Flink job hangs using rocksDb as backend


|
Hi,
I am using flink 1.4.2 with rocksdb as backend. I am using process function with timer on EventTime. For checkpointing I am using hdfs. I am trying load testing so Iam reading kafka from beginning (aprox 7 days data with 50M events). My job gets stuck after aprox 20 min with no error. There after watermark do not progress and all checkpoint fails. Also When I try to cancel my job (using web UI) , it takes several minutes to finally gets cancelled. Also it makes Task manager down as well. There is no logs while my job hanged but while cancelling I get following error. / 2018-07-11 09:10:39,385 ERROR org.apache.flink.runtime.taskmanager.TaskManager - ============================================================== ====================== FATAL ======================= ============================================================== A fatal error occurred, forcing the TaskManager to shut down: Task 'process (3/6)' did not react to cancelling signal in the last 30 seconds, but is stuck in method: org.rocksdb.RocksDB.get(Native Method) org.rocksdb.RocksDB.get(RocksDB.java:810) org.apache.flink.contrib.streaming.state.RocksDBMapState.get(RocksDBMapState.java:102) org.apache.flink.runtime.state.UserFacingMapState.get(UserFacingMapState.java:47) nl.ing.gmtt.observer.analyser.job.rtpe.process.RtpeProcessFunction.onTimer(RtpeProcessFunction.java:94) org.apache.flink.streaming.api.operators.KeyedProcessOperator.onEventTime(KeyedProcessOperator.java:75) org.apache.flink.streaming.api.operators.HeapInternalTimerService.advanceWatermark(HeapInternalTimerService.java:288) org.apache.flink.streaming.api.operators.InternalTimeServiceManager.advanceWatermark(InternalTimeServiceManager.java:108) org.apache.flink.streaming.api.operators.AbstractStreamOperator.processWatermark(AbstractStreamOperator.java:885) org.apache.flink.streaming.runtime.io.StreamInputProcessor$ForwardingValveOutputHandler.handleWatermark(StreamInputProcessor.java:288) org.apache.flink.streaming.runtime.streamstatus.StatusWatermarkValve.findAndOutputNewMinWatermarkAcrossAlignedChannels(StatusWatermarkValve.java:189) org.apache.flink.streaming.runtime.streamstatus.StatusWatermarkValve.inputWatermark(StatusWatermarkValve.java:111) org.apache.flink.streaming.runtime.io.StreamInputProcessor.processInput(StreamInputProcessor.java:189) org.apache.flink.streaming.runtime.tasks.OneInputStreamTask.run(OneInputStreamTask.java:69) org.apache.flink.streaming.runtime.tasks.StreamTask.invoke(StreamTask.java:264) org.apache.flink.runtime.taskmanager.Task.run(Task.java:718) java.lang.Thread.run(Thread.java:748) 2018-07-11 09:10:39,390 DEBUG org.apache.flink.runtime.akka.StoppingSupervisorWithoutLoggingActorKilledExceptionStrategy - Actor was killed. Stopping it now. akka.actor.ActorKilledException: Kill 2018-07-11 09:10:39,407 INFO org.apache.flink.runtime.taskmanager.TaskManager - Stopping TaskManager akka://flink/user/taskmanager#-1231617791. 2018-07-11 09:10:39,408 INFO org.apache.flink.runtime.taskmanager.TaskManager - Cancelling all computations and discarding all cached data. 2018-07-11 09:10:39,409 INFO org.apache.flink.runtime.taskmanager.Task - Attempting to fail task externally process (3/6) (432fd129f3eea363334521f8c8de5198). 2018-07-11 09:10:39,409 INFO org.apache.flink.runtime.taskmanager.Task - Task process (3/6) is already in state CANCELING 2018-07-11 09:10:39,409 INFO org.apache.flink.runtime.taskmanager.Task - Attempting to fail task externally process (4/6) (7c6b96c9f32b067bdf8fa7c283eca2e0). 2018-07-11 09:10:39,409 INFO org.apache.flink.runtime.taskmanager.Task - Task process (4/6) is already in state CANCELING 2018-07-11 09:10:39,409 INFO org.apache.flink.runtime.taskmanager.Task - Attempting to fail task externally process (2/6) (a4f731797a7ea210fd0b512b0263bcd9). 2018-07-11 09:10:39,409 INFO org.apache.flink.runtime.taskmanager.Task - Task process (2/6) is already in state CANCELING 2018-07-11 09:10:39,409 INFO org.apache.flink.runtime.taskmanager.Task - Attempting to fail task externally process (1/6) (cd8a113779a4c00a051d78ad63bc7963). 2018-07-11 09:10:39,409 INFO org.apache.flink.runtime.taskmanager.Task - Task process (1/6) is already in state CANCELING 2018-07-11 09:10:39,409 INFO org.apache.flink.runtime.taskmanager.TaskManager - Disassociating from JobManager 2018-07-11 09:10:39,412 INFO org.apache.flink.runtime.blob.PermanentBlobCache - Shutting down BLOB cache 2018-07-11 09:10:39,431 INFO org.apache.flink.runtime.blob.TransientBlobCache - Shutting down BLOB cache 2018-07-11 09:10:39,444 INFO org.apache.flink.runtime.leaderretrieval.ZooKeeperLeaderRetrievalService - Stopping ZooKeeperLeaderRetrievalService. 