Great that you could fix it. Thanks for letting us know.
> Thanks, Timo and Piotr!
>
> I figured out my issue. I called env.disableOperatorChaining(); in my
> developer mode. Disabling operator chaining created the redundant joins.
>
>
>
> On Mon, Sep 28, 2020 at 6:41 AM Timo Walther <
[hidden email]
> <mailto:
[hidden email]>> wrote:
>
> Hi Dan,
>
> unfortunetely, it is very difficult to read you plan? Maybe you can
> share a higher resolution and highlight which part of the pipeline
> is A,
> B etc. In general, the planner should be smart enough to reuse subplans
> where appropriate. Maybe this is a bug or shortcoming in the optimizer
> rules that we can fix.
>
> Piotr's suggestion would work to "materialize" a part of the plan to
> DataStream API such that this part is a black box for the optimizer and
> read only once. Currently, there is no API for performing this in the
> Table API itself.
>
> Regards,
> Timo
>
> On 28.09.20 15:13, Piotr Nowojski wrote:
> > Hi Dan,
> >
> > Are we talking about Streaming SQL (from the presence of
> IntervalJoin
> > node I presume so)? Are you using blink planner?
> >
> > I'm not super familiar with the Flink SQL, but my best guess
> would be
> > that if you would "export" the view "A" as a DataStream, then
> > re-register it as a new table "A2" and use "A2" in your query, it
> could
> > do the trick. [1]
> > But I might be wrong or there might be a better way to do it (maybe
> > someone else can help here?).
> >
> > Piotrek
> >
> > [1]
> >
>
https://ci.apache.org/projects/flink/flink-docs-stable/dev/table/common.html#integration-with-datastream-and-dataset-api> >
> > sob., 26 wrz 2020 o 00:02 Dan Hill <
[hidden email]
> <mailto:
[hidden email]>
> > <mailto:
[hidden email] <mailto:
[hidden email]>>>
> napisał(a):
> >
> > I have a temporary views, A and B, and I want to output a
> union like
> > the following:
> > SELECT * FROM ((SELECT ... FROM A) UNION ALL (SELECT ... FROM
> B JOIN
> > A ...))
> >
> > Since the columns being requested in both parts of the union are
> > different, the planner appears to be separating these out. A is
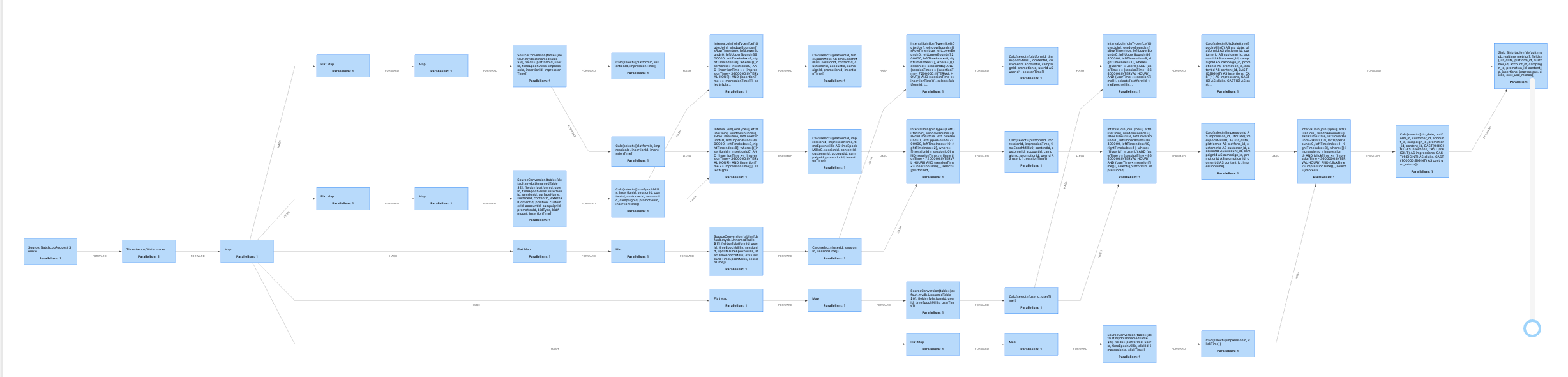
> > pretty complex so I want to reuse A. Here's the graph for A. A
> > bunch of extra join nodes are introduced.
> >
> > Just A.
> > Screen Shot 2020-09-22 at 11.14.07 PM.png
> >
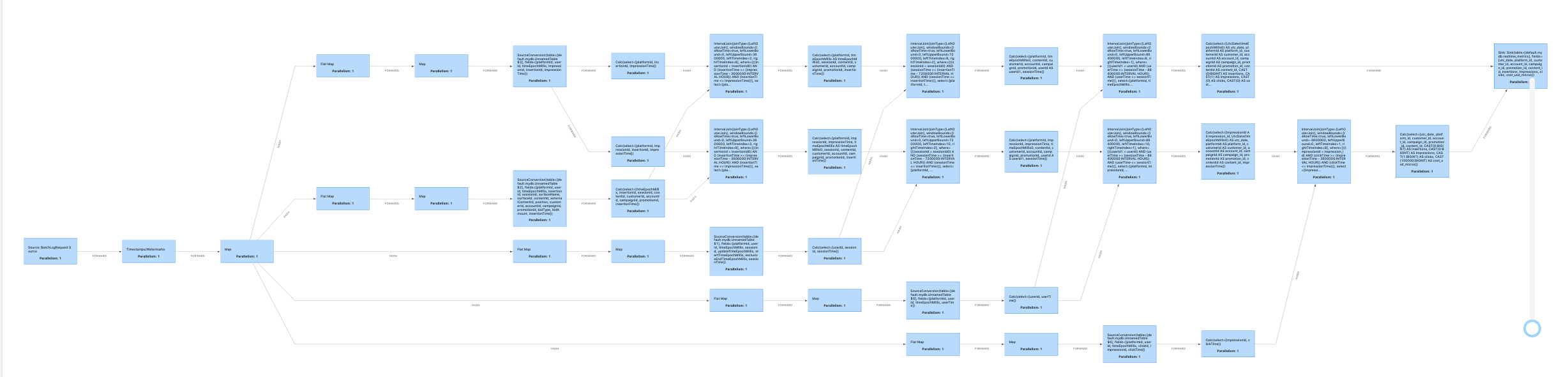
> > How the planner currently handles the union. It creates a
> bunch of
> > inefficient extra join nodes since the columns are slightly
> different.
> > Screen Shot 2020-09-23 at 12.24.59 PM.png
> >
>