|
|
Hi Becket, do you have any thoughts on this issue? Please let me know if you'd like any more details.
Thank you!
- Zach From the top of my head I cannot think of anything concrete you want to look for in the logs. I am pulling in Becket who has a bit more experience with Kafka and Flink's connector. Maybe he has an idea what could cause the problem.
One idea you could try out is whether this problem also occurs with a newer Flink version. Not sure whether this is possible for you.
Cheers, Till
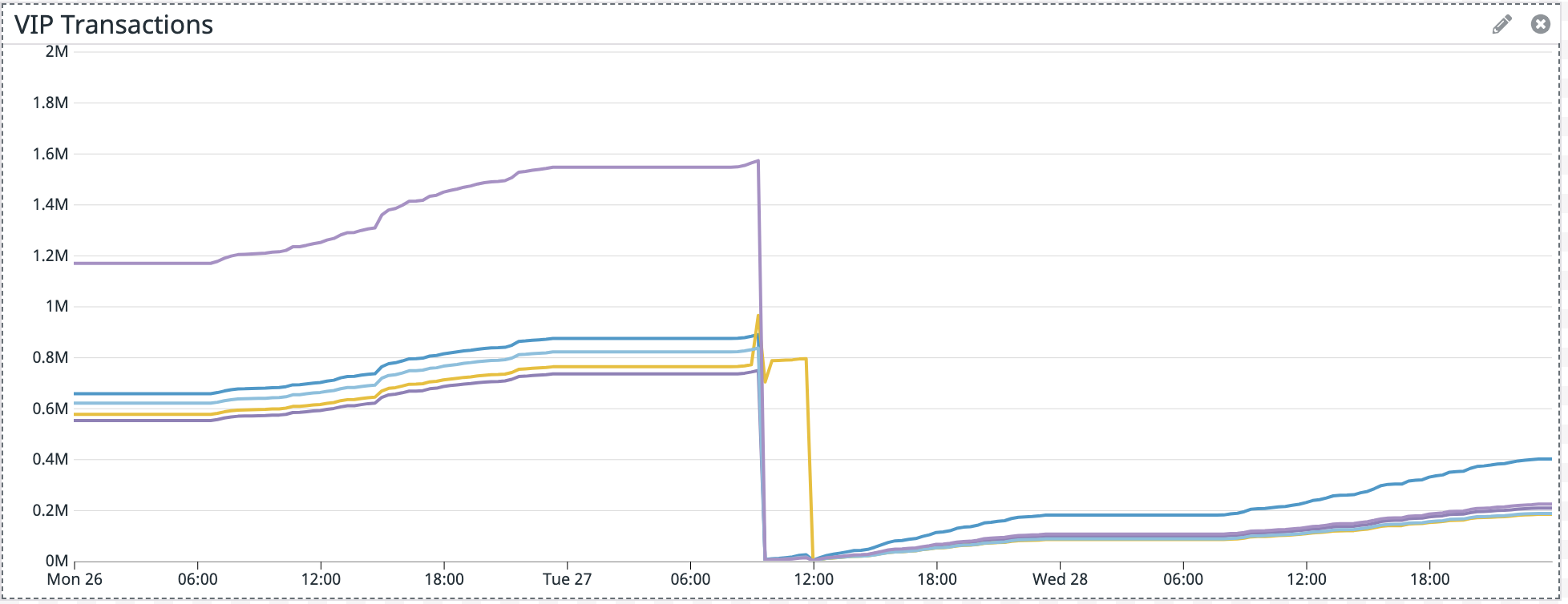
On Thu, Apr 29, 2021 at 11:29 PM Zachary Manno < [hidden email]> wrote: Also forgot to say, the yellow line steeply dropped off at 12 (was closer to 11) because we deployed the job again at that time to try to stop the bleeding. At 11/12 we took another savepoint, cancelled the job, and brought it back up from that savepoint. It is all good from that point as well.
Thanks, Zach
The graph monitors this metric in the flink dashboard:
So it is just the count of Kafka messages consumed, per instance. The sum of all 5 instances equals the "Records sent" metric on the Flink UI for that Kafka consumer. When a new job is deployed everything starts off as 0 again so that is why the sharp drops, then it increases as more messages are consumed. If no messages are being consumed it will flatline and hold its last value. What I've never seen before is that sharp rise in messages consumed, for only one instance, right when the job was deployed. I know we're working in the dark here without logs but do you have any keywords I could search? Or can think of any similar issues resuming a job manually from a checkpoint? Or anything configuration-wise we should look at?
Going forward before we tear down instances we are going to manually take a savepoint first. There is probably a lot of randomness in just terminating the EMR while the job is running and relying on the last checkpoint to resume. However, I am still uneasy on if this could happen with savepointing as well.
Thank you for your responses I really appreciate it!
On Thu, Apr 29, 2021 at 12:57 PM Till Rohrmann < [hidden email]> wrote: Not sure whether I can interpret the graph properly without seeing the logs of Flink. If the graph shows the "numRecordsOut", then it looks as if the yellow KafkaConsumer gets restarted a bit later. I assume that VIP transactions is a strictly monotonously increasing value, right? Then it is odd that you have a short spike upwards, then downwards and then it keeps on the same level until it drops to 0. It would be good to understand what is happening there.
Cheers, Till
Hi Till thanks for the response.
