Diagnosing high cpu/memory issue in Flink

Diagnosing high cpu/memory issue in Flink

|
Hi, I am looking for help with a performance
problem I have with Flink 1.3.2, running on 2 task managers on EMR with BEAM 2.2.0. I’ve included details and observations below.
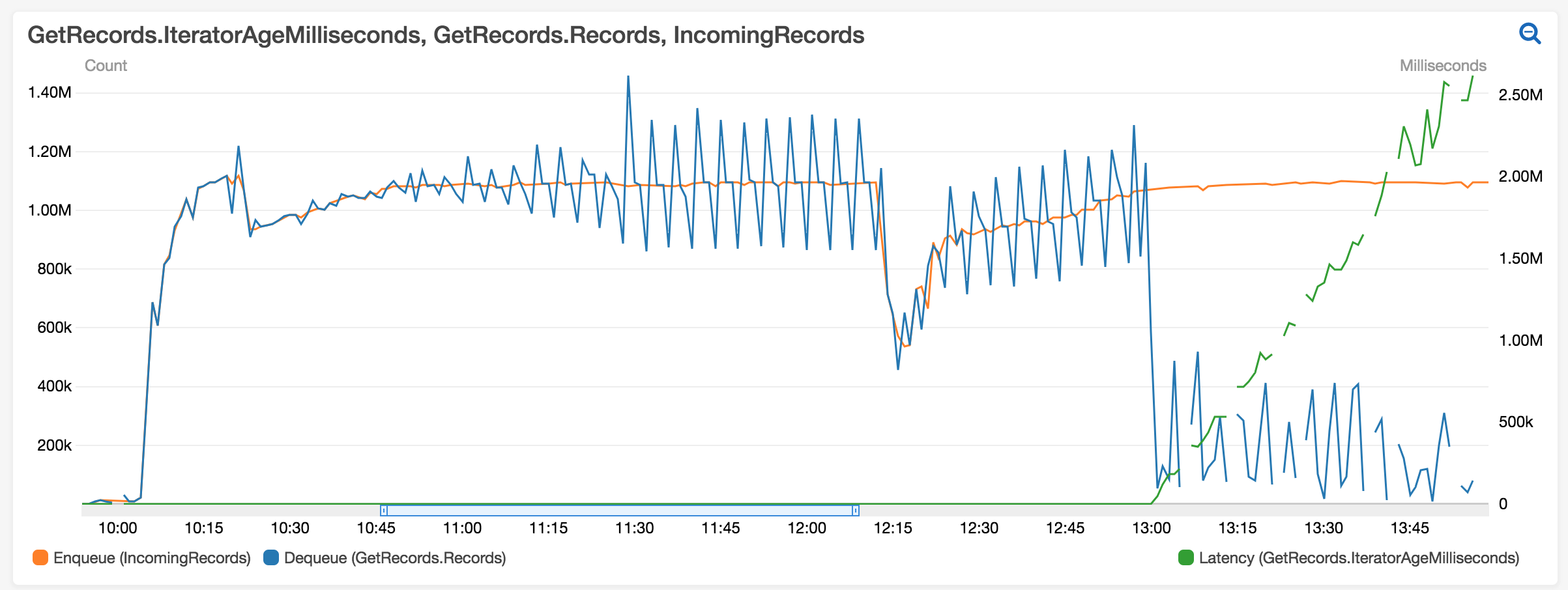
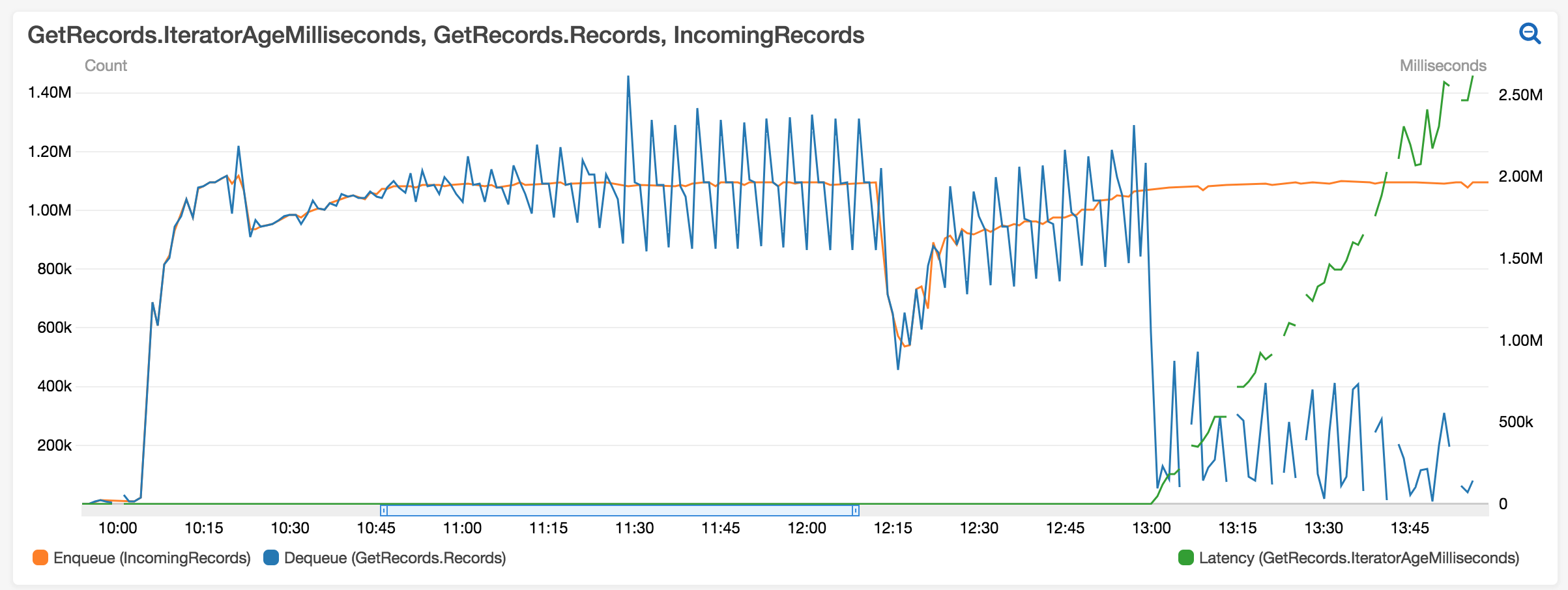
