Declaring and using ROW data type in PyFlink DataStream


|
Hello,
What is the correct way to use Python dict's as ROW type in pyflink? Im trying this: output_type_info = Types.ROW_NAMED(['id', 'data', 'timestamp' ], class MyProcessFunction(KeyedProcessFunction): at java.io.DataInputStream.readUnsignedByte(DataInputStream.java:290) However it works with primitive types like Types.STRING(). According to the documentation the ROW type corresponds to the python's dict type. Regards |
Re: Declaring and using ROW data type in PyFlink DataStream
|
|
Hi meneldor, The main cause of the error is that there is a bug in `ctx.timer_service().current_watermark()`. At the beginning the stream, when the first record come into the KeyedProcessFunction.process_element() , the current_watermark will be the Long.MIN_VALUE at Java side, while at the Python side, it becomes LONG.MAX_VALUE which is 9223372036854775807. >>> ctx.timer_service().register_event_time_timer(current_watermark + 1500)Here, 9223372036854775807 + 1500 is 9223372036854777307 which will be automatically converted to a long interger in python but will cause Long value overflow in Java when deserializing the registered timer value. I will craete a issue to fix the bug.Let’s return to your initial question, at PyFlink you could create a Row Type data as bellow: >>> row_data = Row(id=‘my id’, data=’some data’, timestamp=1111) And I wonder which release version of flink the code snippet you provided based on? The latest API for KeyedProcessFunction.process_element() and KeyedProcessFunction.on_timer() will not provid a `collector` to collect output data but use `yield` which is a more pythonic approach. Please refer to the following code: def keyed_process_function_example(): Best, Shuiqiang meneldor <[hidden email]> 于2021年1月14日周四 下午10:45写道:
|
|
|
Thank you for the answer Shuiqiang! Im using the last apache-flink version: Requirement already up-to-date: apache-flink in ./venv/lib/python3.7/site-packages (1.12.0) however the method signature is using a collector: 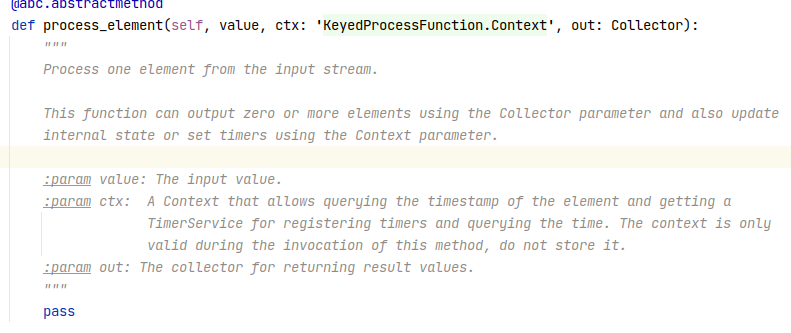 Im using the setup-pyflink-virtual-env.sh shell script from the docs(which uses pip). Regards On Thu, Jan 14, 2021 at 6:47 PM Shuiqiang Chen <[hidden email]> wrote:
|
Re: Declaring and using ROW data type in PyFlink DataStream
|
|
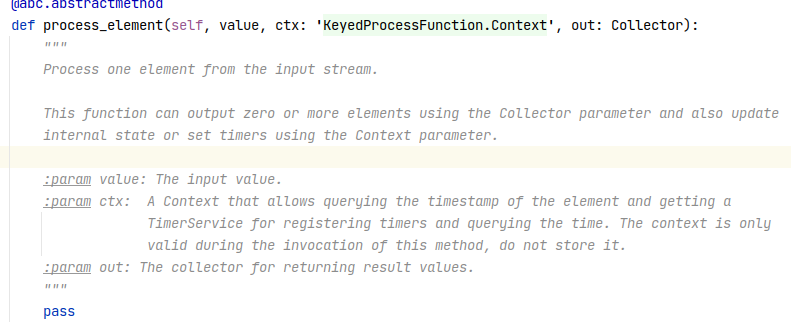
Hi meneldor, I guess Shuiqiang is not using the pyflink 1.12.0 to develop the example. The signature of the `process_element` method has been changed in the new version[1]. In pyflink 1.12.0, you can use `collector`.collect to send out your results. [1] https://issues.apache.org/jira/browse/FLINK-20647 Best, Xingbo meneldor <[hidden email]> 于2021年1月15日周五 上午1:20写道:
|
|
|
I imported pyflink.common.types.Row and used it as Shuiqiang suggested but now Java throws a memory exception: Caused by: TimerException{java.lang.OutOfMemoryError: Java heap space} Regards On Fri, Jan 15, 2021 at 4:00 AM Xingbo Huang <[hidden email]> wrote:
|
Re: Declaring and using ROW data type in PyFlink DataStream
|
|
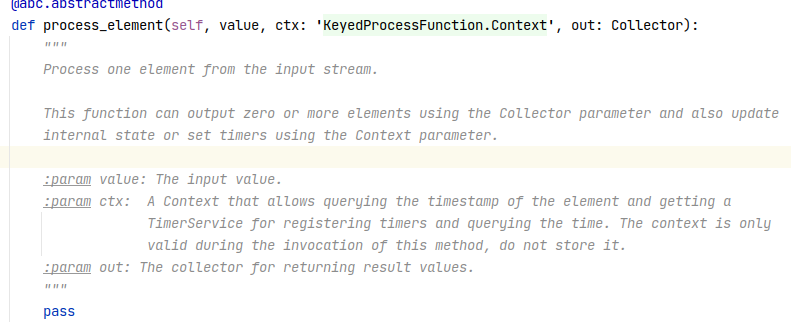
Hi meneldor, Xingbo, Sorry for the late reply. Thanks a lot for Xingbo’s clarification. And according to the stacktrace of the exception, could you have a check whether the result data match the specified return type? BTW, please share your code if it’s ok, it will be of help to debug. Best, Shuiqiang meneldor <[hidden email]> 于2021年1月15日周五 下午4:59写道:
|
|
|
Hi, here is the code. This is a JSON data from Maxwell CDC: env = StreamExecutionEnvironment.get_execution_environment() This is the input data: {"commit": true, "ts": 1610546861, "type": "update", "data": {"id": "id2", "tp": "B", "device_ts": 1610546861, "account": "279"}, "old": {}}1) If I change the output type to STRING() and return a str from process_element everything is OK but I need to use JsonRowSerializationSchema later on that data.2) I'm not sure what to return in on_timer as it's missing the value argument which process_element has. Regards On Mon, Jan 18, 2021 at 4:47 AM Shuiqiang Chen <[hidden email]> wrote:
|
Re: Declaring and using ROW data type in PyFlink DataStream
|
|
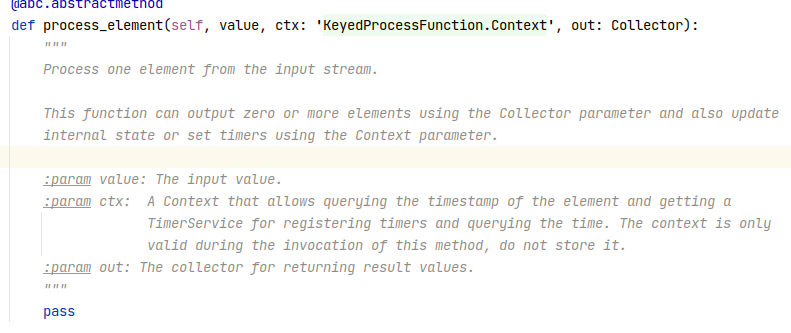
Hi meneldor, Actually, the return type of the on_timer() must be the same as process_element(). It seems that the yield value of process_element() is missing the `timestamp` field. And the `output_type_info` has four field names but with 5 field types. Could you align them? Best, Shuiqiang |
|
|
Actually the output_type_info is ok, it was copy/paste typo. I changed the function to: class MyProcessFunction(KeyedProcessFunction):And the type to: output_type_info = Types.ROW_NAMED(['id', 'tp', 'account', 'device_ts', 'timestamp'],I cant return the same data in on_timer() because there is no value parameter. Thats why i hardcoded device_ts. However the exception persists. I am not sure if the timestamp field should be included in output_type_info as i did now. Regards On Mon, Jan 18, 2021 at 2:57 PM Shuiqiang Chen <[hidden email]> wrote:
|
Re: Declaring and using ROW data type in PyFlink DataStream
|
|
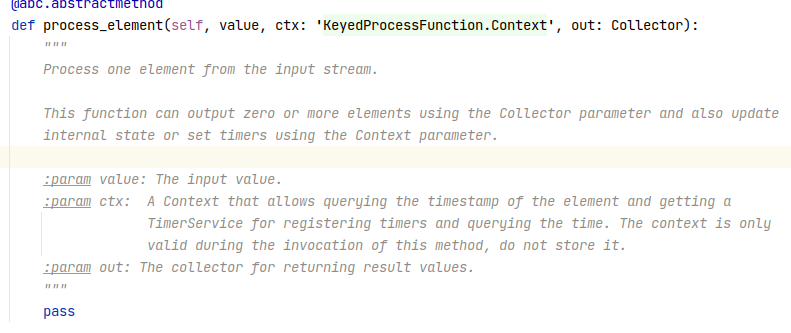
Hi Shuiqiang, meneldor, 1. In fact, there is a problem with using Python `Named Row` as the return value of user-defined function in PyFlink. When serializing a Row data, the serializer of each field is consistent with the order of the Row fields. But the field order of Python `Named Row` has been sorted by field, and it was designed to better compare Named Row and calculate hash values. So this can lead to serialization/deserialization errors(The correspondence between serializer and field is wrong). It is for performance considerations that serializers are not specified