Disk usage during savepoints


|
Hi, We're using the Rocks state backend with incremental checkpoints and savepoints setup for S3. We notice that every time we trigger a savepoint, one of the local disks on our host explodes in disk usage. What is it that savepoints are doing which would cause so much disk to be used? Our checkpoints are a few GiB in size, is the savepoint combining all the checkpoints together at once on disk? I figured that incremental checkpoints would compact over time in the background, is that correct? Thanks Graph here. Parallelism is 1 and volume size is 256 GiB. 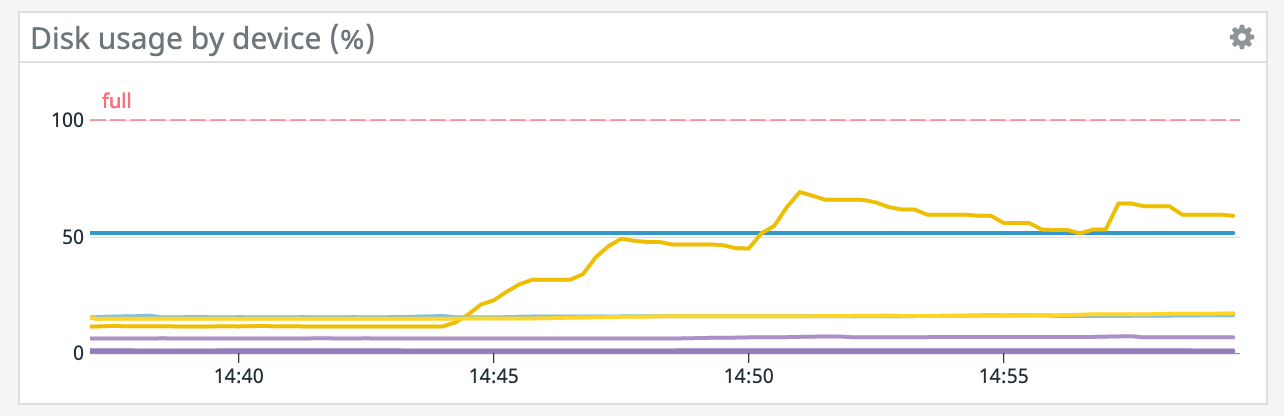 -- Rex Fenley | Software Engineer - Mobile and Backend Remind.com | BLOG | FOLLOW US | LIKE US |
Re: Disk usage during savepoints
|
|
RocksDB does do compaction in the background, and incremental checkpoints simply mirror to S3 the set of RocksDB SST files needed by the current set of checkpoints. However, unlike checkpoints, which can be incremental, savepoints are always full snapshots. As for why one host would have much more state than the others, perhaps you have significant key skew, and one task manager is ending up with more than its share of state to manage. Best, David On Sat, Dec 12, 2020 at 12:31 AM Rex Fenley <[hidden email]> wrote:
|
|
|
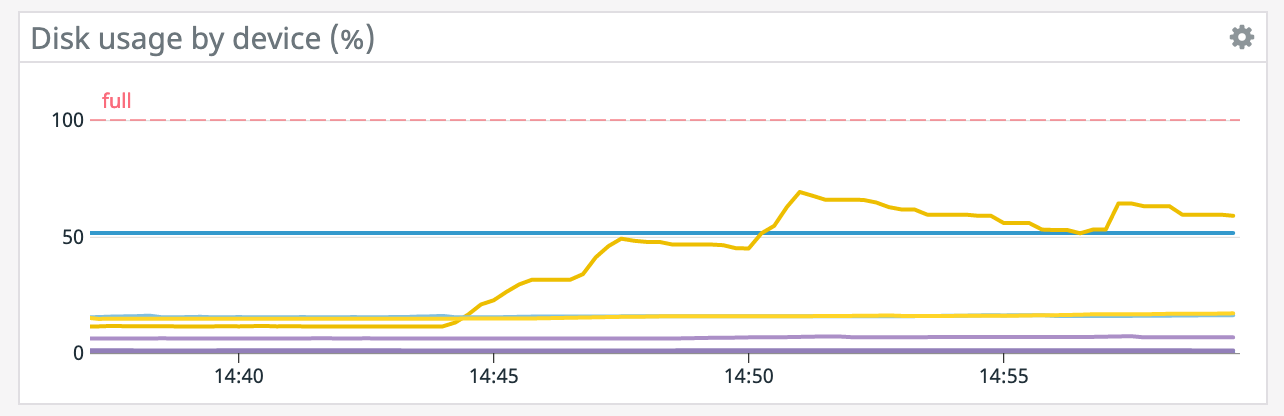
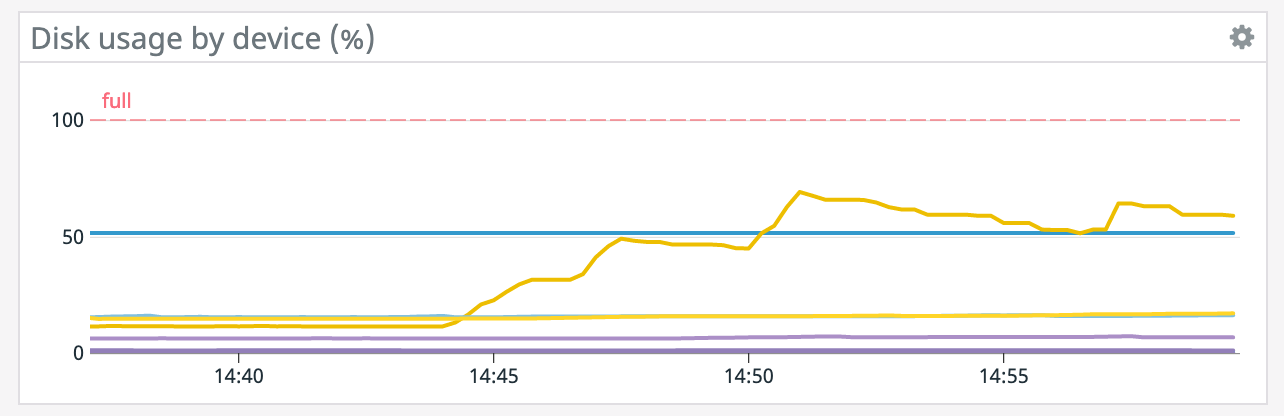
Our first big test run we wanted to eliminate as many variables as possible, so this is on 1 machine with 1 task manager and 1 parallelism. The machine has 4 disks though, and as you can see, they mostly all use around the same space for storage until a savepoint is triggered. Could it be that given a parallelism of 1, certain operator's states are pinned to specific drives and as it's doing compaction it's moving everything over to that drive into a single file? In which case, would greater parallelism distribute the work more evenly? Thanks! On Sat, Dec 12, 2020 at 2:35 AM David Anderson <[hidden email]> wrote:
-- Rex Fenley | Software Engineer - Mobile and Backend Remind.com | BLOG | FOLLOW US | LIKE US |
|
|
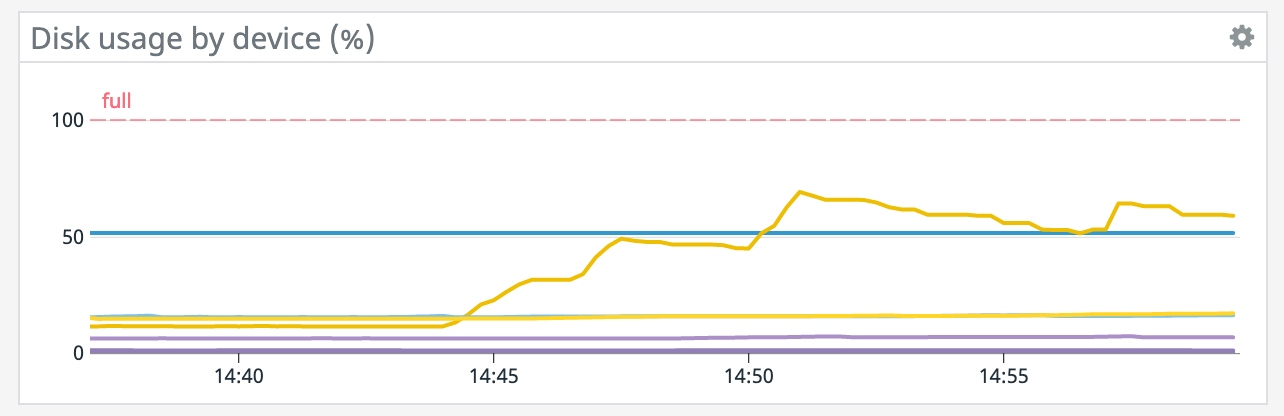
Also, small correction from earlier, there are 4 volumes of 256 GiB so that's 1 TiB total. On Sat, Dec 12, 2020 at 10:08 AM Rex Fenley <[hidden email]> wrote:
-- Rex Fenley | Software Engineer - Mobile and Backend Remind.com | BLOG | FOLLOW US | LIKE US |
|
|
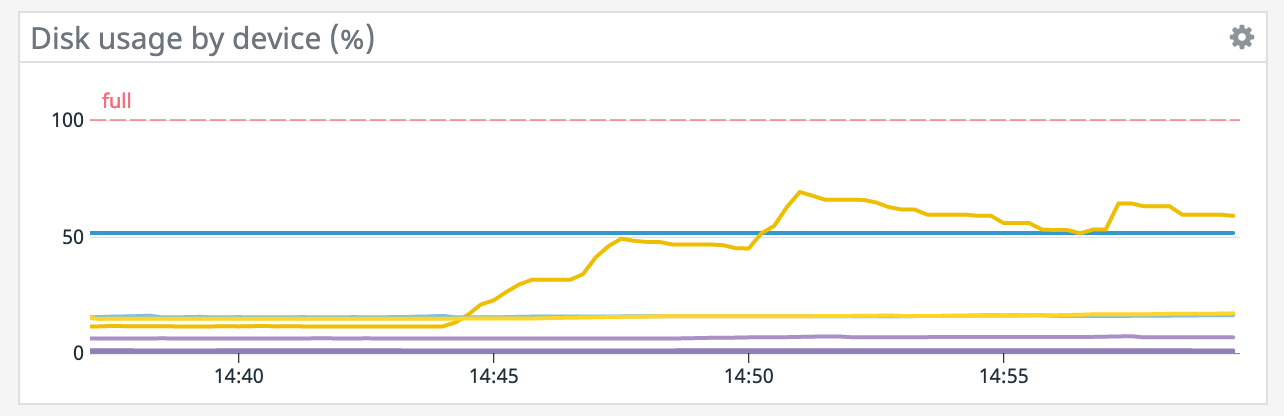
Our job just crashed while running a savepoint, it ran out of disk space. I inspected the disk and found the following: -rw------- 1 yarn yarn 10139680768 Dec 12 22:14 presto-s3-10125099138119182412.tmp -rw------- 1 yarn yarn 10071916544 Dec 12 22:14 presto-s3-10363672991943897408.tmp -rw------- 1 yarn yarn 10276716544 Dec 12 22:14 presto-s3-12109236276406796165.tmp -rw------- 1 yarn yarn 9420505088 Dec 12 22:14 presto-s3-12584127250588531727.tmp -rw------- 1 yarn yarn 10282295296 Dec 12 22:14 presto-s3-14352553379340277827.tmp -rw------- 1 yarn yarn 9463644160 Dec 12 22:14 presto-s3-14552162277341829612.tmp -rw------- 1 yarn yarn 10447626240 Dec 12 22:14 presto-s3-14660072789354472725.tmp -rw------- 1 yarn yarn 9420906496 Dec 12 22:14 presto-s3-15982235495935827021.tmp -rw------- 1 yarn yarn 10268663808 Dec 12 22:14 presto-s3-16188204950210407933.tmp -rw------- 1 yarn yarn 9309986816 Dec 12 22:14 presto-s3-17905518564307248197.tmp -rw------- 1 yarn yarn 9491578880 Dec 12 22:14 presto-s3-1839692230976299010.tmp -rw------- 1 yarn yarn 9308168192 Dec 12 22:14 presto-s3-2488279210497334939.tmp -rw------- 1 yarn yarn 9496961024 Dec 12 22:14 presto-s3-3559445453885492666.tmp -rw------- 1 yarn yarn 9467682816 Dec 12 22:14 presto-s3-4932415031914708987.tmp -rw------- 1 yarn yarn 10042425344 Dec 12 22:14 presto-s3-5619769647590893462.tmp So it appears that everything is being written, on one of our disks first, locally before being written to S3. Is there a way to tell flink or the os to divide this work up across mounted disks so it's not all up to 1 disk? Thanks! On Sat, Dec 12, 2020 at 10:12 AM Rex Fenley <[hidden email]> wrote:
-- Rex Fenley | Software Engineer - Mobile and Backend Remind.com | BLOG | FOLLOW US | LIKE US |
|
|
Hey Rex, If I'm reading the Flink code correctly, then RocksDB will allocate it's storage across all configured tmp directories. Flink is respecting the io.tmp.dirs configuration property for that. it seems that you are using Flink on YARN, where Flink is respecting the tmp directory configs from YARN. if Yarn is configured correctly, Flink should know about the existence of those disks. In my case, I have 2 configured TMP directories: 2020-12-16 09:35:51,268 INFO org.apache.flink.runtime.taskexecutor.TaskManagerServices [] - Temporary file directory '/tmp/flink1': total 828 GB, usable 58 GB (7.00% usable) 2020-12-16 09:35:51,268 INFO org.apache.flink.runtime.taskexecutor.TaskManagerServices [] - Temporary file directory '/tmp/flink2': total 828 GB, usable 58 GB (7.00% usable) 2020-12-16 09:35:51,272 INFO org.apache.flink.runtime.io.disk.FileChannelManagerImpl [] - FileChannelManager uses directory /tmp/flink1/flink-io-55e469a7-d95d-4bc4-b8ab-500c3ddb998c for spill files. 2020-12-16 09:35:51,273 INFO org.apache.flink.runtime.io.disk.FileChannelManagerImpl [] - FileChannelManager uses directory /tmp/flink2/flink-io-a619b51a-9473-4978-a898-6ef6c5e72be4 for spill files. you should see 4 of those messages. I'm assuming your tmp directories are configured correctly. Can you try this experiment with 1 machine, 1 task manager but a parallelism of 4 (or 8) and see if the data is properly distributing? On Sun, Dec 13, 2020 at 12:43 AM Rex Fenley <[hidden email]> wrote:
|
| Free forum by Nabble | Edit this page |