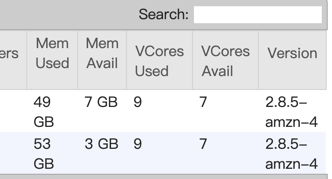
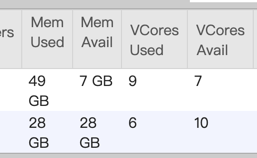
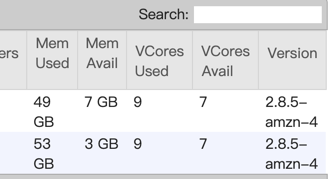
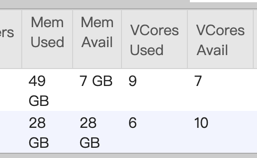
Do you mean a failed job does not release resources to yarn?
- if so, is the job in restarting process? A job in recovery will reuse the slots so they will not be release.
Or a failed job cannot acquire slots when it is restarted in auto-recovery?
- if so, normally the job should be in a loop like (restarting tasks -> allocating slots -> failed due to not be able to acquire enough slots -> restarting task -> ...). Would you check whether the job is in such a loop? Or the job cannot allocate enough slots even if the cluster has enough resource?