three more weird things about the pv uv in Flink SQL. As I described in the above email, I computed the pv uv in two method, I list them below: For the day grouping one, the sql is
And the result of one dimension is 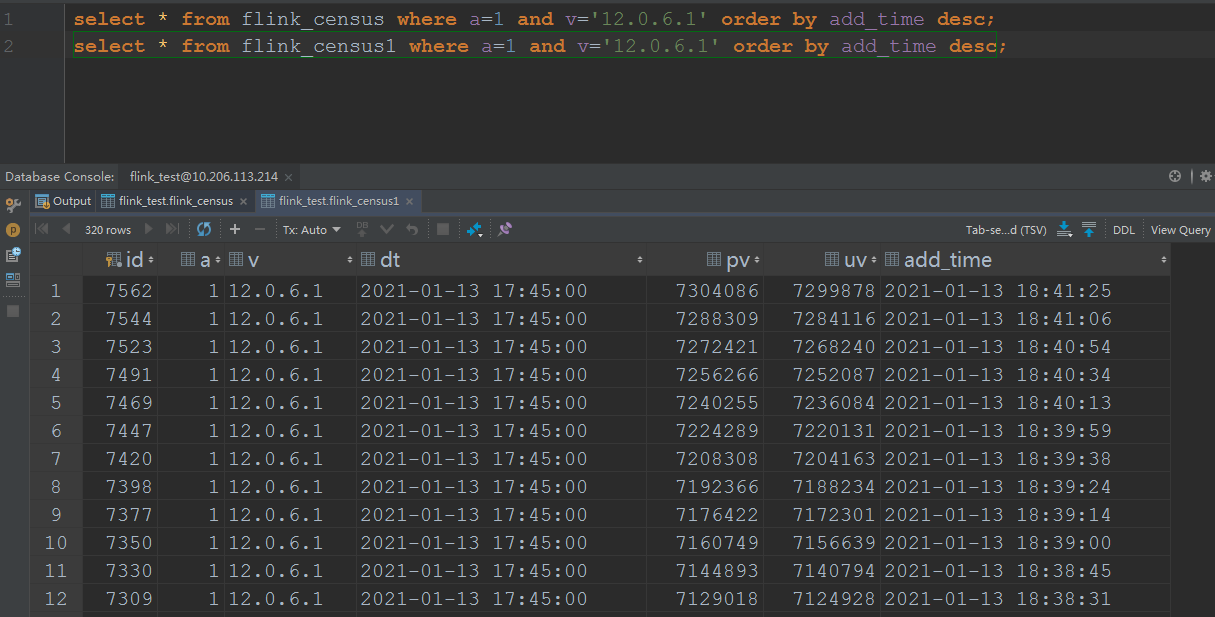 For the 1 day window one, the sql is insert into pvuv_sink select a,v,MAX(DATE_FORMAT(ts, 'yyyy-MM-dd HH:mm:00')) dt, COUNT(m2) AS pv, COUNT(DISTINCT m2) AS uv from kafkaTable GROUP BY tumble(ts, interval '1' day),a,v; And the result of one dimension is 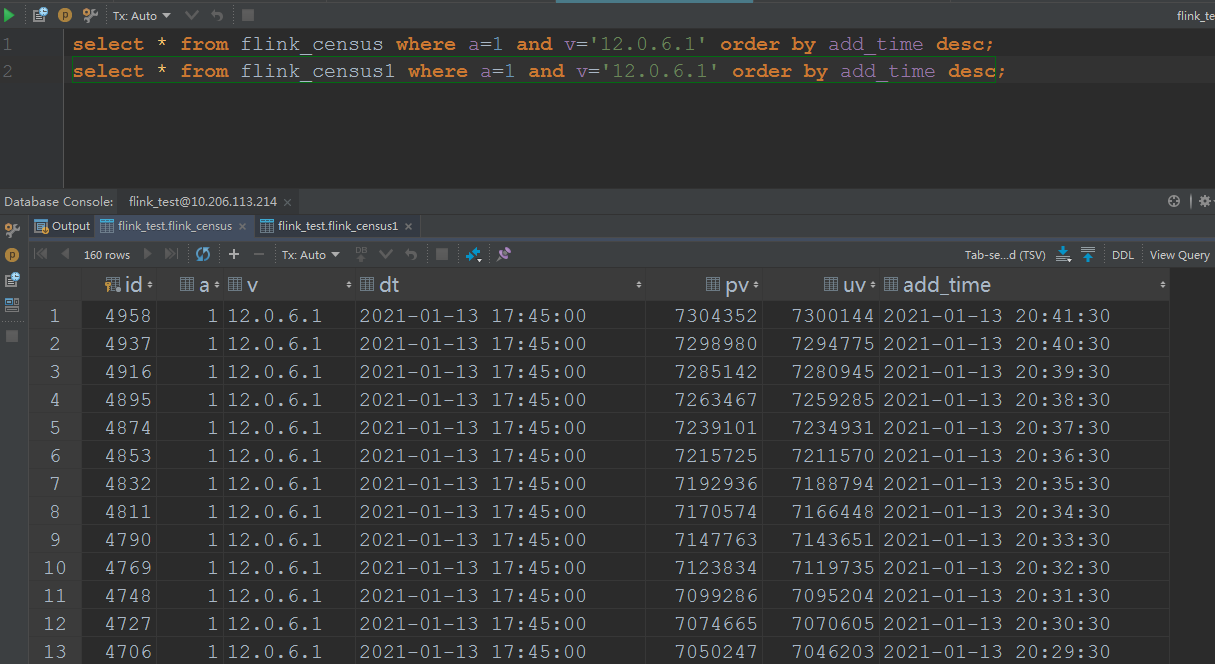 Here are the three questions: 1. According to the same cpu and memory and parallelism, but the day grouping solution is faster than the 1 day window solution, the day grouping solution cost 1 hour to consume all the data, but the 1 day window solution cost 4 hours to consume all the data. 2. The final result is not the same, the pv/uv of the day grouping is 7304086/7299878, but the pv/uv of the 1 day window is 7304352/7300144, I think both of the result is not accurate, but approximate? So, how about the loss of accuracy? What is the algorithm below the count distinct? 3. As the picture of the 1 day window shows, there are many records of the a=1, v=12.0.6.1, dt=2021-01-13 17:45:00, but in my last mail, I noticed the records changed always when the job begin to execute, and one record per dimension, now on the final time, it popped up so many records per dimension, it's weird. Any advice will be fully appreciated. Yours sincerely Josh
On Tue, Jan 19, 2021 at 2:49 PM Joshua Fan <[hidden email]> wrote:
|
Re: Problems about pv uv in flink sql
|
|
Anyone can help? On Tue, Jan 19, 2021 at 2:50 PM Joshua Fan <[hidden email]> wrote:
|
«
Return to (DEPRECATED) Apache Flink User Mailing List archive.
|
1 view|%1 views
| Free forum by Nabble | Edit this page |