Flink Kafka connector consume from a single kafka partition

Flink Kafka connector consume from a single kafka partition

|
Hello Flink Users,
I have a use case where I am processing metrics from different type of sources(one source will have multiple devices) and for aggregations as well as build alerts order of messages is important. To maintain customer data segregation I plan to have single topic for each customer with each source stream data to one kafka partition. To maintain ordering I am planning to push data for a single source type to single partitions. Then I can create keyedstream so that each of the device-id I have a single stream which has ordered data for each device-id. However, flink-kafka consumer I don't see that I can read from a specific partition hence flink consumer read from multiple kafka partitions. So even if I try to create a keyedstream on source type(and then write to a partition for further processing like keyedstream on device-id) I think ordering will not be maintained per source type. Only other option I feel I am left with is have single partition for the topic so that flink can subscribe to the topic and this maintains the ordering, the challenge is too many topics(as I have this configuration for multiple customers) which is not advisable for a kafka cluster. Can anyone shed some light on how to handle this use case. Thanks, Hemant |
Re: Flink Kafka connector consume from a single kafka partition
|
|
Hi Hemant, Flink passes your configurations to the Kafka consumer, so you could check if you can subscribe to only one partition there. However, I would discourage that approach. I don't see the benefit to just subscribing to the topic entirely and have dedicated processing for the different devices. If you are concerned about the order, you shouldn't. Since all events of a specific device-id reside in the same source partition, events are in-order in Kafka (responsibility of producer, but I'm assuming that because of your mail) and thus they are also in order in non-keyed streams in Flink. Any keyBy on device-id or composite key involving device-id, would also retain the order. If you have exactly one partition per device-id, you could even go with `DataStreamUtil#reinterpretAsKeyedStream` to avoid any shuffling. Let me know if I misunderstood your use case or if you have further questions. Best, Arvid On Wed, Feb 19, 2020 at 8:39 AM hemant singh <[hidden email]> wrote:
|
Re: Flink Kafka connector consume from a single kafka partition
|
|