2018-07-11 09:10:39,444 DEBUG org.apache.flink.runtime.io.disk.iomanager.IOManager - Shutting down I/O manager. 2018-07-11 09:10:39,451 INFO org.apache.flink.runtime.io.disk.iomanager.IOManager - I/O manager removed spill file directory /tmp/flink-io-989505e5-ac33-4d56-add5-04b2ad3067b4 2018-07-11 09:10:39,461 INFO org.apache.flink.runtime.io.network.NetworkEnvironment - Shutting down the network environment and its components. 2018-07-11 09:10:39,461 DEBUG org.apache.flink.runtime.io.network.NetworkEnvironment - Shutting down network connection manager 2018-07-11 09:10:39,462 INFO org.apache.flink.runtime.io.network.netty.NettyClient - Successful shutdown (took 1 ms). 2018-07-11 09:10:39,472 INFO org.apache.flink.runtime.io.network.netty.NettyServer - Successful shutdown (took 10 ms). 2018-07-11 09:10:39,472 DEBUG org.apache.flink.runtime.io.network.NetworkEnvironment - Shutting down intermediate result partition manager 2018-07-11 09:10:39,473 DEBUG org.apache.flink.runtime.io.network.partition.ResultPartitionManager - Releasing 0 partitions because of shutdown. 2018-07-11 09:10:39,474 DEBUG org.apache.flink.runtime.io.network.partition.ResultPartitionManager - Successful shutdown. 2018-07-11 09:10:39,498 INFO org.apache.flink.runtime.taskmanager.TaskManager - Task manager akka://flink/user/taskmanager is completely shut down. 2018-07-11 09:10:39,504 ERROR org.apache.flink.runtime.taskmanager.TaskManager - Actor akka://flink/user/taskmanager#-1231617791 terminated, stopping process... 2018-07-11 09:10:39,563 INFO org.apache.flink.runtime.taskmanager.Task - Notifying TaskManager about fatal error. Task 'process (2/6)' did not react to cancelling signal in the last 30 seconds, but is stuck in method: org.rocksdb.RocksDB.get(Native Method) org.rocksdb.RocksDB.get(RocksDB.java:810) org.apache.flink.contrib.streaming.state.RocksDBMapState.get(RocksDBMapState.java:102) org.apache.flink.runtime.state.UserFacingMapState.get(UserFacingMapState.java:47) nl.ing.gmtt.observer.analyser.job.rtpe.process.RtpeProcessFunction.onTimer(RtpeProcessFunction.java:94) org.apache.flink.streaming.api.operators.KeyedProcessOperator.onEventTime(KeyedProcessOperator.java:75) org.apache.flink.streaming.api.operators.HeapInternalTimerService.advanceWatermark(HeapInternalTimerService.java:288) org.apache.flink.streaming.api.operators.InternalTimeServiceManager.advanceWatermark(InternalTimeServiceManager.java:108) org.apache.flink.streaming.api.operators.AbstractStreamOperator.processWatermark(AbstractStreamOperator.java:885) org.apache.flink.streaming.runtime.io.StreamInputProcessor$ForwardingValveOutputHandler.handleWatermark(StreamInputProcessor.java:288) org.apache.flink.streaming.runtime.streamstatus.StatusWatermarkValve.findAndOutputNewMinWatermarkAcrossAlignedChannels(StatusWatermarkValve.java:189) org.apache.flink.streaming.runtime.streamstatus.StatusWatermarkValve.inputWatermark(StatusWatermarkValve.java:111) org.apache.flink.streaming.runtime.io.StreamInputProcessor.processInput(StreamInputProcessor.java:189) org.apache.flink.streaming.runtime.tasks.OneInputStreamTask.run(OneInputStreamTask.java:69) org.apache.flink.streaming.runtime.tasks.StreamTask.invoke(StreamTask.java:264) org.apache.flink.runtime.taskmanager.Task.run(Task.java:718) java.lang.Thread.run(Thread.java:748) . 2018-07-11 09:10:39,575 INFO org.apache.flink.runtime.taskmanager.Task - Notifying TaskManager about fatal error. Task 'process (1/6)' did not react to cancelling signal in the last 30 seconds, but is stuck in method: sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45) java.lang.reflect.Constructor.newInstance(Constructor.java:423) java.lang.Class.newInstance(Class.java:442) org.apache.flink.api.java.typeutils.runtime.PojoSerializer.createInstance(PojoSerializer.java:196) org.apache.flink.api.java.typeutils.runtime.PojoSerializer.deserialize(PojoSerializer.java:399) org.apache.flink.contrib.streaming.state.RocksDBMapState.deserializeUserValue(RocksDBMapState.java:304) org.apache.flink.contrib.streaming.state.RocksDBMapState.get(RocksDBMapState.java:104) org.apache.flink.runtime.state.UserFacingMapState.get(UserFacingMapState.java:47) nl.ing.gmtt.observer.analyser.job.rtpe.process.RtpeProcessFunction.onTimer(RtpeProcessFunction.java:94) org.apache.flink.streaming.api.operators.KeyedProcessOperator.onEventTime(KeyedProcessOperator.java:75) org.apache.flink.streaming.api.operators.HeapInternalTimerService.advanceWatermark(HeapInternalTimerService.java:288) org.apache.flink.streaming.api.operators