according to file name, but `Named Row` support can be achieved at the expense of a little performance for ease of use. For the current example, I suggest returning a list or a normal Row, instead of a Named Row. 2. In pyflink 1.12.0, the method signature of `on_timer` should be `def process_element(self, value, ctx: 'KeyedProcessFunction.Context', out: Collector)`[1]. If you want to send data in `on_timer`, you can use `Collector.collect`. e.g. def process_element(self, value, ctx: 'KeyedProcessFunction.Context', out: Collector): out.collect(Row('a', 'b', 'c')) 3. >>> I am not sure if the timestamp field should be included in output_type_info as i did now. If you return data with a time_stamp field, `output_type_info` needs to have `time_stamp` field. For example, the data returned in your example contains `time_stamp`, so your `output_type_info` needs to have the information of this field. Best, Xingbo
|
|
|
Thank you Xingbo 1. I will try to use normal list instead of named. Thanks! 2. There is a new 1.12.1 version of pyflink which is using process_element(self, value, ctx: 'KeyedProcessFunction.Context') Thank you! On Mon, Jan 18, 2021 at 4:18 PM Xingbo Huang <[hidden email]> wrote:
|
Re: Declaring and using ROW data type in PyFlink DataStream
|
|
Hi meneldor, 1. Yes. Although release 1.12.1 has not been officially released, it is indeed available for download on PyPI. In PyFlink 1.12.1, you only need to `yield` your output in `on_timer`. 2. Whenever an element comes, your `process_element` method will be invoked, so you can directly get the `value` parameter in `process_element`. The firing of the `on_timer` method depends on your registering timer, as you wrote in the example `ctx.timer_service().register_event_time_timer(current_watermark + 1500)`. You might need state access[1] which will be supported in release-1.13. At that time, you can get your state in `on_timer`, so as to conveniently control the output. [1] https://cwiki.apache.org/confluence/display/FLINK/FLIP-153%3A+Support+state+access+in+Python+DataStream+API. Best, Xingbo meneldor <[hidden email]> 于2021年1月18日周一 下午10:44写道:
|
|
|
Thank you Xingbo! Do you plan to implement CoProcess functions too? Right now i cant find a convenient method to connect and merge two streams? Regards On Tue, Jan 19, 2021 at 4:16 AM Xingbo Huang <[hidden email]> wrote:
|
Re: Declaring and using ROW data type in PyFlink DataStream
|
|
Hi meneldor, Yes. As the first version of Python DataStream, release-1.12 has not yet covered all scenarios. In release-1.13, we will extend the function of Python DataStream to cover most scenarios, and CoProcessFunction will obviously be in it. Best, Xingbo meneldor <[hidden email]> 于2021年1月19日周二 下午4:52写道:
|
«
Return to (DEPRECATED) Apache Flink User Mailing List archive.
|
1 view|%1 views
| Free forum by Nabble | Edit this page |