Hi Arvid, Thanks for your response. I think I did not word my question properly. I wanted to confirm that if the data is distributed to more than one partition then the ordering cannot be maintained (which is documented). According to your response I understand if I set the parallelism to number of partition then each consumer will consume from one partition and ordering can be maintained. However, I have a question here in case my parallelism is less than number of partitions still I believe if I create keyedstream ordering will be maintained at operator level for that key. Correct me if I am wrong. Second, one issue/challenge which I see with this model is one of the source's frequency of pushing data is very high then one partition is overloaded. Hence the task which process this will be overloaded too, however for maintaining ordering I do not have any other options but to maintain data in one partition. Thanks, Hemant On Wed, Feb 19, 2020 at 5:54 PM Arvid Heise <[hidden email]> wrote:
|
|
|
Hey Hemant, Are you able to reconstruct the ordering of the event, for example based on time or some sequence number? If so, you could create as many Kafka partitions as you need (for proper load distribution), disregarding any ordering at that point. Then you keyBy your stream in Flink, and order it within a window operator (or some custom logic in a process function) Flink is able to handle quite large states using the RocksDB statebackend. Best, Robert On Wed, Feb 19, 2020 at 6:34 PM hemant singh <[hidden email]> wrote:
|
Re: Flink Kafka connector consume from a single kafka partition
|
|
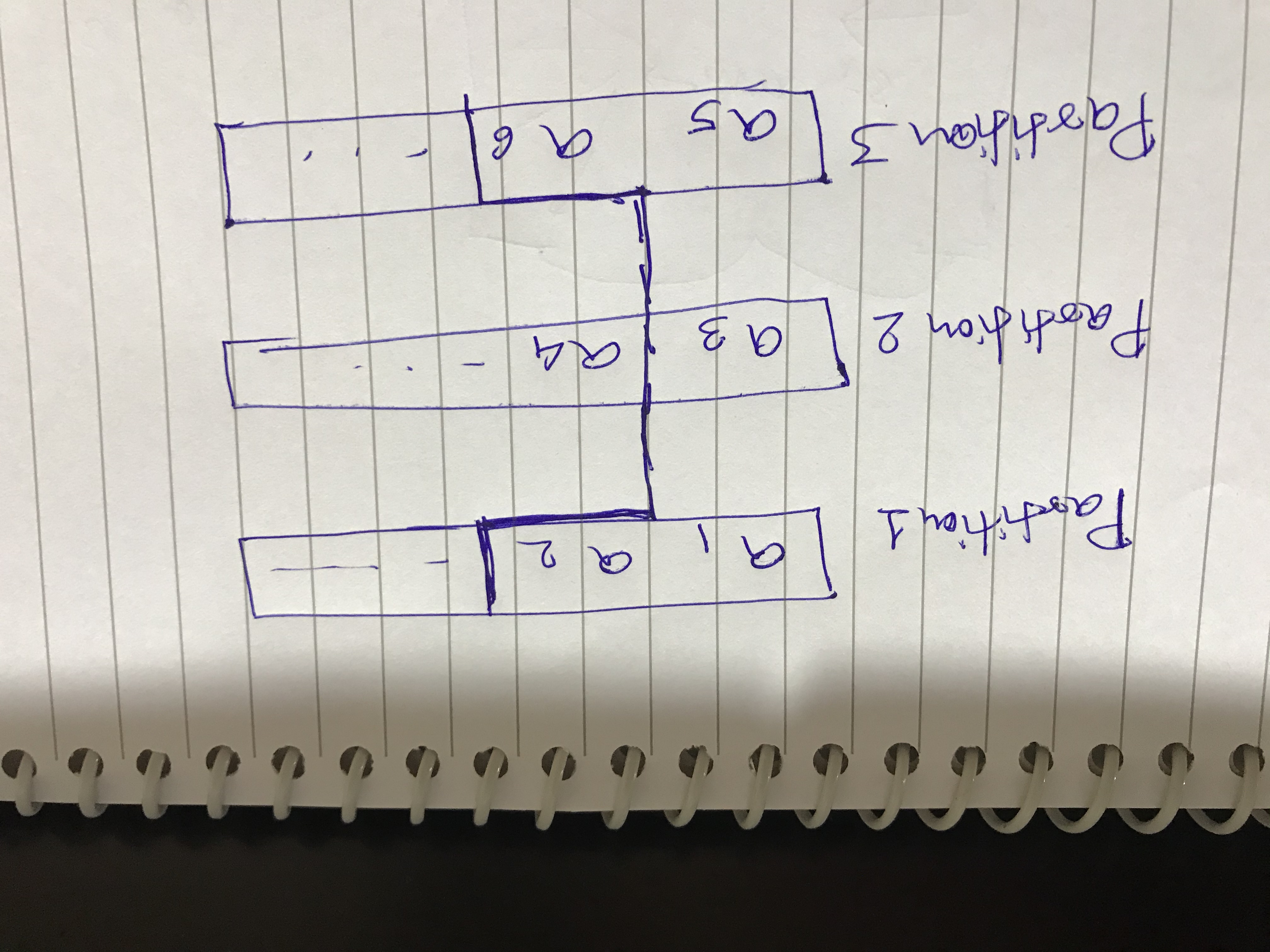
Hello Robert, Thanks for your reply. I understand window function orders the records based on timestamp (event in my case). I am also using flink cep to publish alerts to downstream system. Something like this - Pattern<TemperatureWithTimestampEvent, ?> warningPattern = Pattern.<TemperatureWithTimestampEvent> begin("first",skipStrategy) Does CEP also order the records by event timestamp internally. Secondly, I think below case as shown below, I believe the tasks will not be consuming data equally so as in below - 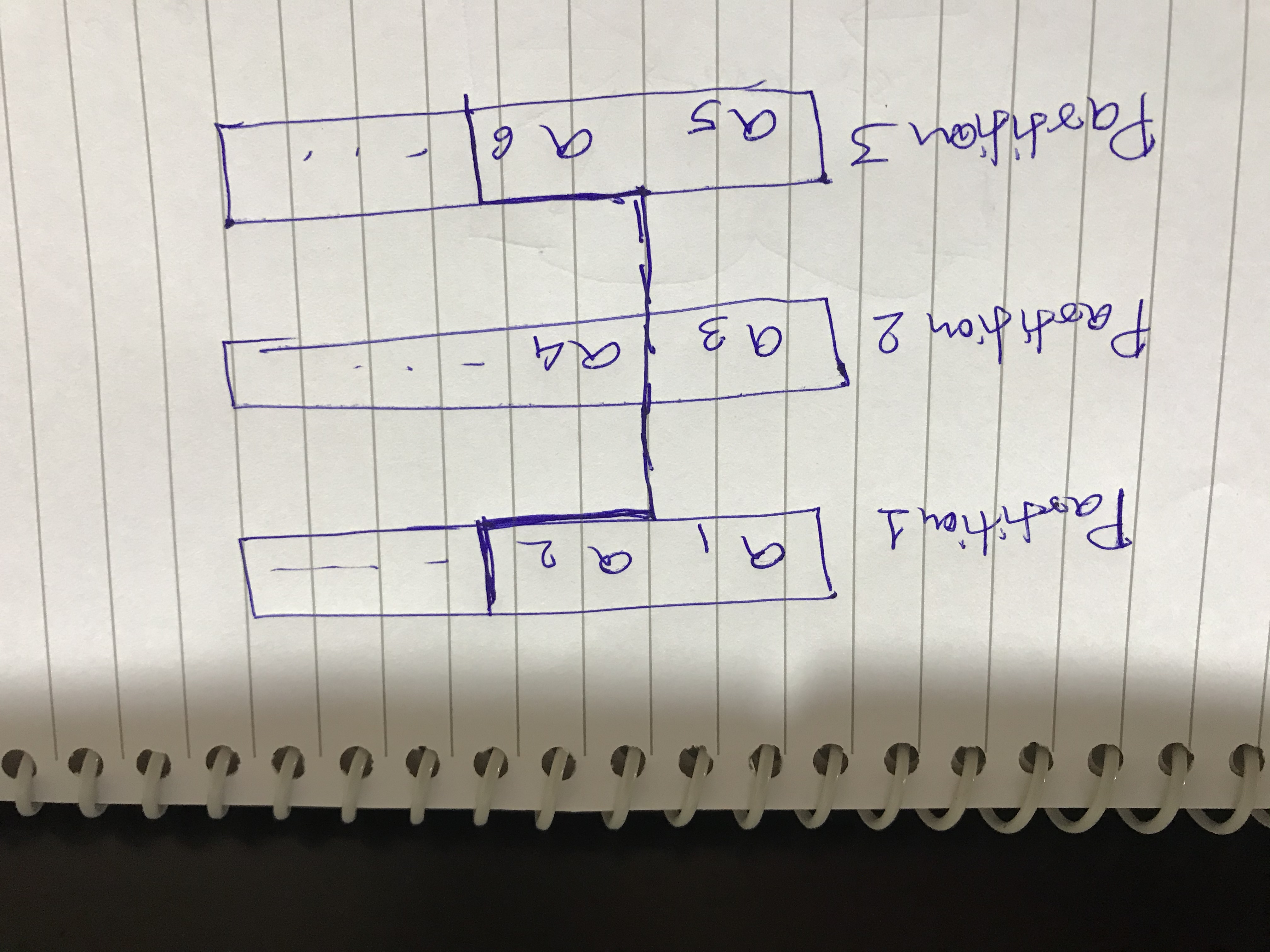 a1,a2 -> partition 1 a3 -> partition 2 a5,a6 -> partition 3 above events gets consumed and check-pointed, then a4 is getting missed from partition 2. This can be an issue for my use case. Correct me if my understanding is wrong. Thanks, Hemant On Fri, Feb 21, 2020 at 4:47 PM Robert Metzger <[hidden email]> wrote:
|
Re: Flink Kafka connector consume from a single kafka partition
|
|
Hi Hemant, I think Arvid's previous answer still best addresses your question. (minus that I would not use the reinterpretAsKeyedStream as it requires that the partitioning is exactly the same as Flink's internal partitioning) Let me rephrase a few things. First of all I think you're asking about two different issues. 1) ordering guarantees, which affects correctness 2) data skew, which affects performance As for the 1) as Arvid said if you work on a Keyed stream the