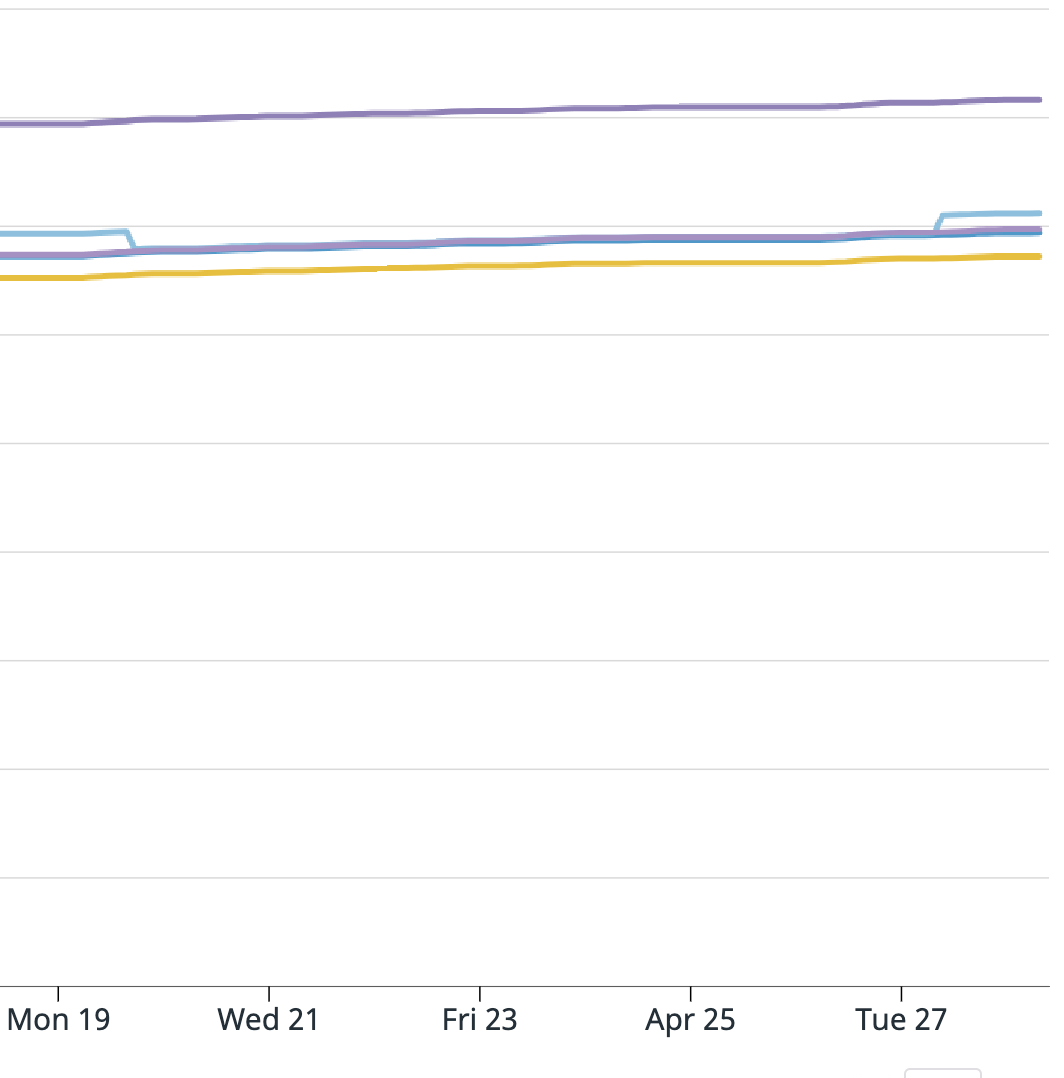
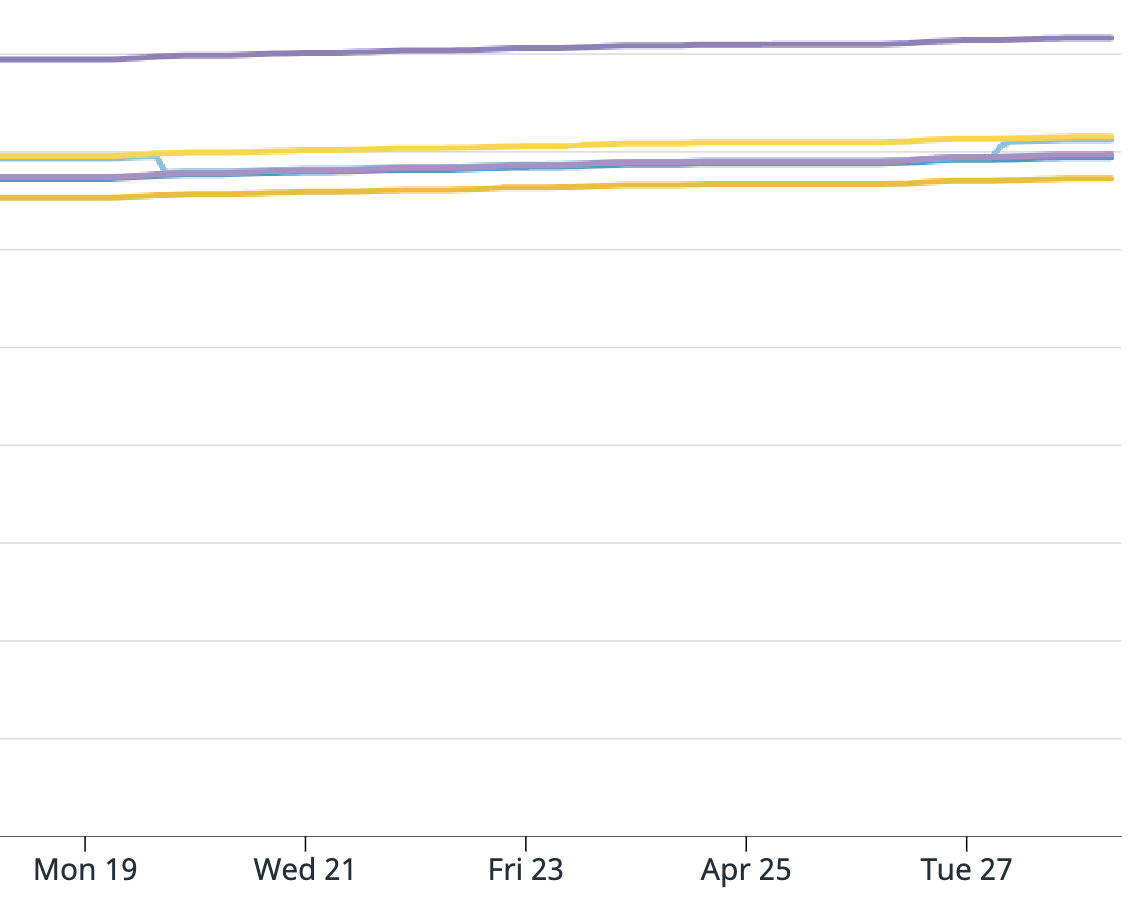
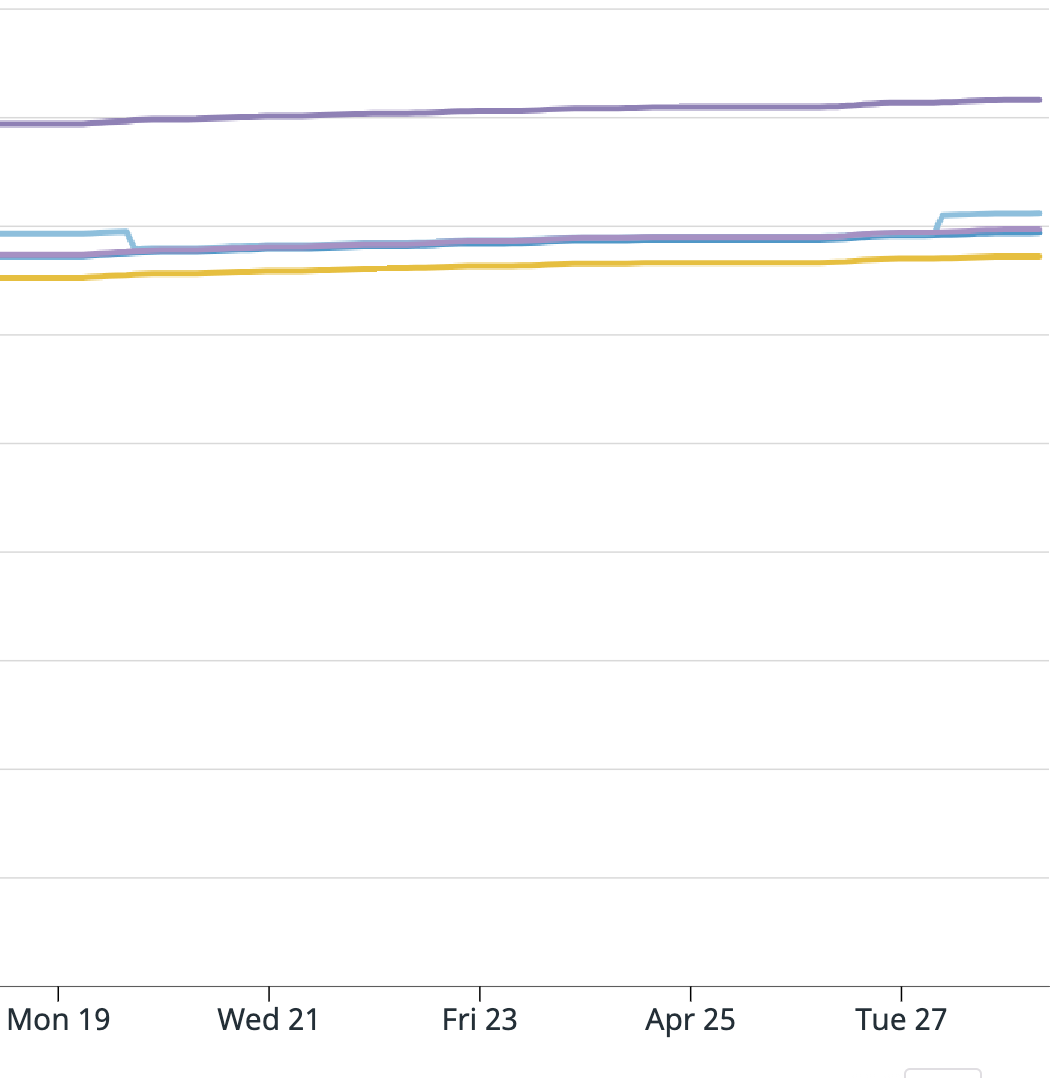
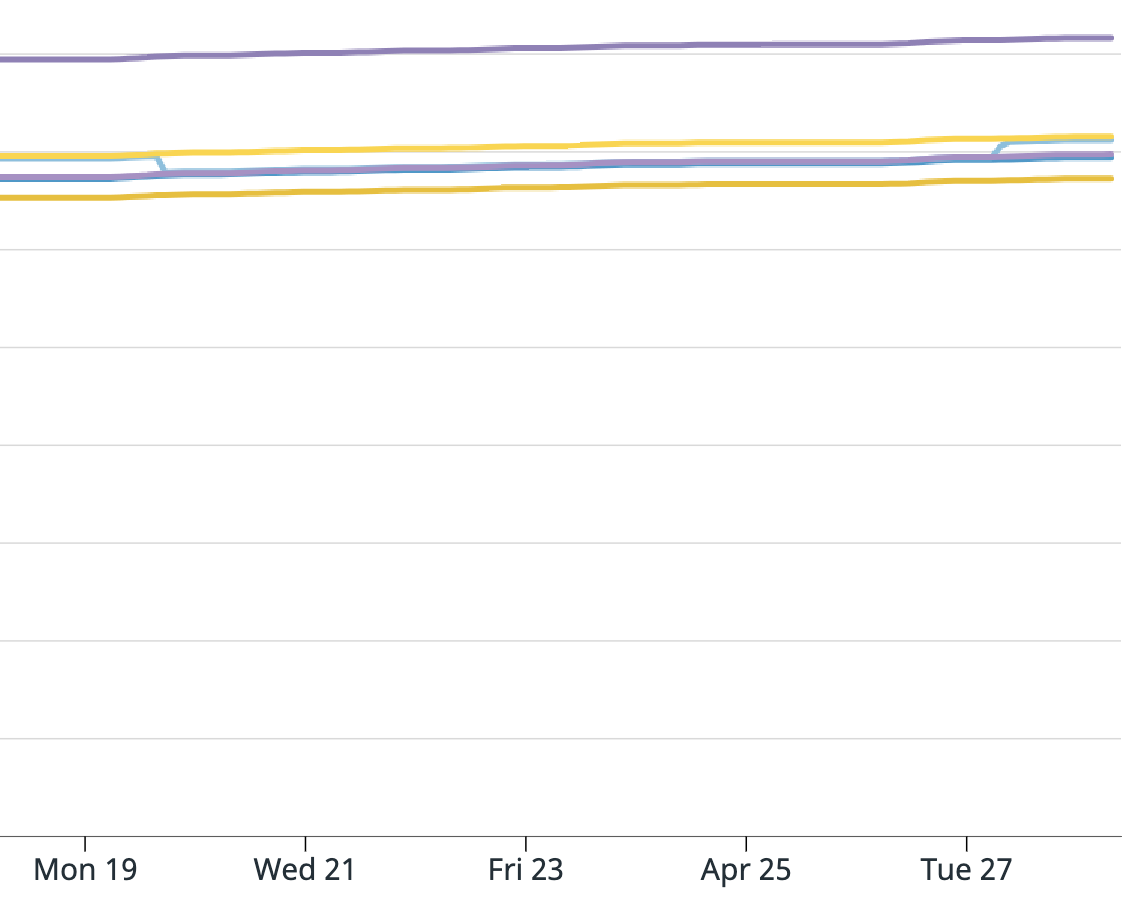
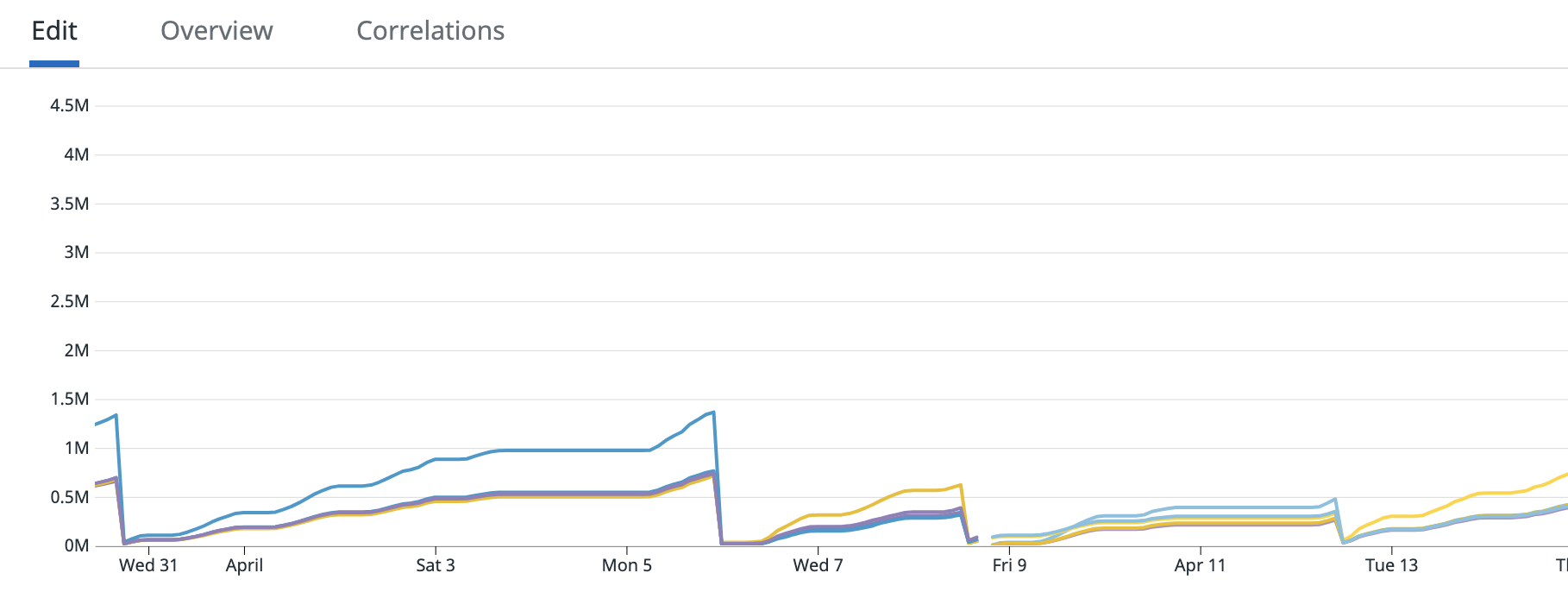
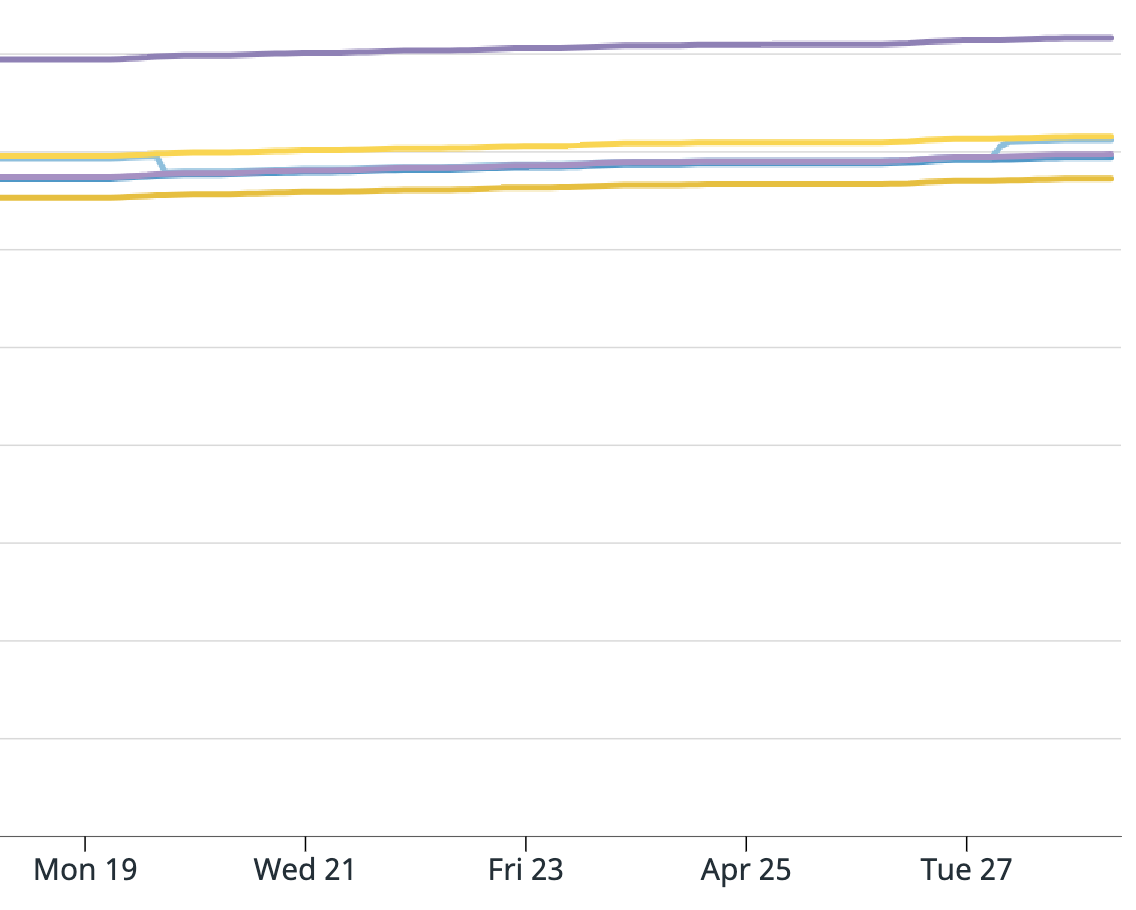
For your summary, it is all correct except it wasn't every message from the 19th to the 27th, it was only a portion of messages. Also from the 19th to the 27th the application was behaving as expected. I attached a graph of messages consumed from the Kafka source operator "numRecordsOut". For this topic there are 6 partitions, for our job we have parallelism of 