Debug Slowness in Async Checkpointing


|
Hi, Flink users
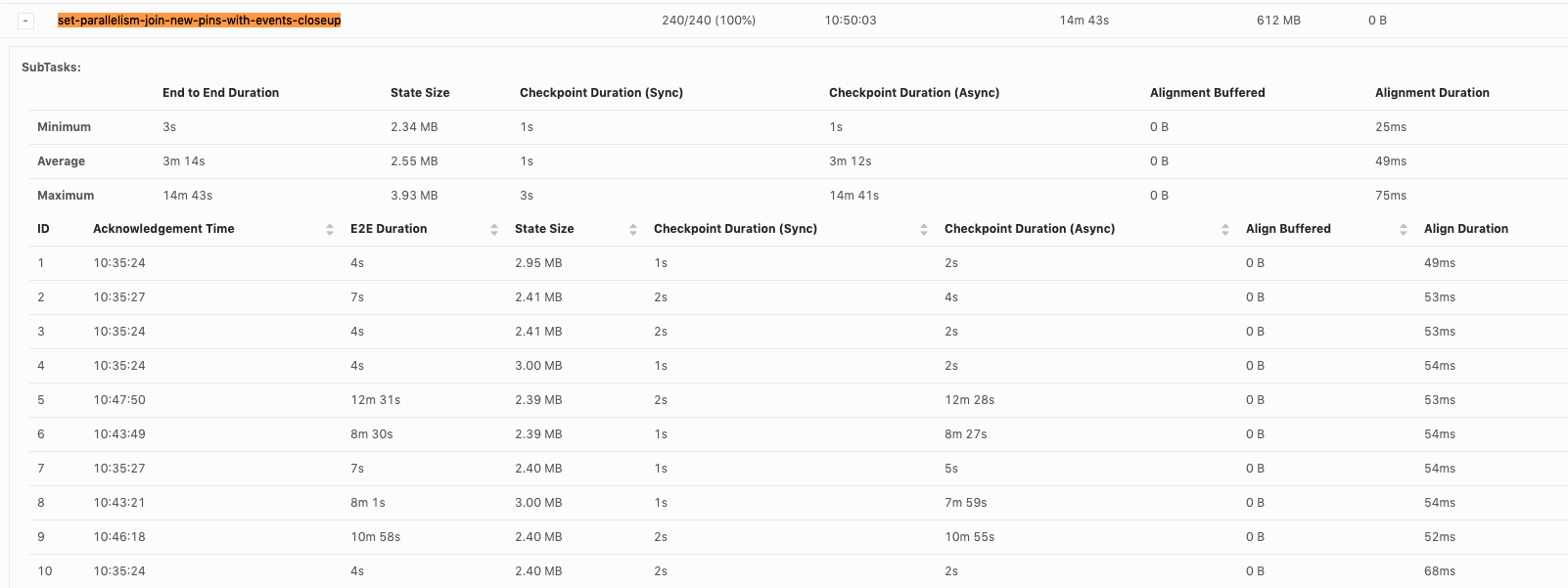
We notice sometimes async checkpointing can be extremely slow, leading to checkpoint timeout. For example, For a state size around 2.5MB, it could take 7~12min in async checkpointing: 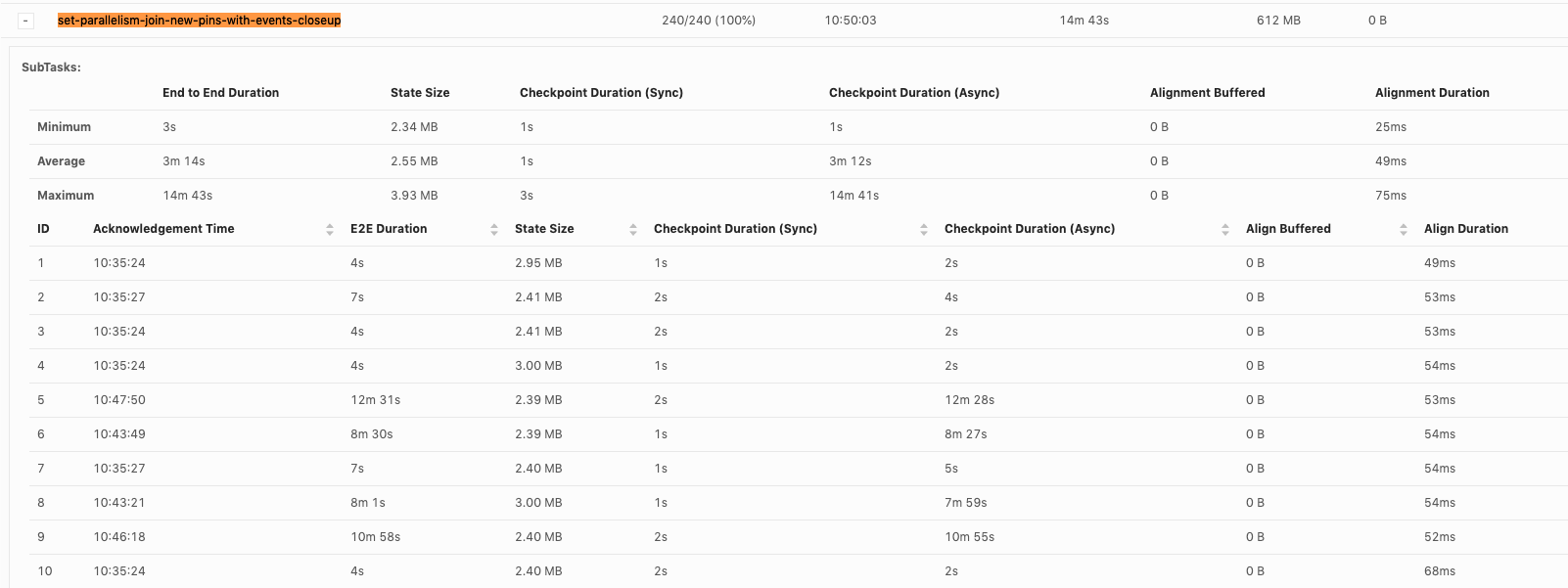 Notice all the slowness comes from async checkpointing, no delay in sync part and barrier assignment. As we use rocksdb incremental checkpointing, I notice the slowness might be caused by uploading the file to s3. However, I am not completely sure since there are other steps in async checkpointing. Does flink expose fine-granular metrics to debug such slowness? setup: flink 1.9.1, rocksdb incremental state backend, S3AHaoopFileSystem Best Lu |
|
|
Hi, did you check the TaskManager logs if there are retries by the s3a file system during checkpointing? I'm not aware of any metrics in Flink that could be helpful in this situation. Best, Robert On Tue, Apr 14, 2020 at 12:02 AM Lu Niu <[hidden email]> wrote:
|
|
|
Hi, Robert Thanks for replying. To improve observability , do you think we should expose more metrics in checkpointing? for example, in incremental checkpoint, the time spend on uploading sst files? https://github.com/apache/flink/blob/5b71c7f2fe36c760924848295a8090898cb10f15/flink-state-backends/flink-statebackend-rocksdb/src/main/java/org/apache/flink/contrib/streaming/state/snapshot/RocksIncrementalSnapshotStrategy.java#L319 Best Lu On Fri, Apr 17, 2020 at 11:31 AM Robert Metzger <[hidden email]> wrote:
|
|
|