.InternalTimeServiceManager.advanceWatermark(InternalTimeServiceManager.java:108) org.apache.flink.streaming.api.operators.AbstractStreamOperator.processWatermark(AbstractStreamOperator.java:885) org.apache.flink.streaming.runtime.io.StreamInputProcessor$ForwardingValveOutputHandler.handleWatermark(StreamInputProcessor.java:288) org.apache.flink.streaming.runtime.streamstatus.StatusWatermarkValve.findAndOutputNewMinWatermarkAcrossAlignedChannels(StatusWatermarkValve.java:189) org.apache.flink.streaming.runtime.streamstatus.StatusWatermarkValve.inputWatermark(StatusWatermarkValve.java:111) org.apache.flink.streaming.runtime.io.StreamInputProcessor.processInput(StreamInputProcessor.java:189) org.apache.flink.streaming.runtime.tasks.OneInputStreamTask.run(OneInputStreamTask.java:69) org.apache.flink.streaming.runtime.tasks.StreamTask.invoke(StreamTask.java:264) org.apache.flink.runtime.taskmanager.Task.run(Task.java:718) java.lang.Thread.run(Thread.java:748) / -- Sent from: http://apache-flink-user-mailing-list-archive.2336050.n4.nabble.com/ |
Re: Flink job hangs using rocksDb as backend
|
|
Hi shishal!
I think there is an issue with cancellation when many timers fire at the same time. These timers have to finish before shutdown happens, this seems to take a while in your case. Did the TM process actually kill itself in the end (and got restarted)? On Wed, Jul 11, 2018 at 9:29 AM, shishal <[hidden email]> wrote: Hi, |
Re: Flink job hangs using rocksDb as backend
|
|
If this is about too many timers and your application allows it, you may
also try to reduce the timer resolution and thus frequency by coalescing them [1]. Nico [1] https://ci.apache.org/projects/flink/flink-docs-release-1.5/dev/stream/operators/process_function.html#timer-coalescing On 11/07/18 18:27, Stephan Ewen wrote: > Hi shishal! > > I think there is an issue with cancellation when many timers fire at the > same time. These timers have to finish before shutdown happens, this > seems to take a while in your case. > > Did the TM process actually kill itself in the end (and got restarted)? > > > > On Wed, Jul 11, 2018 at 9:29 AM, shishal <[hidden email] > <mailto:[hidden email]>> wrote: > > Hi, > > I am using flink 1.4.2 with rocksdb as backend. I am using process > function > with timer on EventTime. For checkpointing I am using hdfs. > > I am trying load testing so Iam reading kafka from beginning (aprox > 7 days > data with 50M events). > > My job gets stuck after aprox 20 min with no error. There after > watermark do > not progress and all checkpoint fails. > > Also When I try to cancel my job (using web UI) , it takes several > minutes > to finally gets cancelled. Also it makes Task manager down as well. > > There is no logs while my job hanged but while cancelling I get > following > error. > > / > > 2018-07-11 09:10:39,385 ERROR > org.apache.flink.runtime.taskmanager.TaskManager - > ============================================================== > ====================== FATAL ======================= > ============================================================== > > A fatal error occurred, forcing the TaskManager to shut down: Task > 'process > (3/6)' did not react to cancelling signal in the last 30 seconds, but is > stuck in method: > org.rocksdb.RocksDB.get(Native Method) > org.rocksdb.RocksDB.get(RocksDB.java:810) > org.apache.flink.contrib.streaming.state.RocksDBMapState.get(RocksDBMapState.java:102) > org.apache.flink.runtime.state.UserFacingMapState.get(UserFacingMapState.java:47) > nl.ing.gmtt.observer.analyser.job.rtpe.process.RtpeProcessFunction.onTimer(RtpeProcessFunction.java:94) > org.apache.flink.streaming.api.operators.KeyedProcessOperator.onEventTime(KeyedProcessOperator.java:75) > org.apache.flink.streaming.api.operators.HeapInternalTimerService.advanceWatermark(HeapInternalTimerService.java:288) > org.apache.flink.streaming.api.operators.InternalTimeServiceManager.advanceWatermark(InternalTimeServiceManager.java:108) > org.apache.flink.streaming.api.operators.AbstractStreamOperator.processWatermark(AbstractStreamOperator.java:885) > org.apache.flink.streaming.runtime.io > <http://runtime.io>.StreamInputProcessor$ForwardingValveOutputHandler.handleWatermark(StreamInputProcessor.java:288) > org.apache.flink.streaming.runtime.streamstatus.StatusWatermarkValve.findAndOutputNewMinWatermarkAcrossAlignedChannels(StatusWatermarkValve.java:189) > org.apache.flink.streaming.runtime.streamstatus.StatusWatermarkValve.inputWatermark(StatusWatermarkValve.java:111) > org.apache.flink.streaming.runtime.io > <http://runtime.io>.StreamInputProcessor.processInput(StreamInputProcessor.java:189) > org.apache.flink.streaming.runtime.tasks.OneInputStreamTask.run(OneInputStreamTask.java:69) > org.apache.flink.streaming.runtime.tasks.StreamTask.invoke(StreamTask.java:264) > org.apache.flink.runtime.taskmanager.Task.run(Task.java:718) > java.lang.Thread.run(Thread.java:748) > > 2018-07-11 09:10:39,390 DEBUG > org.apache.flink.runtime.akka.StoppingSupervisorWithoutLoggingActorKilledExceptionStrategy > > - Actor was killed. Stopping it now. > akka.actor.ActorKilledException: Kill > 2018-07-11 09:10:39,407 INFO > org.apache.flink.runtime.taskmanager.TaskManager - Stopping > TaskManager akka://flink/user/taskmanager#-1231617791. > 2018-07-11 09:10:39,408 INFO > org.apache.flink.runtime.taskmanager.TaskManager - > Cancelling > all computations and discarding all cached data. > 2018-07-11 09:10:39,409 INFO > org.apache.flink.runtime.taskmanager.Task > - Attempting to fail task externally process (3/6) > (432fd129f3eea363334521f8c8de5198). > 2018-07-11 09:10:39,409 INFO > org.apache.flink.runtime.taskmanager.Task > - Task process (3/6) is already in state CANCELING > 2018-07-11 09:10:39,409 INFO > org.apache.flink.runtime.taskmanager.Task > - Attempting to fail task externally process (4/6) > (7c6b96c9f32b067bdf8fa7c283eca2e0). > 2018-07-11 09:10:39,409 INFO > org.apache.flink.runtime.taskmanager.Task > - Task process (4/6) is already in state CANCELING > 2018-07-11 09:10:39,409 INFO > org.apache.flink.runtime.taskmanager.Task > - Attempting to fail task externally process (2/6) > (a4f731797a7ea210fd0b512b0263bcd9). > 2018-07-11 09:10:39,409 INFO > org.apache.flink.runtime.taskmanager.Task > - Task process (2/6) is already in state CANCELING > 2018-07-11 09:10:39,409 INFO > org.apache.flink.runtime.taskmanager.Task > - Attempting to fail task externally process (1/6) > (cd8a113779a4c00a051d78ad63bc7963). > 2018-07-11 09:10:39,409 INFO > org.apache.flink.runtime.taskmanager.Task > - Task process (1/6) is already in state CANCELING > 2018-07-11 09:10:39,409 INFO > org.apache.flink.runtime.taskmanager.TaskManager - > Disassociating from JobManager > 2018-07-11 09:10:39,412 INFO > org.apache.flink.runtime.blob.PermanentBlobCache - Shutting > down BLOB cache > 2018-07-11 09:10:39,431 INFO > org.apache.flink.runtime.blob.TransientBlobCache - Shutting > down BLOB cache > 2018-07-11 09:10:39,444 INFO > org.apache.flink.runtime.leaderretrieval.ZooKeeperLeaderRetrievalService > - > Stopping ZooKeeperLeaderRetrievalService. > 2018-07-11 09:10:39,444 DEBUG > org.apache.flink.runtime.io > <http://org.apache.flink.runtime.io>.disk.iomanager.IOManager > - Shutting > down I/O manager. > 2018-07-11 09:10:39,451 INFO > org.apache.flink.runtime.io > <http://org.apache.flink.runtime.io>.disk.iomanager.IOManager > - I/O manager > removed spill file directory > /tmp/flink-io-989505e5-ac33-4d56-add5-04b2ad3067b4 > 2018-07-11 09:10:39,461 INFO > org.apache.flink.runtime.io > <http://org.apache.flink.runtime.io>.network.NetworkEnvironment > - Shutting > down the network environment and its components. > 2018-07-11 09:10:39,461 DEBUG > org.apache.flink.runtime.io > <http://org.apache.flink.runtime.io>.network.NetworkEnvironment > - Shutting > down network connection manager > 2018-07-11 09:10:39,462 INFO > org.apache.flink.runtime.io > <http://org.apache.flink.runtime.io>.network.netty.NettyClient > - Successful > shutdown (took 1 ms). > 2018-07-11 09:10:39,472 INFO > org.apache.flink.runtime.io > <http://org.apache.flink.runtime.io>.network.netty.NettyServer > - Successful > shutdown (took 10 ms). > 2018-07-11 09:10:39,472 DEBUG > org.apache.flink.runtime.io > <http://org.apache.flink.runtime.io>.network.NetworkEnvironment > - Shutting > down intermediate result partition manager > 2018-07-11 09:10:39,473 DEBUG > org.apache.flink.runtime.io > <http://org.apache.flink.runtime.io>.network.partition.ResultPartitionManager > - > Releasing 0 partitions because of shutdown. > 2018-07-11 09:10:39,474 DEBUG > org.apache.flink.runtime.io > <http://org.apache.flink.runtime.io>.network.partition.ResultPartitionManager > - > Successful shutdown. > 2018-07-11 09:10:39,498 INFO > org.apache.flink.runtime.taskmanager.TaskManager - Task > manager > akka://flink/user/taskmanager is completely shut down. > 2018-07-11 09:10:39,504 ERROR > org.apache.flink.runtime.taskmanager.TaskManager - Actor > akka://flink/user/taskmanager#-1231617791 terminated, stopping > process... > 2018-07-11 09:10:39,563 INFO > org.apache.flink.runtime.taskmanager.Task > - Notifying TaskManager about fatal error. Task 'process (2/6)' did not > react to cancelling signal