5, and 5 EC2 instances. All instances look fine except the yellow one which shoots up unexpectedly, and this is where the extra messages came from.
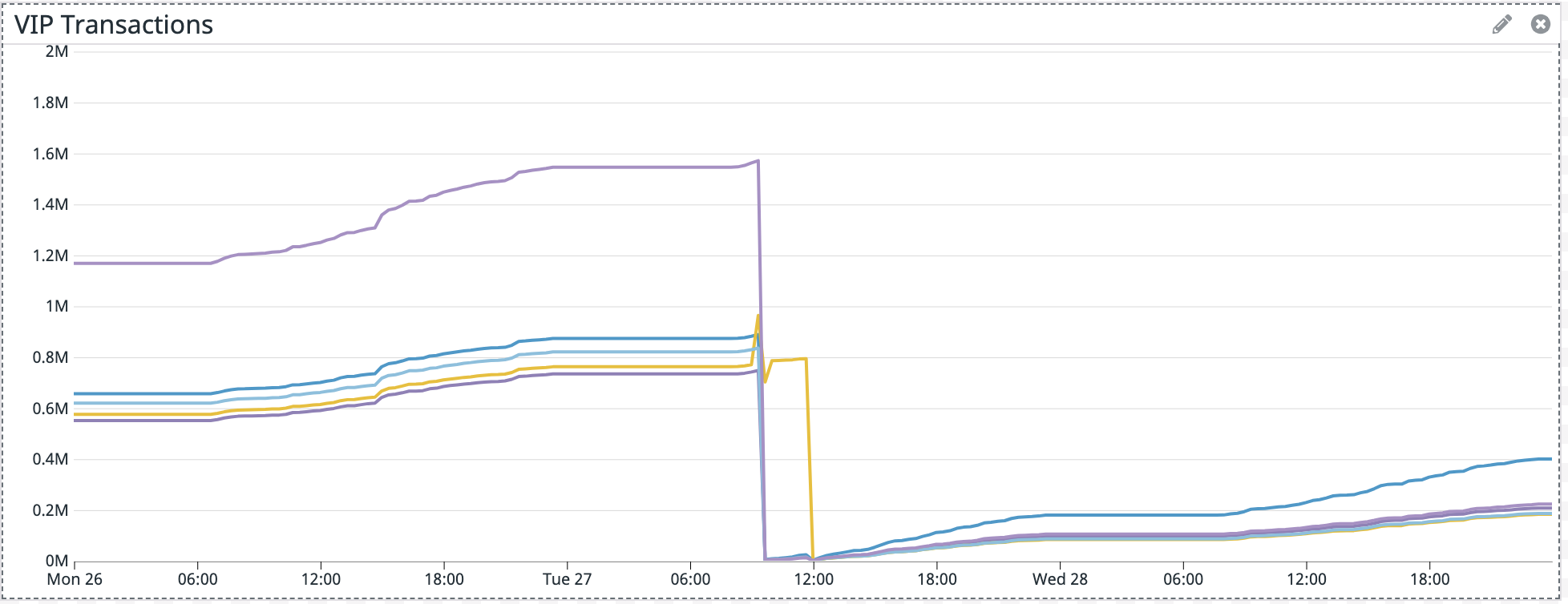
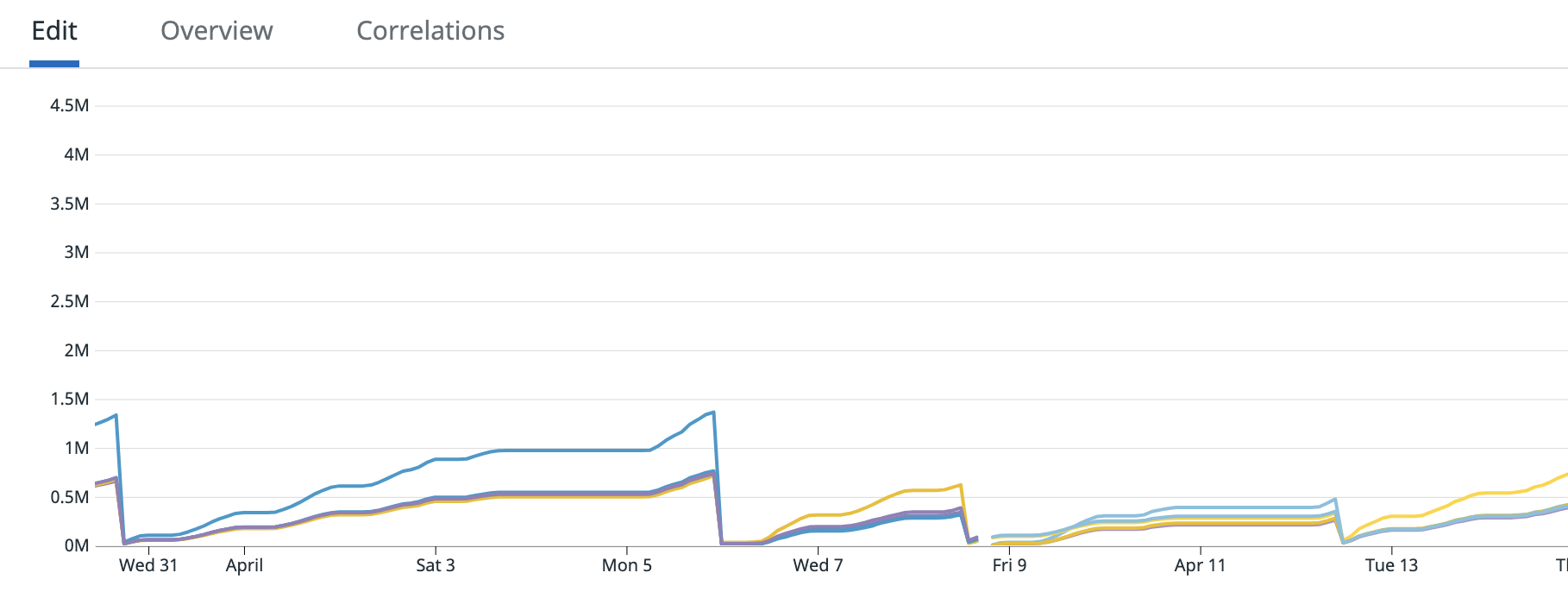
Attaching another graph from March 31 - April 14 which shows a few different deployments, no weird spike like the April 27 graph.
Hi Zachary,
How did you configure the Kafka connector to commit the offsets (periodically, on checkpoint)? One explanation for the graphs you showed is that you enabled periodic committing of the offsets. If this automatic commit happens between two