Flink checkpoint recovery time


|
Hi all,
I am working on measuring the failure recovery time of Flink and I want to decompose the recovery time into different parts, say the time to detect the failure, the time to restart the job, and the time to restore the checkpointing. I found that I can measure the down time during failure and the time to restart the job and some metric for the checkpointing as below.  Unfortunately, I cannot find any information about the failure detect time and checkpoint recovery time, Is there any way that Flink has provided for this, otherwise, how can I solve this? Thanks a lot for your help. Regards, |
|
|
Hi Zhinan,
For the time to detect the failure, you could refer to the time when 'fullRestarts' increase. That could give you information about the time of job failure.
For the checkpoint recovery time, there actually exist two parts:
Best
Yun Tang
From: Zhinan Cheng <[hidden email]>
Sent: Tuesday, August 18, 2020 11:50 To: [hidden email] <[hidden email]> Subject: Flink checkpoint recovery time Hi all,
I am working on measuring the failure recovery time of Flink and I want to decompose the recovery time into different parts, say the time to detect the failure, the time to restart the job, and the time to restore the checkpointing. I found that I can measure the down time during failure and the time to restart the job and some metric for the checkpointing as below. 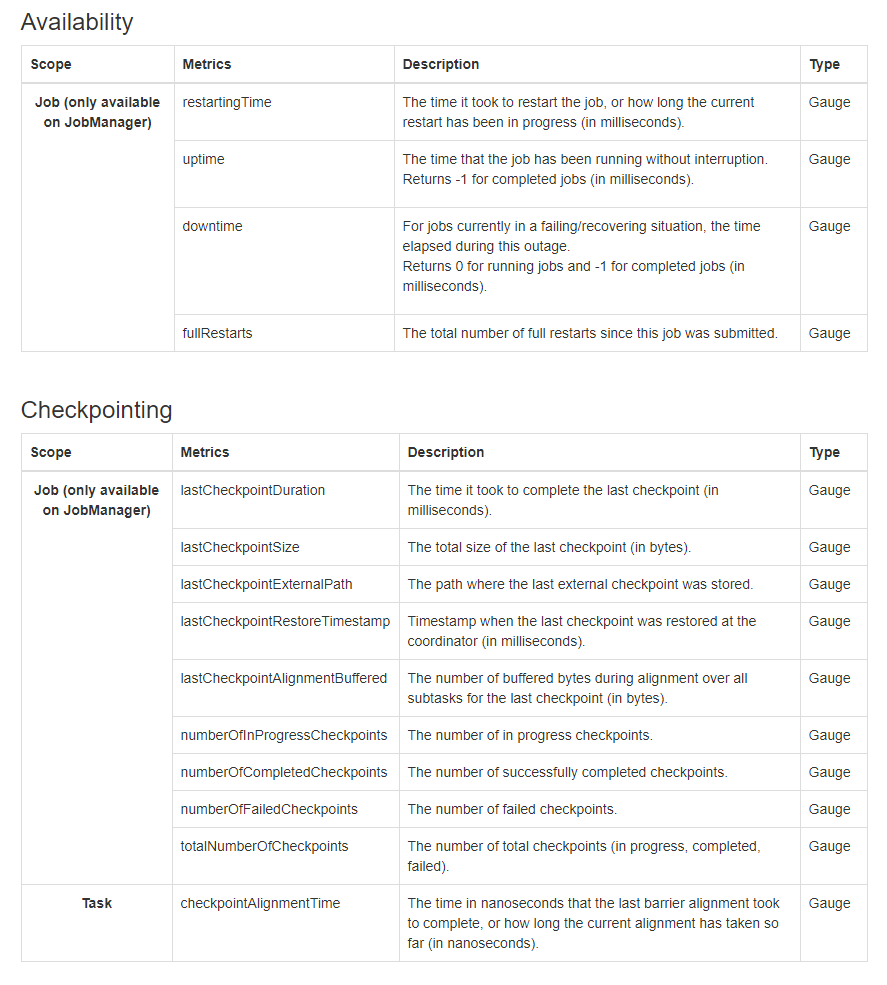 Unfortunately, I cannot find any information about the failure detect time and checkpoint recovery time, Is there any way that Flink has provided for this, otherwise, how can I solve this?
Thanks a lot for your help.