in the last 30 seconds, but is stuck in > method: > org.rocksdb.RocksDB.get(Native Method) > org.rocksdb.RocksDB.get(RocksDB.java:810) > org.apache.flink.contrib.streaming.state.RocksDBMapState.get(RocksDBMapState.java:102) > org.apache.flink.runtime.state.UserFacingMapState.get(UserFacingMapState.java:47) > nl.ing.gmtt.observer.analyser.job.rtpe.process.RtpeProcessFunction.onTimer(RtpeProcessFunction.java:94) > org.apache.flink.streaming.api.operators.KeyedProcessOperator.onEventTime(KeyedProcessOperator.java:75) > org.apache.flink.streaming.api.operators.HeapInternalTimerService.advanceWatermark(HeapInternalTimerService.java:288) > org.apache.flink.streaming.api.operators.InternalTimeServiceManager.advanceWatermark(InternalTimeServiceManager.java:108) > org.apache.flink.streaming.api.operators.AbstractStreamOperator.processWatermark(AbstractStreamOperator.java:885) > org.apache.flink.streaming.runtime.io > <http://runtime.io>.StreamInputProcessor$ForwardingValveOutputHandler.handleWatermark(StreamInputProcessor.java:288) > org.apache.flink.streaming.runtime.streamstatus.StatusWatermarkValve.findAndOutputNewMinWatermarkAcrossAlignedChannels(StatusWatermarkValve.java:189) > org.apache.flink.streaming.runtime.streamstatus.StatusWatermarkValve.inputWatermark(StatusWatermarkValve.java:111) > org.apache.flink.streaming.runtime.io > <http://runtime.io>.StreamInputProcessor.processInput(StreamInputProcessor.java:189) > org.apache.flink.streaming.runtime.tasks.OneInputStreamTask.run(OneInputStreamTask.java:69) > org.apache.flink.streaming.runtime.tasks.StreamTask.invoke(StreamTask.java:264) > org.apache.flink.runtime.taskmanager.Task.run(Task.java:718) > java.lang.Thread.run(Thread.java:748) > . > 2018-07-11 09:10:39,575 INFO > org.apache.flink.runtime.taskmanager.Task > - Notifying TaskManager about fatal error. Task 'process (1/6)' did not > react to cancelling signal in the last 30 seconds, but is stuck in > method: > > sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45) > java.lang.reflect.Constructor.newInstance(Constructor.java:423) > java.lang.Class.newInstance(Class.java:442) > org.apache.flink.api.java.typeutils.runtime.PojoSerializer.createInstance(PojoSerializer.java:196) > org.apache.flink.api.java.typeutils.runtime.PojoSerializer.deserialize(PojoSerializer.java:399) > org.apache.flink.contrib.streaming.state.RocksDBMapState.deserializeUserValue(RocksDBMapState.java:304) > org.apache.flink.contrib.streaming.state.RocksDBMapState.get(RocksDBMapState.java:104) > org.apache.flink.runtime.state.UserFacingMapState.get(UserFacingMapState.java:47) > nl.ing.gmtt.observer.analyser.job.rtpe.process.RtpeProcessFunction.onTimer(RtpeProcessFunction.java:94) > org.apache.flink.streaming.api.operators.KeyedProcessOperator.onEventTime(KeyedProcessOperator.java:75) > org.apache.flink.streaming.api.operators.HeapInternalTimerService.advanceWatermark(HeapInternalTimerService.java:288) > org.apache.flink.streaming.api.operators.InternalTimeServiceManager.advanceWatermark(InternalTimeServiceManager.java:108) > org.apache.flink.streaming.api.operators.AbstractStreamOperator.processWatermark(AbstractStreamOperator.java:885) > org.apache.flink.streaming.runtime.io > <http://runtime.io>.StreamInputProcessor$ForwardingValveOutputHandler.handleWatermark(StreamInputProcessor.java:288) > org.apache.flink.streaming.runtime.streamstatus.StatusWatermarkValve.findAndOutputNewMinWatermarkAcrossAlignedChannels(StatusWatermarkValve.java:189) > org.apache.flink.streaming.runtime.streamstatus.StatusWatermarkValve.inputWatermark(StatusWatermarkValve.java:111) > org.apache.flink.streaming.runtime.io > <http://runtime.io>.StreamInputProcessor.processInput(StreamInputProcessor.java:189) > org.apache.flink.streaming.runtime.tasks.OneInputStreamTask.run(OneInputStreamTask.java:69) > org.apache.flink.streaming.runtime.tasks.StreamTask.invoke(StreamTask.java:264) > org.apache.flink.runtime.taskmanager.Task.run(Task.java:718) > java.lang.Thread.run(Thread.java:748) > / > > > > -- > Sent from: > http://apache-flink-user-mailing-list-archive.2336050.n4.nabble.com/ > <http://apache-flink-user-mailing-list-archive.2336050.n4.nabble.com/> > > Nico Kruber | Software Engineer data Artisans Follow us @dataArtisans -- Join Flink Forward - The Apache Flink Conference Stream Processing | Event Driven | Real Time -- Data Artisans GmbH | Stresemannstr. 121A,10963 Berlin, Germany data Artisans, Inc. | 1161 Mission Street, San Francisco, CA-94103, USA -- Data Artisans GmbH Registered at Amtsgericht Charlottenburg: HRB 158244 B Managing Directors: Dr. Kostas Tzoumas, Dr. Stephan Ewen |