checkpoints and you later fall back to the earlier checkpoint, it should be possible that you see with the next periodic committing of the offsets that it dropped. Note, that Flink does not rely on the offset committed to the Kafka broker for fault tolerance. It stores the actual offset in its internal state.
In order to better understand the scenario let me try to summarize it. Periodically you restart your infrastructure and then resume the Flink job from the latest checkpoint. You did this on the 19th of April. Then on the 27th of April you created a savepoint from the job you restarted on the 19th but was running fine since then. And then you submitted a new job resuming from this savepoint. And all of a sudden, this new job started to consume data from Kafka starting from the 19th of April. Is this correct? If this happened like described, then the Flink job seems to not have made a lot of progress since you restarted it. Without the logs it is really hard to tell what could be the cause.
Cheers, Till
Hello, I am running Flink version 1.10 on Amazon EMR. We use RocksDB/S3 for state. I have "Persist Checkpoints Externally" enabled. Periodically I must tear down the current infrastructure and bring it back up. To do this, I terminate the EMR, bring up a fresh EMR cluster, and then I resume the Flink job from the latest checkpoint path in S3 using the "-s" method here:
I last did this operation on April 19. Then, on April 27 I deployed a new version of the code only, using savepointing. This caused a production incident because it turned out that on April 19th one of the Kafka partition offsets was not committed currently somehow during the resuming from checkpoint. When the new code was deployed on the 27th a backfill of Kafka messages came in from the 19th to the 27th which caused the issue.