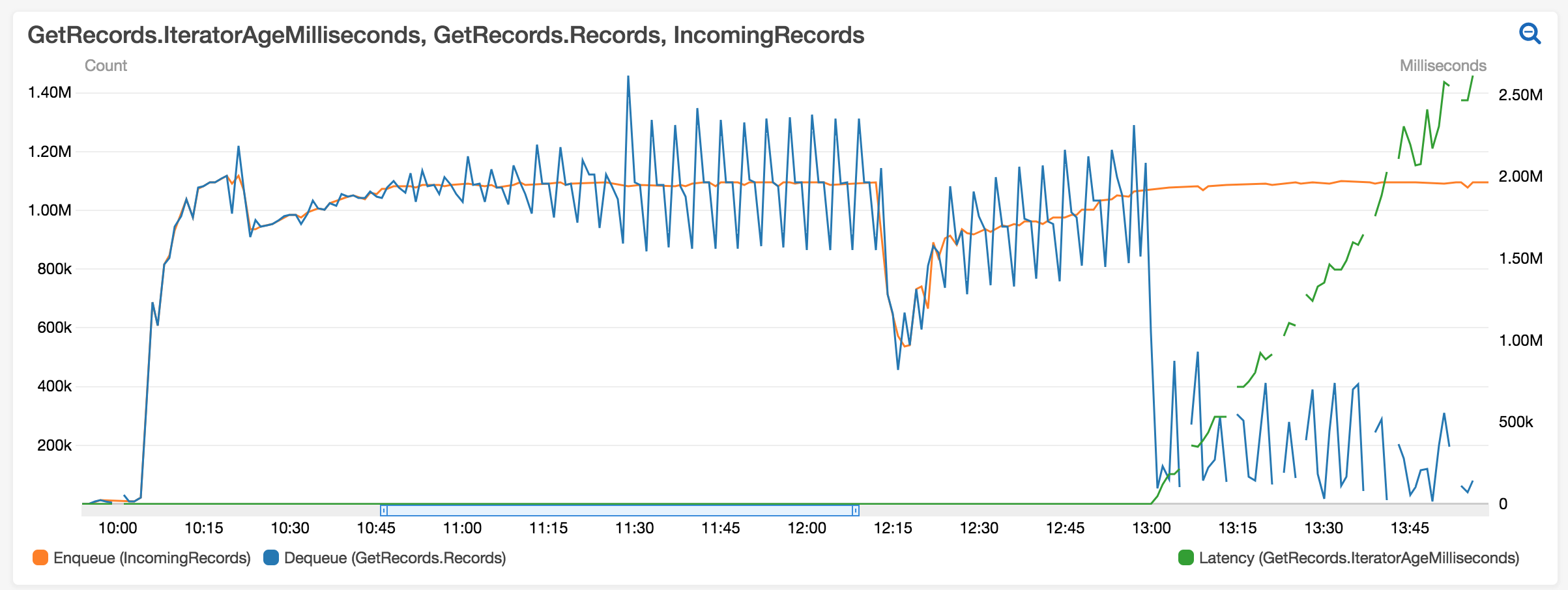
The blue line represents
the number of records read from
a kinesis stream by the job and
the orange line is the number of records pushed to the stream by users. As you can see, after some time
the job begins to slow down (around 10 AM) and it breaks completely around 1 PM.
