Flink, Kappa and Lambda


|
Hi All,
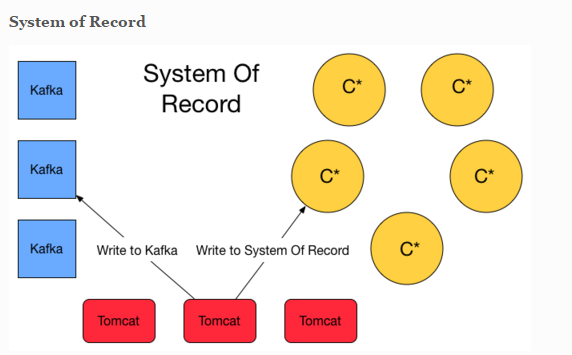
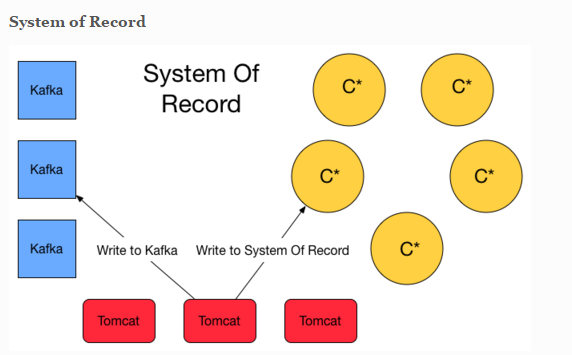
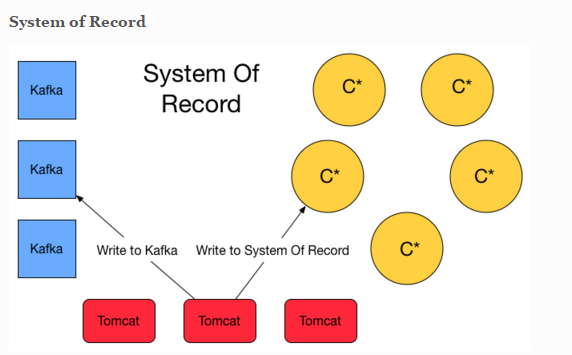
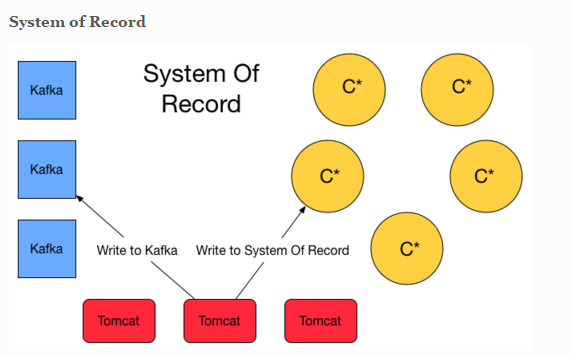
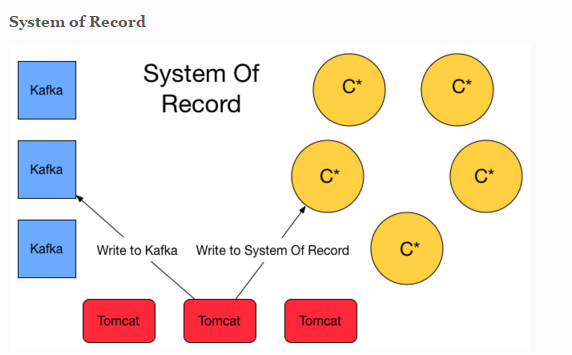
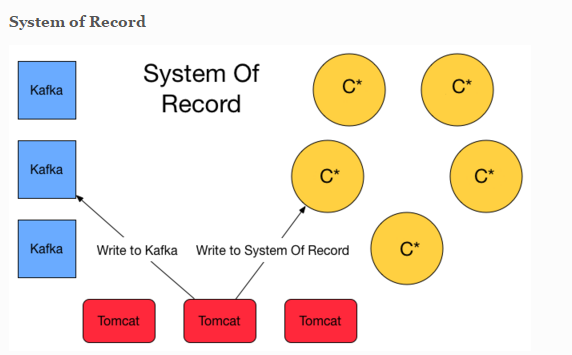
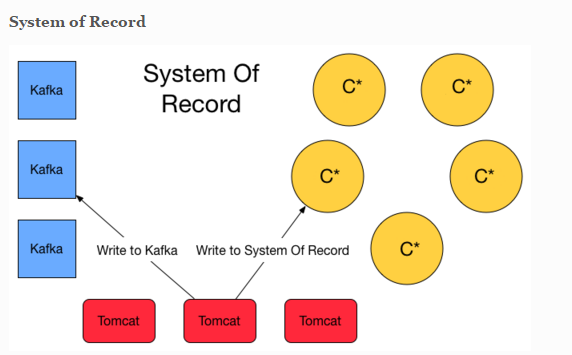
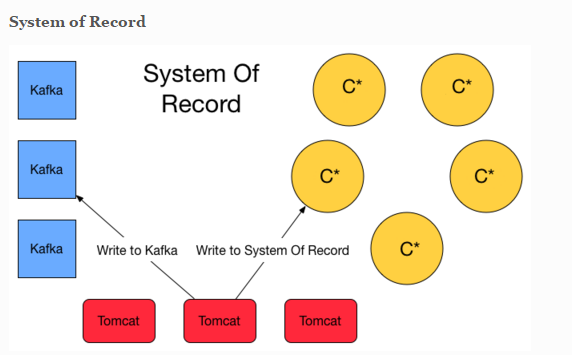
I read a couple of article about Kappa and Lambda Architecture. I'm convince that Flink will simplify this one with streaming. However i also stumble upon this blog post that has valid argument to have a system of record storage ( event sourcing ) and finally lambda architecture is appear at the solution. Basically it will write twice to Queuing system and C* for safety. System of record here is basically storing the event (delta). 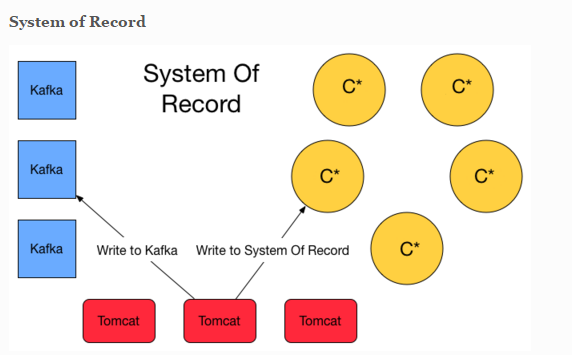 Another approach is about lambda architecture for maintaining the correctness of the system. https://lostechies.com/ryansvihla/2015/09/17/real-time-analytics-with-spark-streaming-and-cassandra/ Given that he's using Spark for the streaming processor, do we have to do the same thing with Apache Flink ? |
|
|
Hi! Can you explain a little more what you want to achieve? Maybe then we can give a few more comments... I briefly read through some of the articles you linked, but did not quite understand their train of thoughts. For example, letting Tomcat write to Cassandra directly, and to Kafka, might just be redundant. Why not let the streaming job that reads the Kafka queue move the data to Cassandra as one of its results? Further more, durable storing the sequence of events is exactly what Kafka does, but the article suggests to use Cassandra for that, which I find very counter intuitive. It looks a bit like the suggested approach is only adopting streaming for half the task. Greetings, Stephan On Tue, Nov 10, 2015 at 7:49 AM, Welly Tambunan <[hidden email]> wrote:
|
|
|
Hi Stephan, Thanks for your response. We are trying to justify whether it's enough to use Kappa Architecture with Flink. This more about resiliency and message lost issue etc. The article is worry about message lost even if you are using Kafka. No matter the message queue or broker you rely on whether it be RabbitMQ, JMS, ActiveMQ, Websphere, MSMQ and yes even Kafka you can lose messages in any of the following ways:
Cheers On Wed, Nov 11, 2015 at 4:13 PM, Stephan Ewen <[hidden email]> wrote:
|
|
|
Hello, regarding the Lambda architecture there is a following book - https://www.manning.com/books/big-data (Big Data. Principles and best practices of scalable realtime data systemsNathan Marz and James Warren). 2015-11-12 4:47 GMT+03:00 Welly Tambunan <[hidden email]>:
|
|
|
In reply to this post by tambunanw
The first and 3rd points here aren't very fair -- they apply to all data systems. Systems downstream of your database can lose data in the same way; the database retention policy expires old data, downstream fails, and back to the tapes you must go. Likewise with 3, a bug in any ETL system can cause problems. Also not specific to streaming in general or Kafka/Flink specifically.
I'm much more curious about the 2nd claim. The whole point of high availability in these systems is to not lose data during failure. The post's author is not specific on any of these points, but just like I look to a distributed database community to prove to me it doesn't lose data in these corner cases, so too do I expect Kafka to prove it is resilient. In the absence of software formally proven correct, I look to empirical evidence in the form of chaos monkey type tests.