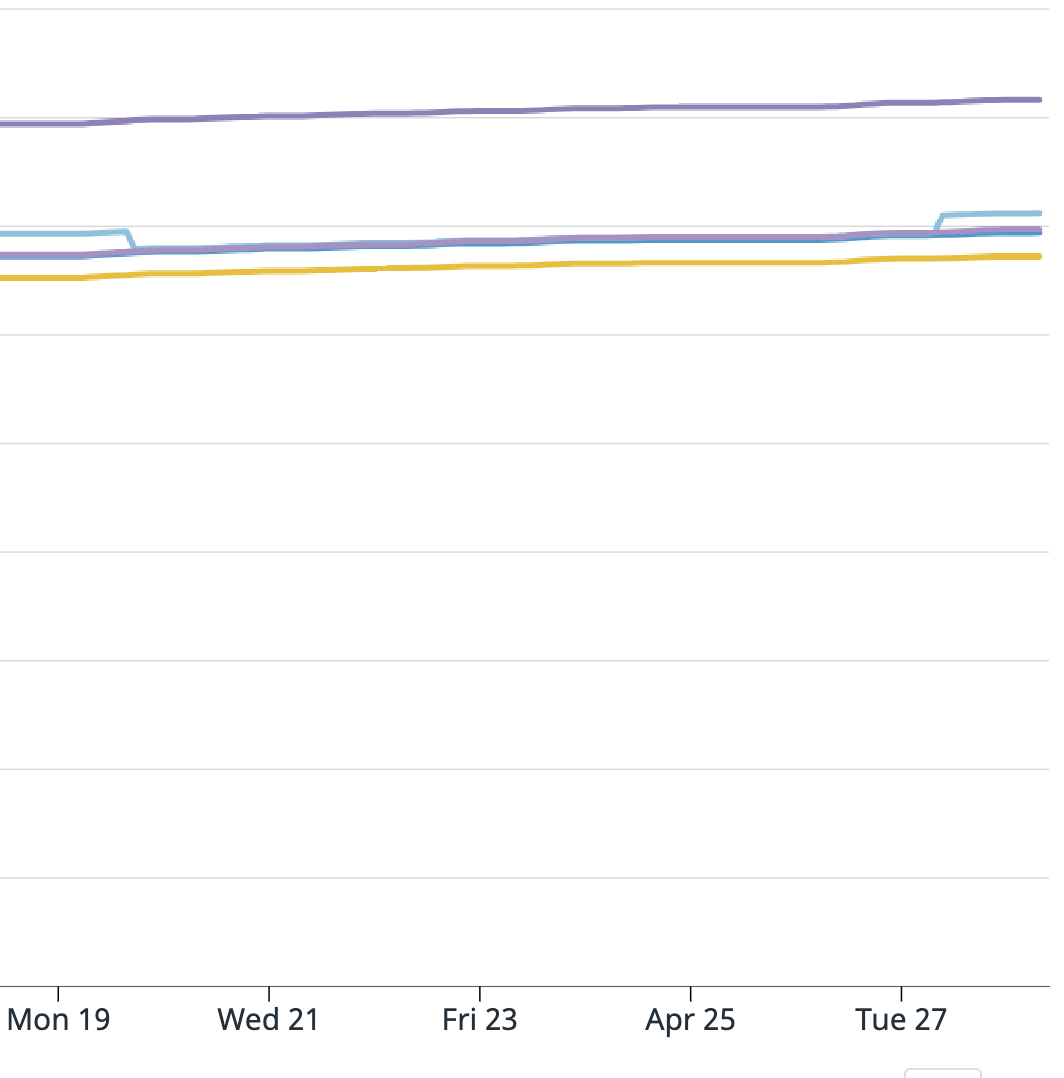
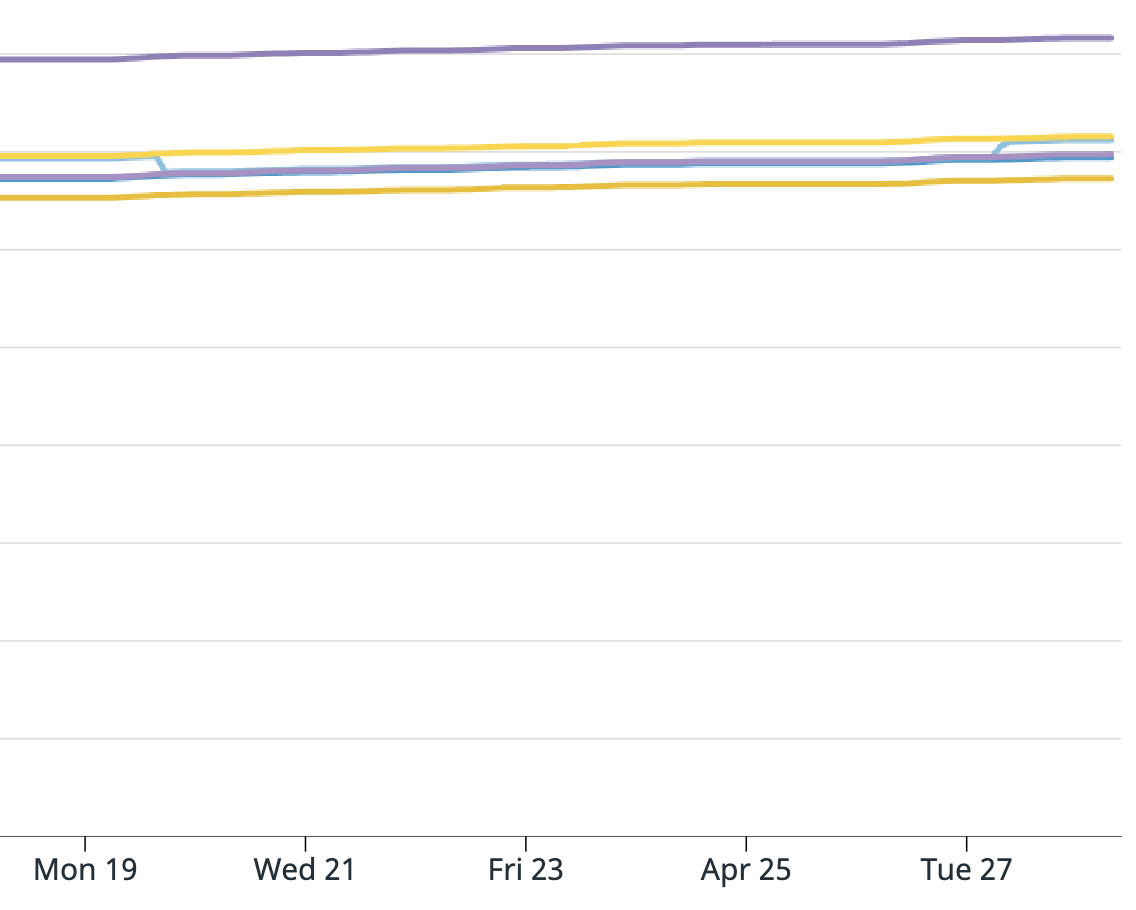
I am attaching screenshots of Datadog metrics for the Kafka consumer metrics Flink provides. One graph is:
".KafkaConsumer.topic.{topic_name}.partition.{partition_number}.committedOffsets"
And the next is: "KafkaConsumer.topic.{topic_name}.partition.{partition_number}.currentOffsets"
The light blue line is partition 3 and that is the one that caused the issue. Does anyone have any insight into what could have happened? And what I can do to prevent this in the future? Unfortunately since the EMR was terminated I cannot provide the full logs. I am able to search for keywords or get sections since we have external Splunk logging but cannot get full files.