The job supports late data for up to 3 hours.
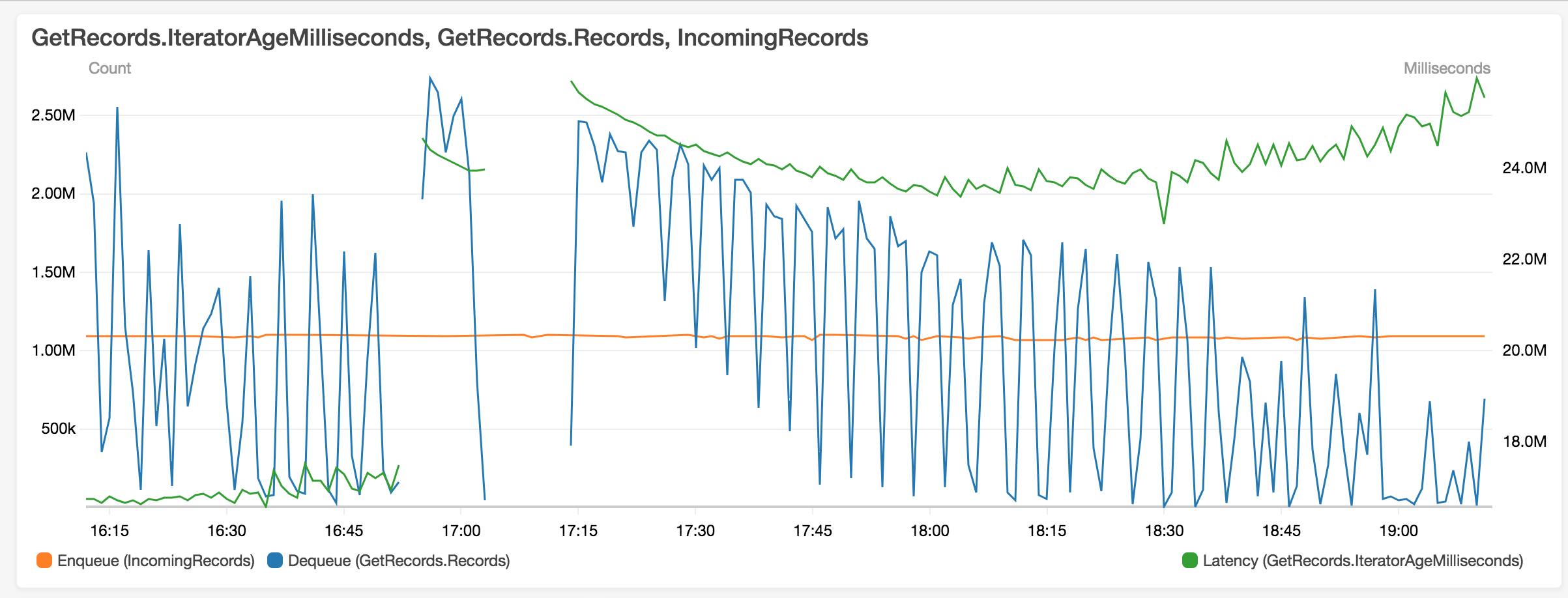
 Another example: (dips corresponds to times when checkpointing is in progress) 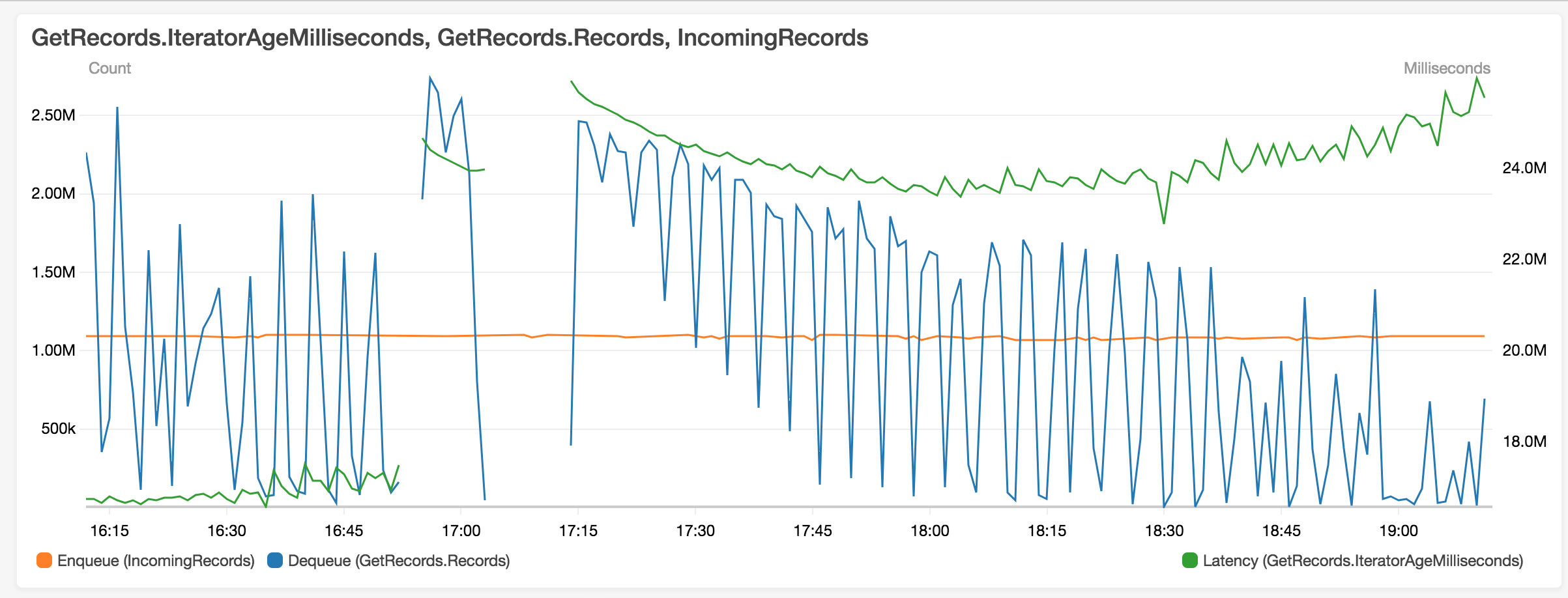
I made some observations:
- The dip along the blue line corresponds to checkpoints being created (every 4 minutes). We use S3 as checkpoint store. I thought that checkpoints
are created asynchronously. Should they impact the performance of the job?
The checkpoints are roughly 10GB.
- How do I check that I need to assign more memory to Flink Managed Memory and not to User Managed Memory (taskmanager.memory.fraction) -
The job is using an allowed lateness of 3 hours and will recompute the result of the given key if that key changes within
the allowed lateness period. Does
this
- I noticed that the first task manger (see below) is running a lot of more PS_MarkSweep cycles.
Every cycle takes around 6 seconds and the number of gc cycles increases linearly
with wobbling on the graph above. When the job literally slows down then
the CPU on the task manager is hitting 100%.Is it a reasonable assumption that it's the PS_MarkSweep
that is eating up the whole cpu because it needs to scan the whole heap,
and it cannot release any memory as it's needed to keep the previous records within
the allowed
lateness of 3 hours?