order of events within a single key will be preserved. Therefore
if in any single partitions you have events with a single
device-id, any operations on a keyed stream will preserve the
events of a single device. Even if a single task processes events
from multiple devices. You do not need to subscribe with a single
consumer to a single partition. You should just make sure you have
no unkeyed shuffles before grouping. E.g. Applying a map operator
with a different parallelism than the source parallelism. If you
do keyBy right after the source you should be safe. It will not preserve order between partitions. For that you need a way to reorder the events, e.g. event time. As for the 2) It is possible that if you have a skewed partition, the processing of it might require more resources. I think it is unavoidable unless, you are able to come up with an algorithm that does not require perfect order (e.g windowed sum aggregate). Just for a completeness CEP does reorder events according to their timestamps. Window function does not order events, as it does not have to. It must only assign events to a specific window, without necessarily ordering them. Hope that helps a bit Best, Dawid On 21/02/2020 17:15, hemant singh
wrote:
|
Re: Flink Kafka connector consume from a single kafka partition
|
|
Hello Dawid, Thanks for your response. I am planning to have data in kafka as below -
where dx -> message from device x, like d1 -> event from device 1. As you/Arvid have suggested I will create a keyed stream based on device-id and then do my operations like window or CEP. I am using AscendingTimestampExtractor for timestamp and watermark. Could you please let me know if you see any issue arising if for load balancing I mix some devices in one partition but create a keyed stream to work on one device stream. Thanks, Hemant On Mon, Feb 24, 2020 at 4:12 PM Dawid Wysakowicz <[hidden email]> wrote:
|
Re: Flink Kafka connector consume from a single kafka partition
|
|
As long as your Kafka partitioning is equal to the Flink keys, all is fine. Further, even if the keys are subkeys of partitioning you will read data in order. Only when you mix different partitions, you will experience out of orderness. On Mon, Feb 24, 2020 at 5:36 PM hemant singh <[hidden email]> wrote:
|
Re: Flink Kafka connector consume from a single kafka partition
|
|
Thanks Arvid. On Wed, Feb 26, 2020 at 8:13 PM Arvid Heise <[hidden email]> wrote:
|
| Free forum by Nabble | Edit this page |