Re: Flink job hangs using rocksDb as backend
|
|
Hi,
adding to what has already been said, I think that here can be two orthogonal problems here: i) why is your job slowing down/getting stuck? and ii) why is cancellation blocked? As for ii) I think Stephan already gave to right reason that shutdown could take longer and that is what gets the TM killed. A more interesting question could still be i), why is your job slowing down until shutdown in the first place. I have two questions here.First, are you running on RocksDB on EBS volumes, then please have a look at this thread [1] because there can be some performance pitfalls. Second, how many timers are you expecting, and how are they firing? For example, if you have a huge amount of timers and the watermark makes a bug jump, there is a possibility that it takes a while until the job makes progress because it has to handle so many timer callbacks first. Metrics from even throughput and from your I/O subsystem could be helpful to see if something is stuck/underperforming or if there is just a lot of timer processing going on. Best, Stefan
|
|
|
Thanks Stefan/Stephan/Nico,
Indeed there are 2 problem. For the 2nd problem ,I am almost certain that explanation given by Stephan is the true as in my case as there number of timers are in millions. (Each for different key so I guess coalescing is not an option for me). If I simplify my problem, each day I receive millions of events (10-20M) and I have to schedule a timer for next day 8 AM to check if matching events are there , if not I have to send it to Elastic sink as Alert. I suspected that having so many timers fires at same time could cause my jobs to hang, so I am now scheduling times randomly between (8AM-to 10AM). But still my job gets hang after some time. One more thing which I noticed that when my job gets hang CPU utilization shoot to almost 100%. I tried to isolate problem by removing ES sink and just did stream.print() and yet problem persist. In my current setup, I am running a standalone cluster of 3 machine (All three server has Task manger, Job manager and Hadoop on it). So I am not using EBS for rocksDB. Also I verified that when jobs gets hang even timers are not being called as I have debug statement in Timers and only logs I see at that time are following : 2018-07-12 14:35:30,423 DEBUG org.apache.flink.shaded.zookeeper.org.apache.zookeeper.ClientCnxn - Got ping response for sessionid: 0x2648355f7c6010f after 11ms 2018-07-12 14:35:31,957 DEBUG org.apache.flink.runtime.taskmanager.TaskManager - Sending heartbeat to JobManager 2018-07-12 14:35:36,946 DEBUG org.apache.flink.runtime.taskmanager.TaskManager - Sending heartbeat to JobManager 2018-07-12 14:35:41,963 DEBUG org.apache.flink.runtime.taskmanager.TaskManager - Sending heartbeat to JobManager 2018-07-12 14:35:43,775 DEBUG org.apache.flink.shaded.zookeeper.org.apache.zookeeper.ClientCnxn - Got ping response for sessionid: 0x2648355f7c6010f after 10ms 2018-07-12 14:35:46,946 DEBUG org.apache.flink.runtime.taskmanager.TaskManager - Sending heartbeat to JobManager 2018-07-12 14:35:51,954 DEBUG org.apache.flink.runtime.taskmanager.TaskManager - Sending heartbeat to JobManager 2018-07-12 14:35:56,967 DEBUG org.apache.flink.runtime.taskmanager.TaskManager - Sending heartbeat to JobManager 2018-07-12 14:35:57,127 DEBUG org.apache.flink.shaded.zookeeper.org.apache.zookeeper.ClientCnxn - Got ping response for sessionid: 0x2648355f7c6010f after 8ms 2018-07-12 14:36:01,944 DEBUG org.apache.flink.runtime.taskmanager.TaskManager - Sending heartbeat to JobManager 2018-07-12 14:36:06,955 DEBUG org.apache.flink.runtime.taskmanager.TaskManager - Sending heartbeat to JobManager 2018-07-12 14:36:08,287 DEBUG org.apache.flink.runtime.taskmanager.TaskManager - Receiver TriggerCheckpoint 155@1531398968248 for d9af2f1da87b7268cc03e152a6179eae. 2018-07-12 14:36:08,287 DEBUG org.apache.flink.runtime.taskmanager.Task - Invoking async call Checkpoint Trigger for Source: Event Source -> filter (1/1) (d9af2f1da87b7268cc03e152a6179eae). on task Source: Event Source -> filter (1/1) 2018-07-12 14:36:10,476 DEBUG org.apache.flink.shaded.zookeeper.org.apache.zookeeper.ClientCnxn - Got ping response for sessionid: 0x2648355f7c6010f after 10ms 2018-07-12 14:36:11,957 DEBUG org.apache.flink.runtime.taskmanager.TaskManager - Sending heartbeat to JobManager As I expected checkpoint also start to fail during this time. My Job Graph is pretty much simple : Source<Kafka>-->filter--<process with times>--->Sink Regards, Shishal On Thu, Jul 12, 2018 at 9:54 AM Stefan Richter <[hidden email]> wrote:
|
