Hi!
The terms are not yet really standard terms, we only use them to explain the differences in the runtime design of the two systems. Maybe they will sink into the data processing vocabulary...
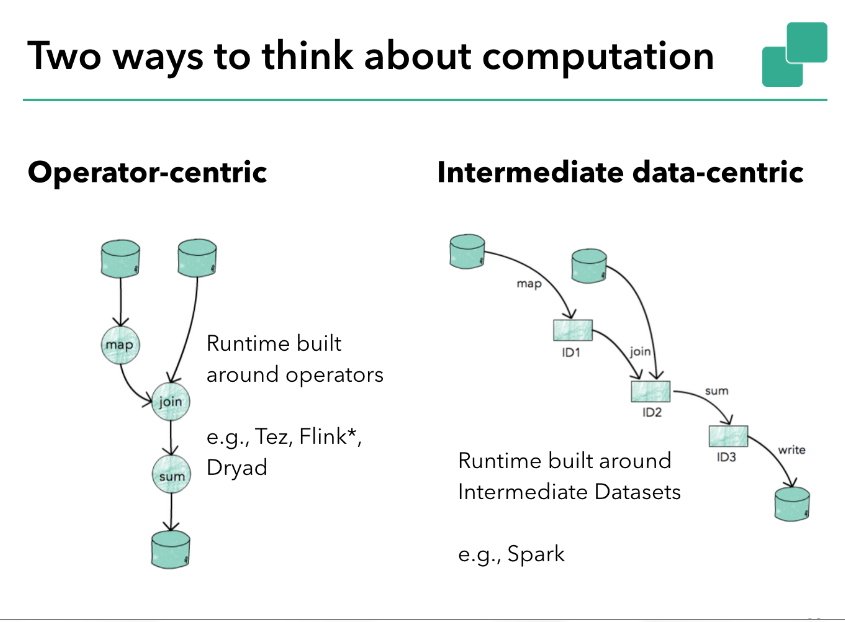
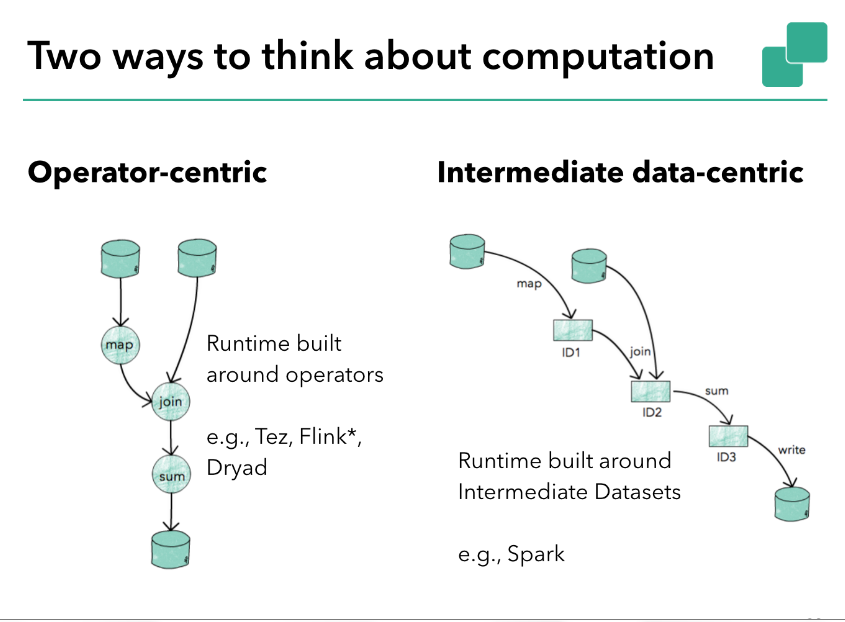
First and most importantly, the two are not mutually exclusive. Both have to deal with computation and with intermediate data/results. To a certain extend, both Flink and Spark implement both, but with different assumption and prominence of the concepts:
Operator-centric:
------------------------
This model describes computation as operations/transformations on data streams, which can come from data sources, or previous operations, or cached data.
Proper data streaming architectures are more natural in this model, because long lived operations ans "continuous computation" (as true streaming assumes) are in its heart.
For stateful operations, this model is a good match as well, in my opinion, as it does not make the assumption of "side effect"-free transformations of the data sets.
Concerning iterations: Iterations work well in this model. They do not work as rolled-out loops (as in Spark), but as "closed loops". So far, all performance experiments I have seen on iterative computations in both approaches have favored this model over the "intermediate results".
For streaming iterations with asynchronous feedback, this the operator model works well as well, as it again provides continuous feedback, rather than batched.
Intermediate result centric:
-----------------------------------
The main advantages I see for this model are a clear handle to intermediate results to re-use them across jobs.
That means (a) in interactive sessions (multiple queries against same intermediate data set) and (b) in different programs that share intermediate results.
This model is a low-hanging fruit for iterative jobs, but it boils down to rolled-out loops, which may not be as efficient as closed loops.
Mixed
-----------
As said in the beginning, the two are not exclusive. By now, Flink actually has most mechanisms in place to also represent intermediate results as first-class citizens, to allow sharing across applications.
Intermediate results are in Flink simply streams, which may be fully buffered/cached for cases where one wants to consume them multiple times or share them.
The code for that is not fully merged, yet.
I hope that helped shed some light.
Greetings,
Stephan