Hi Lu, were you able to resolve the issue with the slow async checkpoints? I've added Yu Li to this thread. He has more experience with the state backends to decide which monitoring is appropriate for such situations. Best, Robert On Tue, Apr 21, 2020 at 10:50 PM Lu Niu <[hidden email]> wrote:
|
|
|
Hi, Robert Thanks for relying. Yeah. After I added monitoring on the above path, it shows the slowness did come from uploading file to s3. Right now I am still investigating the issue. At the same time, I am trying PrestoS3FileSystem to check whether that can mitigate the problem. Best Lu On Thu, Apr 23, 2020 at 8:10 AM Robert Metzger <[hidden email]> wrote:
|
Re: Debug Slowness in Async Checkpointing
|
|
Hi If the bottleneck is the upload part, did you even have tried upload files using multithread[1] Lu Niu <[hidden email]> 于2020年4月24日周五 下午12:38写道:
|
|
|
Just echo what Lu mentioned, is there documentation we can find
more info on
For now, we only see checkpoint timeout due to a task can't
finish in time in flink UI, seems limited to debug further. Chen
On 4/24/20 10:52 PM, Congxian Qiu
wrote:
|
Re: Debug Slowness in Async Checkpointing
|
|
Hi,
Yes, for example [1]. Most of the points that you mentioned are already visible in the UI and/or via metrics, just take a look at the subtask checkpoint stats.
That’s checkpoint trigger time.
In Flink < 1.11 this is implicitly visible via subtracting, sync, async and alignment times from end to end checkpoint times. In Flink 1.11+ [2] there is/will be an explicit new metric "checkpointStartDelayNanos” (visible in the UI as "Start Delay”) for that.