On Wednesday, November 11, 2015, Welly Tambunan <[hidden email]> wrote:
|
|
|
In reply to this post by rss rss
Hi rss rss, Yes. I have already read that book. However given the state of streaming right now, and Kappa Architecture, I don't think we need Lambda Architecture again ? Any thoughts ? On Thu, Nov 12, 2015 at 12:29 PM, rss rss <[hidden email]> wrote:
|
|
|
In reply to this post by Nick Dimiduk
Hi Nick, I totally agree with your point. My concern is the Kafka, is the author concern really true ? Any one can give comments on this one ? On Thu, Nov 12, 2015 at 12:33 PM, Nick Dimiduk <[hidden email]> wrote: The first and 3rd points here aren't very fair -- they apply to all data systems. Systems downstream of your database can lose data in the same way; the database retention policy expires old data, downstream fails, and back to the tapes you must go. Likewise with 3, a bug in any ETL system can cause problems. Also not specific to streaming in general or Kafka/Flink specifically. |
|
|
In reply to this post by tambunanw
Hi
Personally, I find the the concepts of the so-called Kappa architecture intriguing. But I doubt that it is applicable in a generic setup where different use cases are mapped into the architecture. To be fair, I think the same applies to Lambda architectures. Therefore I wouldn't assume that Lambda architectures are obsolete with the advent of Kappa as new architectural paradigm. From my point of view, it all depends on the use case that you want to solve. For example, I saw a presentation given by Eric Tschetter and Fangjin Yang of MetaMarkets on how they use Hadoop and Druid to drive their business. They used Hadoop as long-term storage and Druid on the serving layer to provide up-to-date data into the business by updating it in sub-second intervals. Regularly they algin both systems to be consistent. In their case, the Lambda architecture serves their business quite well: speed achieved through the streaming layer and long time persistence through the batch layer. In cases where you - for example - want to create views on customer sessions by aggregating all events belonging to a single person and use them to * serve recommendation systems while the customer is still on your website and * keep them persistent in a long-term archive people tend to build typical Lambda architectures with duplicated sessionizing code on both layers. From my point of view this is unnecessary and introduces an additional source of errors. As customer sessions are created as stream of events, simply implement the logic on your streaming layer and persist the final session after a timeout in those systems where you need the data to be present: eg. recommender system receives constant updates on each new event and the batch layer (Hadoop) receives the finished session after it timed out. As Lambda - in most cases - is implemented to do the same thing on both layers, later merging the results to keep states consistent, the Kappa architecture introduces an interesting pattern that people often are not aware of. The idea to persist the stream itself and get rid of other systems, like RDBMS, NoSQL DBs or any other type of archive software, is often accepted as cheap way to reduce costs and maintenance efforts. But I think Kappa does more and may be expanded to other systems than streaming as well. You keep the data at that system persistent where it arrived or received a state you expect in subsequent systems. Why should I convert a stream of tracking events into a static schema and store the data inside an RDBMS? What if I rely on its nature that data is coming in as stream and do not want to have it exported/imported as bulk update but have the same stream replayed later? What about information loss? Being a stream of events is part of the information as well like the attributes each event carries. So, if Kappa is understood as architectural pattern where data is kept and processed the way it arrived or is expected by subsequent systems, I do not think that it will ever replace Lambda but it will complement it. Therefore I would like to give you the advice to look at your use case(s) and design the architecture as you need it. Do not stick with a certain pattern but deploy those parts that fit with your use-case. This context is far too young that it provides you with additional value strictly following a certain pattern, eg to make it more easier to integrate with third-party software. Best Christian 2015-11-13 9:51 GMT+01:00 Welly Tambunan <[hidden email]>:
|
|
|
Hi Christian, Valid point. Thanks a lot for your great explanation. In our case, we want to avoid lots of moving part. We are working on the greenfield project so we want to adopt the latest approach as we have a flexibility right now. We also asses the Apache Spark before and it doesn't suit our real-time purpose. But we have a really great experience with Apache Flink until now. So that's why we trying to do everything as streaming as that has a HUGE business value for us. And fortunately the technology seems already there on the streaming world. Cheers On Fri, Nov 13, 2015 at 7:21 PM, Christian Kreutzfeldt <[hidden email]> wrote:
|
«
Return to (DEPRECATED) Apache Flink User Mailing List archive.
|
1 view|%1 views
| Free forum by Nabble | Edit this page |