Re: Flink job hangs using rocksDb as backend
|
|
Hi, Best, Stefan
|
|
|
Hi Richer, Actually for the testing , now I have reduced the number of timers to few thousands (5-6K) but my job still gets stuck randomly. And its not reproducible each time. next time when I restart the job it again starts working for few few hours/days then gets stuck again. I took thread dump when my job was hanged with almost 100% cpu . The most cpu taking thread has following stack: It look like sometimes its not able to read data from RocksDB. "process (3/6)" #782 prio=5 os_prio=0 tid=0x00007f68b81ddcf0 nid=0xee73 runnable [0x00007f688d83a000] java.lang.Thread.State: RUNNABLE at org.rocksdb.RocksDB.get(Native Method) at org.rocksdb.RocksDB.get(RocksDB.java:810) at org.apache.flink.contrib.streaming.state.RocksDBMapState.contains(RocksDBMapState.java:137) at org.apache.flink.runtime.state.UserFacingMapState.contains(UserFacingMapState.java:72) at nl.ing.gmtt.observer.analyser.job.rtpe.process.RtpeProcessFunction.isEventExist(RtpeProcessFunction.java:150) at nl.ing.gmtt.observer.analyser.job.rtpe.process.RtpeProcessFunction.onTimer(RtpeProcessFunction.java:93) at org.apache.flink.streaming.api.operators.KeyedProcessOperator.onEventTime(KeyedProcessOperator.java:75) at org.apache.flink.streaming.api.operators.HeapInternalTimerService.advanceWatermark(HeapInternalTimerService.java:288) at org.apache.flink.streaming.api.operators.InternalTimeServiceManager.advanceWatermark(InternalTimeServiceManager.java:108) at org.apache.flink.streaming.api.operators.AbstractStreamOperator.processWatermark(AbstractStreamOperator.java:885) at org.apache.flink.streaming.runtime.io.StreamInputProcessor$ForwardingValveOutputHandler.handleWatermark(StreamInputProcessor.java:288) - locked <0x0000000302b61458> (a java.lang.Object) at org.apache.flink.streaming.runtime.streamstatus.StatusWatermarkValve.findAndOutputNewMinWatermarkAcrossAlignedChannels(StatusWatermarkValve.java:189) at org.apache.flink.streaming.runtime.streamstatus.StatusWatermarkValve.inputWatermark(StatusWatermarkValve.java:111) at org.apache.flink.streaming.runtime.io.StreamInputProcessor.processInput(StreamInputProcessor.java:189) at org.apache.flink.streaming.runtime.tasks.OneInputStreamTask.run(OneInputStreamTask.java:69) at org.apache.flink.streaming.runtime.tasks.StreamTask.invoke(StreamTask.java:264) at org.apache.flink.runtime.taskmanager.Task.run(Task.java:718) at java.lang.Thread.run(Thread.java:748) Locked ownable synchronizers: - None "process (2/6)" #781 prio=5 os_prio=0 tid=0x00007f68b81dcef0 nid=0xee72 runnable [0x00007f688fe54000] java.lang.Thread.State: RUNNABLE at org.rocksdb.RocksDB.get(Native Method) at org.rocksdb.RocksDB.get(RocksDB.java:810) at org.apache.flink.contrib.streaming.state.RocksDBMapState.get(RocksDBMapState.java:102) at org.apache.flink.runtime.state.UserFacingMapState.get(UserFacingMapState.java:47) at nl.ing.gmtt.observer.analyser.job.rtpe.process.RtpeProcessFunction.onTimer(RtpeProcessFunction.java:99) at org.apache.flink.streaming.api.operators.KeyedProcessOperator.onEventTime(KeyedProcessOperator.java:75) at org.apache.flink.streaming.api.operators.HeapInternalTimerService.advanceWatermark(HeapInternalTimerService.java:288) at org.apache.flink.streaming.api.operators.InternalTimeServiceManager.advanceWatermark(InternalTimeServiceManager.java:108) at org.apache.flink.streaming.api.operators.AbstractStreamOperator.processWatermark(AbstractStreamOperator.java:885) at org.apache.flink.streaming.runtime.io.StreamInputProcessor$ForwardingValveOutputHandler.handleWatermark(StreamInputProcessor.java:288) - locked <0x0000000302b404a0> (a java.lang.Object) at org.apache.flink.streaming.runtime.streamstatus.StatusWatermarkValve.findAndOutputNewMinWatermarkAcrossAlignedChannels(StatusWatermarkValve.java:189) at org.apache.flink.streaming.runtime.streamstatus.StatusWatermarkValve.inputWatermark(StatusWatermarkValve.java:111) at org.apache.flink.streaming.runtime.io.StreamInputProcessor.processInput(StreamInputProcessor.java:189) at org.apache.flink.streaming.runtime.tasks.OneInputStreamTask.run(OneInputStreamTask.java:69) at org.apache.flink.streaming.runtime.tasks.StreamTask.invoke(StreamTask.java:264) at org.apache.flink.runtime.taskmanager.Task.run(Task.java:718) at java.lang.Thread.run(Thread.java:748) Locked ownable synchronizers: Regards, Shishal On Thu, Jul 12, 2018 at 4:11 PM Stefan Richter <[hidden email]> wrote:
|
Re: Flink job hangs using rocksDb as backend
|
|
Hi,