Regards,
|
Re: Flink checkpoint recovery time
|
|
Hi Yun, Thanks a lot for your help. Seems hard to measure the checkpointing restore time currently. I do monitor the "fullRestarts" metric and others like "uptime" and "downtime" to observe some information about failure recovery. Still some confusions: i) I found the time for the jobmanager to make the job from status CANCELING to status CANCELED up to 30s? Is there any reason why it takes so long? Can I reduce this time? ii) Currently the way to calculate the "downtime" is not consistent with the description in the doc, now the downtime is actually the current timestamp minus the time timestamp when the job started. But I think the doc obviously only want to measure the current timestamp minus the timestamp when the job failed. I think I need to measure these times by adding specified metrics myself. Regards, Zhinan On Wed, 19 Aug 2020 at 01:45, Yun Tang <[hidden email]> wrote:
|
Re: Flink checkpoint recovery time
|
|
Hi Zhinan, for i) the cancellation depends on the user code. If the user code does a blocking operation, Flink needs to wait until it returns from there before it can move the Task's state to CANCELED. for ii) I think your observation is correct. Could you please open a JIRA issue for this problem so that it can be fixed in Flink? Thanks a lot! For the time to restore the checkpoints it could also be interesting to add a proper metric to Flink. Hence, you could also create a JIRA issue for it. Cheers, Till On Wed, Aug 19, 2020 at 8:43 AM Zhinan Cheng <[hidden email]> wrote:
|
Re: Flink checkpoint recovery time
|
|
Hi Till, Thanks for the quick response. > for i) the cancellation depends on the user code. If the user code does a blocking operation, Flink needs to wait until it returns from there before it can move the Task's state to CANCELED. for this, my code just includes a map operation and then aggregates the results into a tumbling window. So I think in this case the time is not attributed to the code. I looked into the log, during the period, I observed that the jobmanager continues warning that its connection to the failed taskmanager is confused. I am not sure if this is the reason that delays the canceling, do you have any ideas about this? I am also looking the deadthwatch mechanism [1] of Akka to see if this is the reason. For (ii), I will open the JIRA issue for your mention. Thanks. Regards. Zhinan On Wed, 19 Aug 2020 at 15:39, Till Rohrmann <[hidden email]> wrote:
|
Re: Flink checkpoint recovery time
|
|
Could you share the logs with us? This might help to explain why the cancellation takes so long. Flink is no longer using Akka's death watch mechanism. Cheers, Till On Wed, Aug 19, 2020 at 10:01 AM Zhinan Cheng <[hidden email]> wrote:
|
Re: Flink checkpoint recovery time
|
|
Hi Till, Sorry for the late reply. Attached is the log of jobmanager. I notice that during canceling the job, the jobmanager also warns that the connections to the failed taskmanager is lost. And this lasts for about 30s, and then the jobmanager successfully cancels the operator instances that related to the failed taskmanager and restarts the job. Does there anyway help reduce the restart time? Thanks a lot. Regards, Zhinan On Wed, 19 Aug 2020 at 16:37, Till Rohrmann <[hidden email]> wrote:
|
Re: Flink checkpoint recovery time
|
|
Hi Zhinan, the logs show that the cancellation does not take 30s. What happens is that the job gets restarted a couple of times. The problem seems to be that one TaskManager died permanently but it takes the heartbeat timeout (default 50s) until it is detected as dead. In the meantime the system tries to redeploy tasks which will cause the job to fail again and again. Cheers, Till On Thu, Aug 20, 2020 at 4:41 PM Zhinan Cheng <[hidden email]> wrote:
|
Re: Flink checkpoint recovery time
|
|
Hi Till, Thanks for the quick reply. Yes, the job actually restarts twice, the metric fullRestarts also indicates this, its value is 2. But the job indeed takes around 30s to switch from CANCELLING to RESTARTING in its first restart. I just wonder why it takes so long here? Also, even I set the heartbeat timeout from default 50s to 5s, this time is similar, so I think this is nothing about the heartbeat timeout. Regards, Zhinan On Fri, 21 Aug 2020 at 00:02, Till Rohrmann <[hidden email]> wrote:
|
Re: Flink checkpoint recovery time
|
|
You are right. The problem is that Flink tries three times to cancel the call and every RPC call has a timeout of 10s. Since the machine on which the Task ran has died, it will take that long until the system decides to fail the Task instead [1]. On Thu, Aug 20, 2020 at 6:17 PM Zhinan Cheng <[hidden email]> wrote:
|
Re: Flink checkpoint recovery time
|
|
Hi Till, Thanks for the reply. Is the timeout 10s here always necessary? Can I reduce this value to reduce the restart time of the job? I cannot find this term in the configuration of Flink currently. Regards, Zhinan On Fri, 21 Aug 2020 at 15:28, Till Rohrmann <[hidden email]> wrote:
|
Re: Flink checkpoint recovery time
|
|
It should be the akka.ask.timeout which is defining the rpc timeout. You can decrease it, but it might cause other RPCs to fail if you set it too low. Cheers, Till On Fri, Aug 21, 2020 at 9:45 AM Zhinan Cheng <[hidden email]> wrote:
|
«
Return to (DEPRECATED) Apache Flink User Mailing List archive.
|
1 view|%1 views
| Free forum by Nabble | Edit this page |