Thanks for any help!! 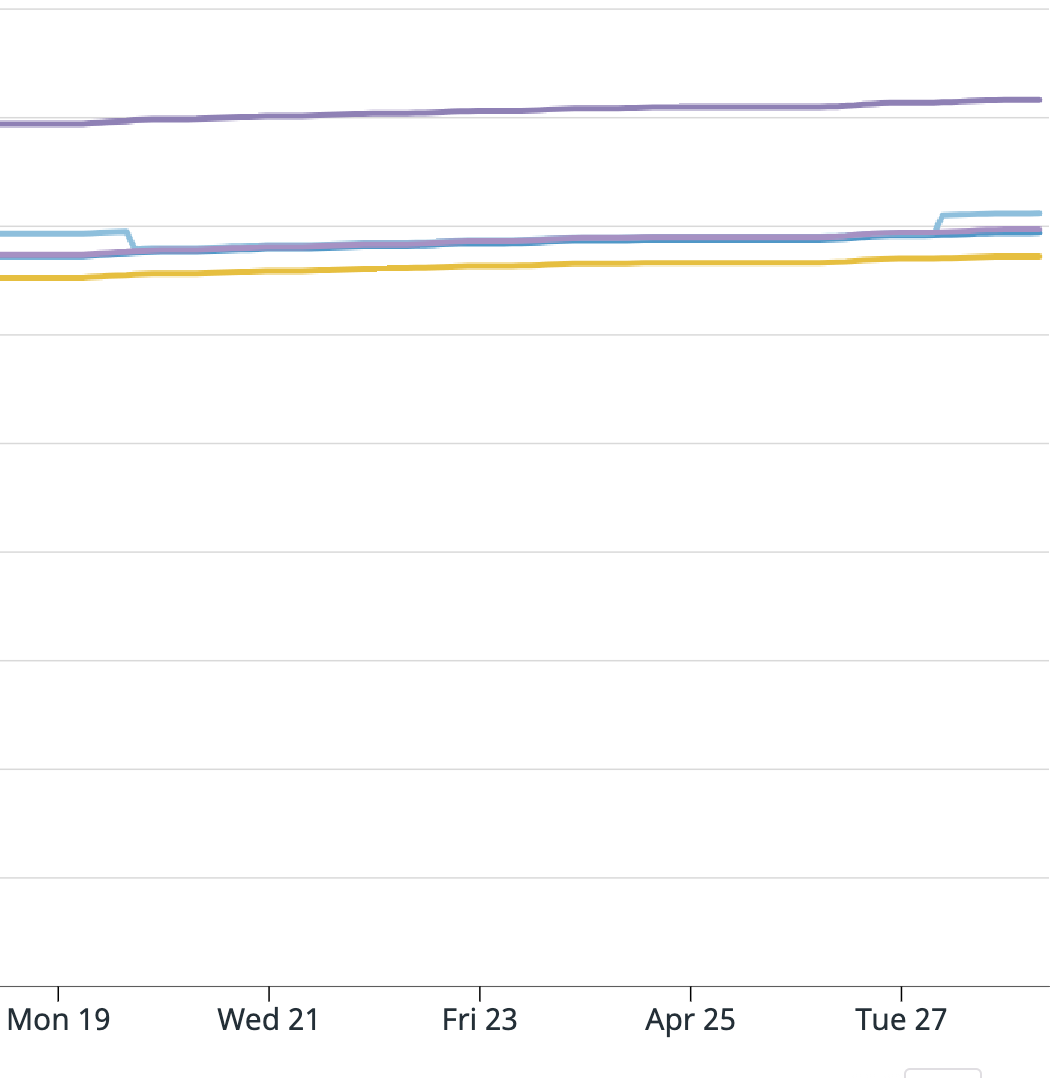
The information contained in this e-mail is confidential and/or proprietary to Capital One and/or its affiliates and may only be used solely in performance of work or services for Capital One. The information transmitted herewith is intended only for use by the individual or entity to which it is addressed. If the reader of this message is not the intended recipient, you are hereby notified that any review, retransmission, dissemination, distribution, copying or other use of, or taking of any action in reliance upon this information is strictly prohibited. If you have received this communication in error, please contact the sender and delete the material from your computer.
--
Zach Manno Data Engineer Small Business Bank
The information contained in this e-mail is confidential and/or proprietary to Capital One and/or its affiliates and may only be used solely in performance of work or services for Capital One. The information transmitted herewith is intended only for use by the individual or entity to which it is addressed. If the reader of this message is not the intended recipient, you are hereby notified that any review, retransmission, dissemination, distribution, copying or other use of, or taking of any action in reliance upon this information is strictly prohibited. If you have received this communication in error, please contact the sender and delete the material from your computer.
--
Zach Manno Data Engineer Small Business Bank
--
Zach Manno Data Engineer Small Business Bank
The information contained in this e-mail is confidential and/or proprietary to Capital One and/or its affiliates and may only be used solely in performance of work or services for Capital One. The information transmitted herewith is intended only for use by the individual or entity to which it is addressed. If the reader of this message is not the intended recipient, you are hereby notified that any review, retransmission, dissemination, distribution, copying or other use of, or taking of any action in reliance upon this information is strictly prohibited. If you have received this communication in error, please contact the sender and delete the material from your computer.
-- Zach Manno Data Engineer Small Business Bank
The information contained in this e-mail is confidential and/or proprietary to Capital One and/or its affiliates and may only be used solely in performance of work or services for Capital One. The information transmitted herewith is intended only for use by the individual or entity to which it is addressed. If the reader of this message is not the intended recipient, you are hereby notified that any review, retransmission, dissemination, distribution, copying or other use of, or taking of any action in reliance upon this information is strictly prohibited. If you have received this communication in error, please contact the sender and delete the material from your computer.
|
|