let me first clarify what you mean by „stuck“, just because your job stops consuming events for some time does not necessarily mean that it is „stuck“. That is very hard to evaluate from the information we have so far, because from the stack trace you cannot conclude that the thread is „stuck“, because it looks like it is just processing firing timers. And while timers are firing, the pipeline will stop consuming further events until all timers have been processed. Even if your thread dump looks the same all the time, it could just be that you observe the same call (the most expensive one) across multiple invocations and is not necessarily an indicator for the thread being stuck. Attaching a sampler or introducing logging to one of the seemingly stuck task JVMs could clarify this a bit more. For now I am assuming that it makes progress but spends a lot of work on timers. Why you might experience this randomly is, for example, if your watermark makes a bigger jump and many (or all) of your timers suddenly fire. From the perspective of consuming events, this could look like being stuck. In case that the job really is stuck in the strict sense, it does not look like a Flink problem because your threads are in some call against RocksDB. Since we are not aware of any similar problem from the mailing list, a setup problem would be the most likely explanation, e.g. what types of disk are you using, how many threads are available on the TM machine so that also RocksDB compaction, processing, async checkpointing etc. can work in parallel. But for now, the most important piece of information would be what exactly „stuck“ means in your problem. Best, Stefan
|
|
|
Thanks Stefan,
You are correct , I learned the hard way that when timers fires it stops processing new events till the time all timers callback completes. This is the points when I decided to isolate the problem by scheduling only 5-6K timers in total so that even if its taking time in timers it should progress after a reasonable period of time. But event after I left it running whole night, watermark didn't progressed at all and cpu still shows 100% usages without any error log(either JM of TM). The stack trace I shared in the one I took in the morning. Also to isolate any problem with elastic sink, I removed sink and just did stream.print() at the end. I am using spinning disk and set following option setPredefinedOptions(PredefinedOptions.SPINNING_DISK_OPTIMIZED); // Also tried SPINNING_DISK_OPTIMIZED_HIGH_MEM My cluster setup has 3 node (Its a private cloud machine and has 4 cpu core each) and 1 TM with 4 slot each running on each node. Also Job manager and hadoop is also running on same 3 node. My job graph look like this: 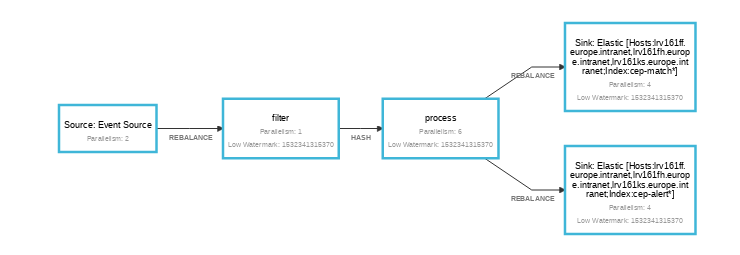 RocksDBStateBackend backend = new RocksDBStateBackend(baseDir+"/checkpoints", true); backend.setPredefinedOptions(PredefinedOptions.SPINNING_DISK_OPTIMIZED); env.setStateBackend(backend); env.enableCheckpointing(intervalMilli); env.getCheckpointConfig().setMinPauseBetweenCheckpoints(intervalMilli); env.getCheckpointConfig().setCheckpointTimeout(timeoutMilli); env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE); env.getCheckpointConfig().enableExternalizedCheckpoints( CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION); env.getCheckpointConfig().setMaxConcurrentCheckpoints(1); The last thing I am intended to try is using FSSatebackend to be sure if its rocksDB related issue, but the problem is sometimes issue get reproduced after couple of days. Regards, Shishal On Mon, Jul 23, 2018 at 10:08 AM Stefan Richter <[hidden email]> wrote:
|
Re: Flink job hangs using rocksDb as backend
|
|
Hi,
yes, timers cannot easily fire in parallel to event processing for correctness reasons because they both manipulate the state and there should be a distinct order of operations. If it is literally stuck, then it is obviously a problem. From the stack trace it looks pretty clear that the culprit would be RocksDB, if that is where it blocks. I cannot remember any report of a similar problem so far, and we are running this version of RocksDB for quiet some time with many users. At the same time I feel like many people are using SSDs for local storage these days. You could run the JVM with a tool that allows you to also get the native traces and system calls to see where RocksDB is potentially stuck. Something we could eventually try is updating the RocksDB version, but that is currently still blocked by a performance regression in newer RocksDB versions, see https://github.com/facebook/rocksdb/issues/3865. Best, Stefan
|
«
Return to (DEPRECATED) Apache Flink User Mailing List archive.
|
1 view|%1 views
| Free forum by Nabble | Edit this page |