- Do you think I could get any better performance using taskmanager.memory.off-h
MemoryJVM (Heap/Non-Heap)
Outside JVM
NetworkMemory Segments
Garbage Collection
Overview
MemoryJVM (Heap/Non-Heap)
Outside JVM
NetworkMemory Segments
Garbage Collection
Cheers, Pawel Bartoszek |
Re: Diagnosing high cpu/memory issue in Flink
|
|
Hi Pawel,
If you're not using Rocksdb state backend, try switching to it. I've had bad experiences with FsStateBackend with large windows, due to long GC pause when old state need cleaning up.
Best regards, Kien
On 2/16/2018 2:34 AM, Pawel Bartoszek
wrote:
|
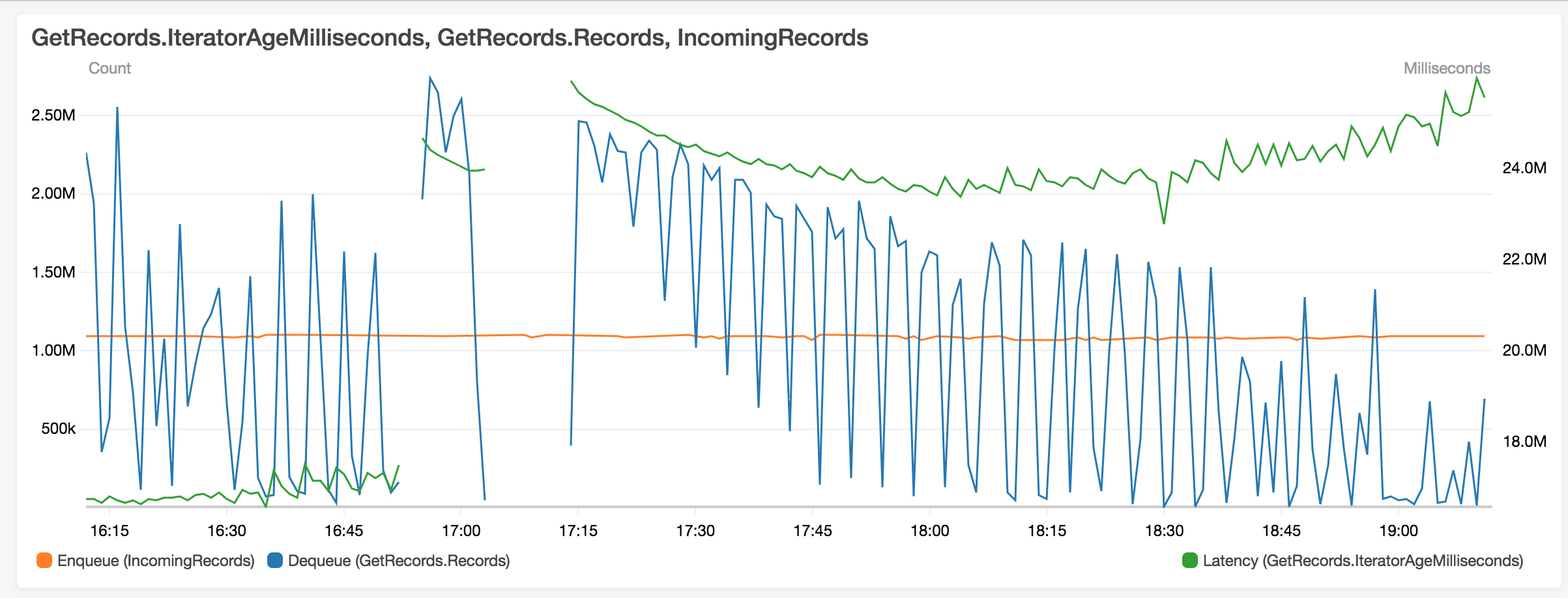
Re: Diagnosing high cpu/memory issue in Flink
|
|
Hi Pawel, given your description it could perfectly be the case that you're running into GC problems. As Kien suggested, you should use the RocksDBStateBackend if you're dealing with a lot of state. This state backend is the only one which supports spilling right now. Moreover, you should make sure to enable asynchronous checkpoints. Otherwise checkpoints might decrease performance of your job. Cheers, Till On Sat, Feb 17, 2018 at 2:45 PM, Kien Truong <[hidden email]> wrote:
|
«
Return to (DEPRECATED) Apache Flink User Mailing List archive.
|
1 view|%1 views
| Free forum by Nabble | Edit this page |