Yes, this alignment time.
Yes: Start - That’s start delay + alignment time, as checkpoint starts immediately after the alignment is completed. Complete - That’s end to end duration That’s end to end duration. One thing which is missing is: As currently that’s just part of async time. I’ve created a ticket to track this work [3], so let’s move discussion about this there. Piotrek [1] https://ci.apache.org/projects/flink/flink-docs-release-1.10/monitoring/checkpoint_monitoring.html
|
|
|
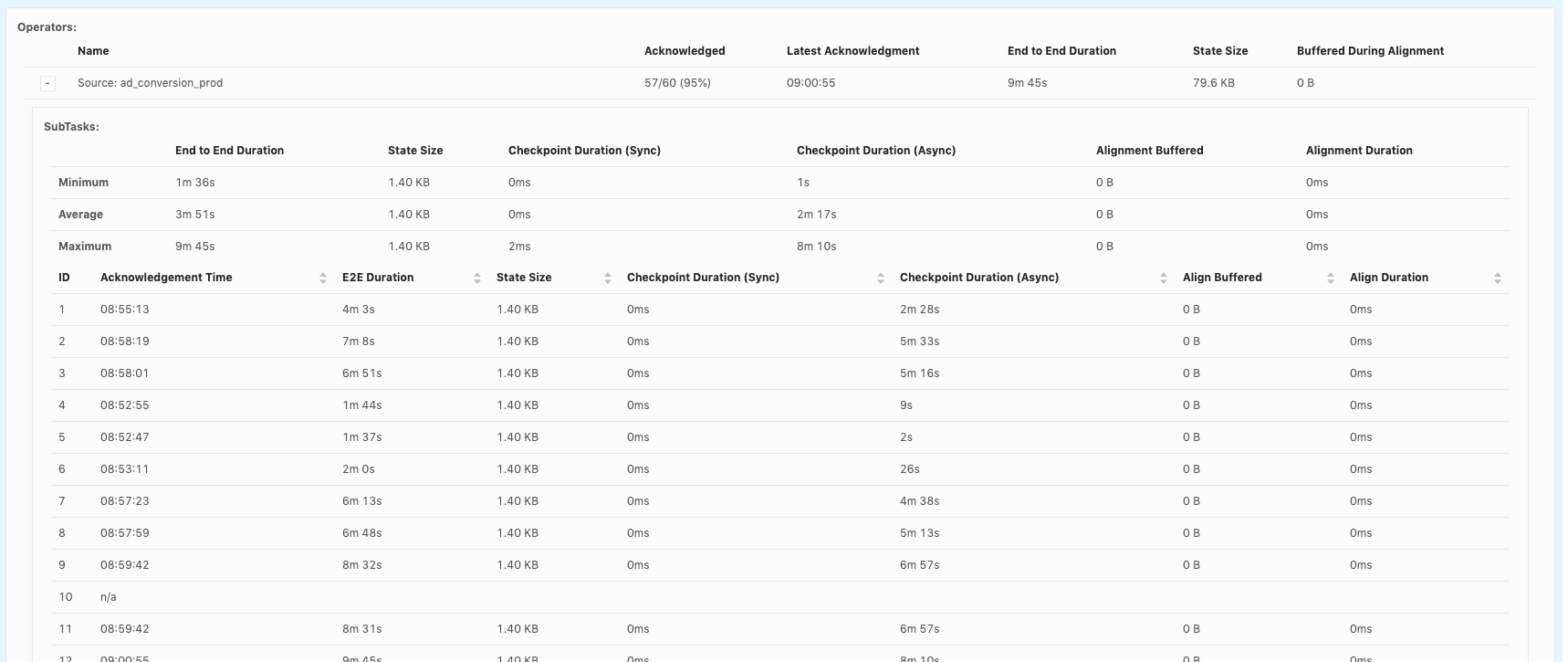
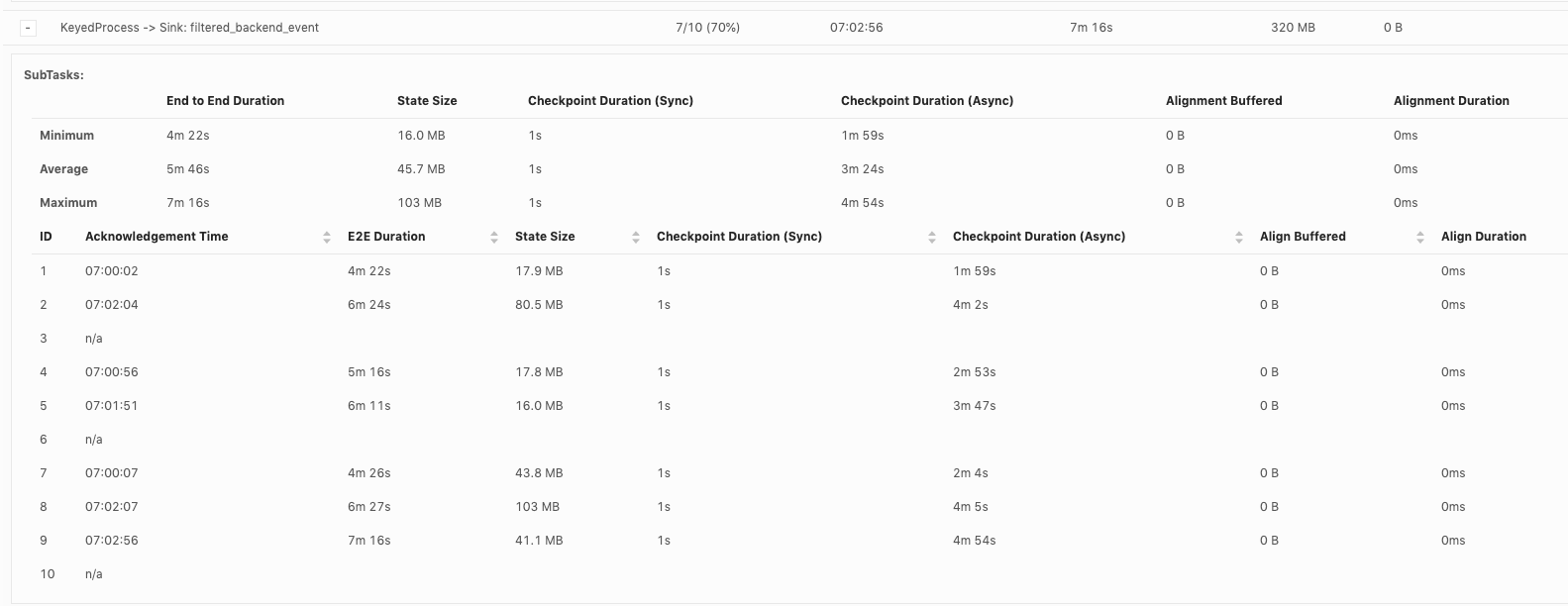
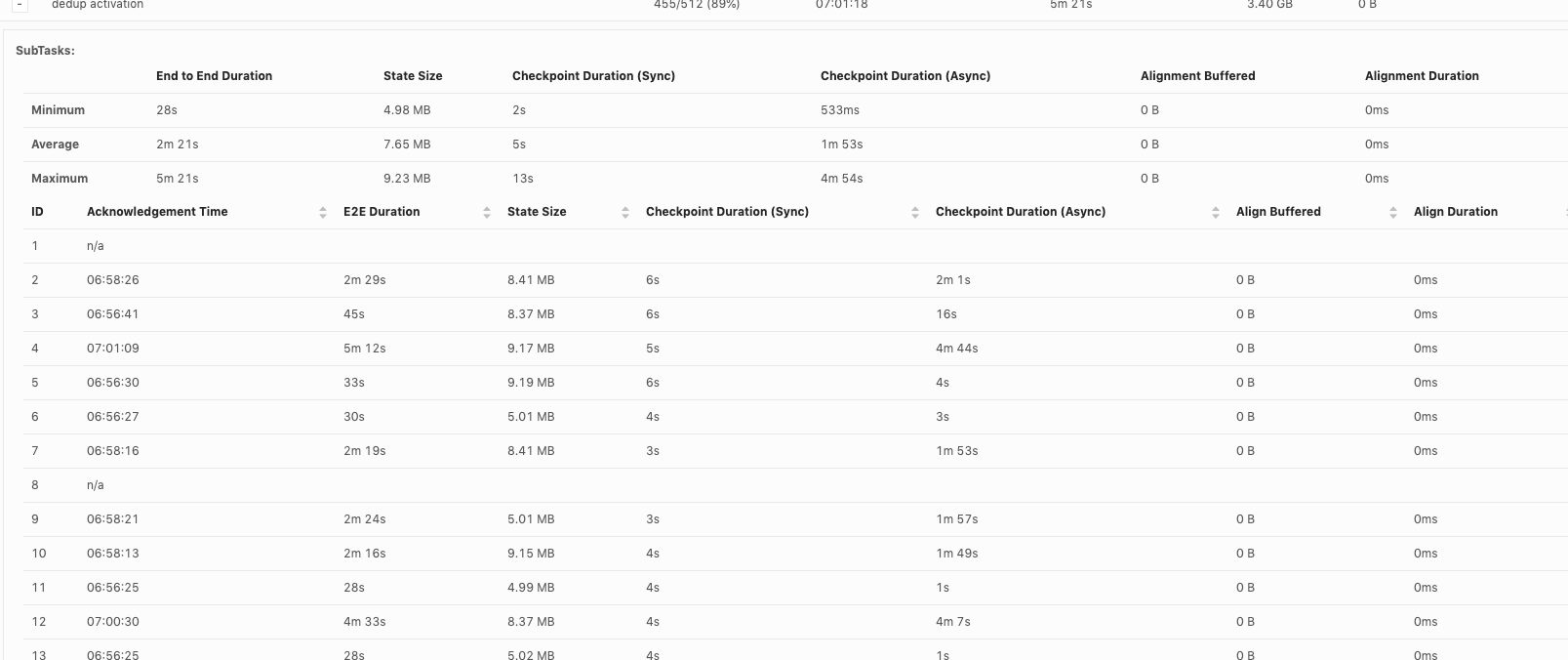
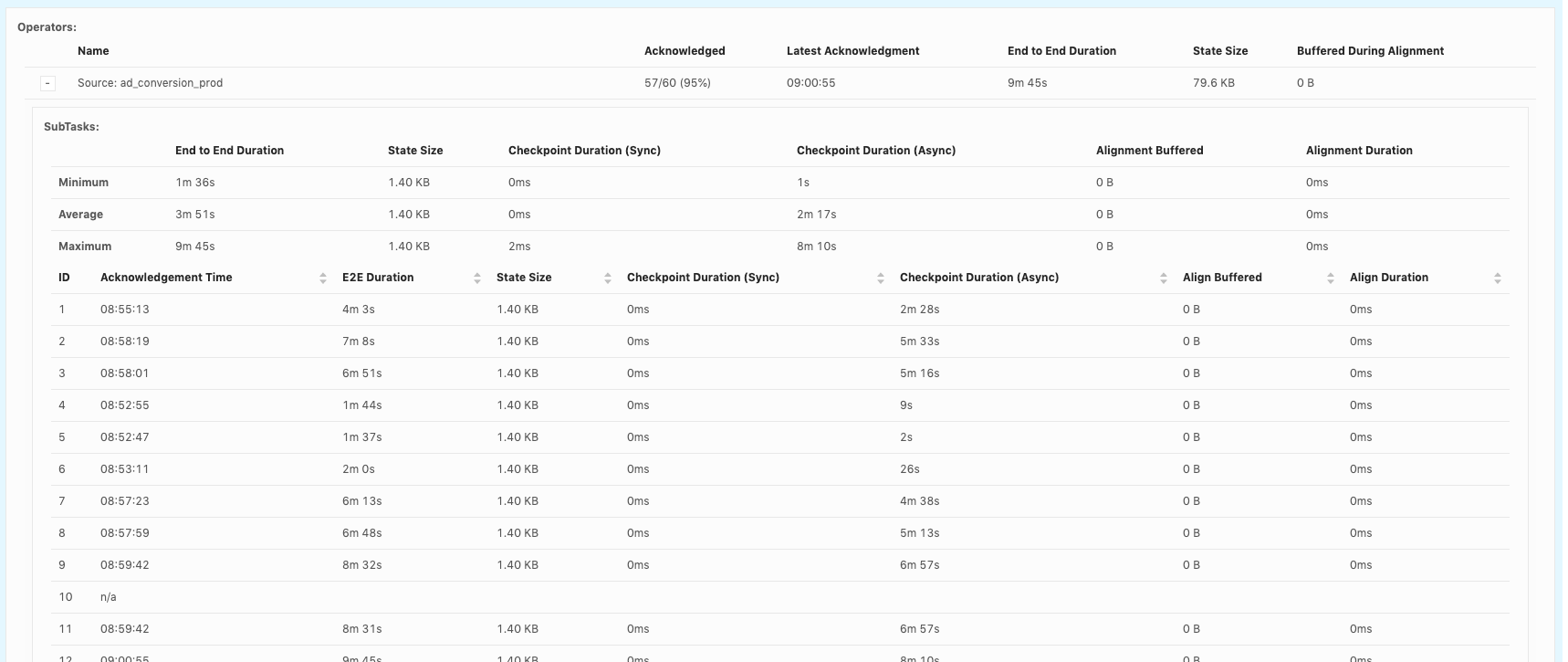
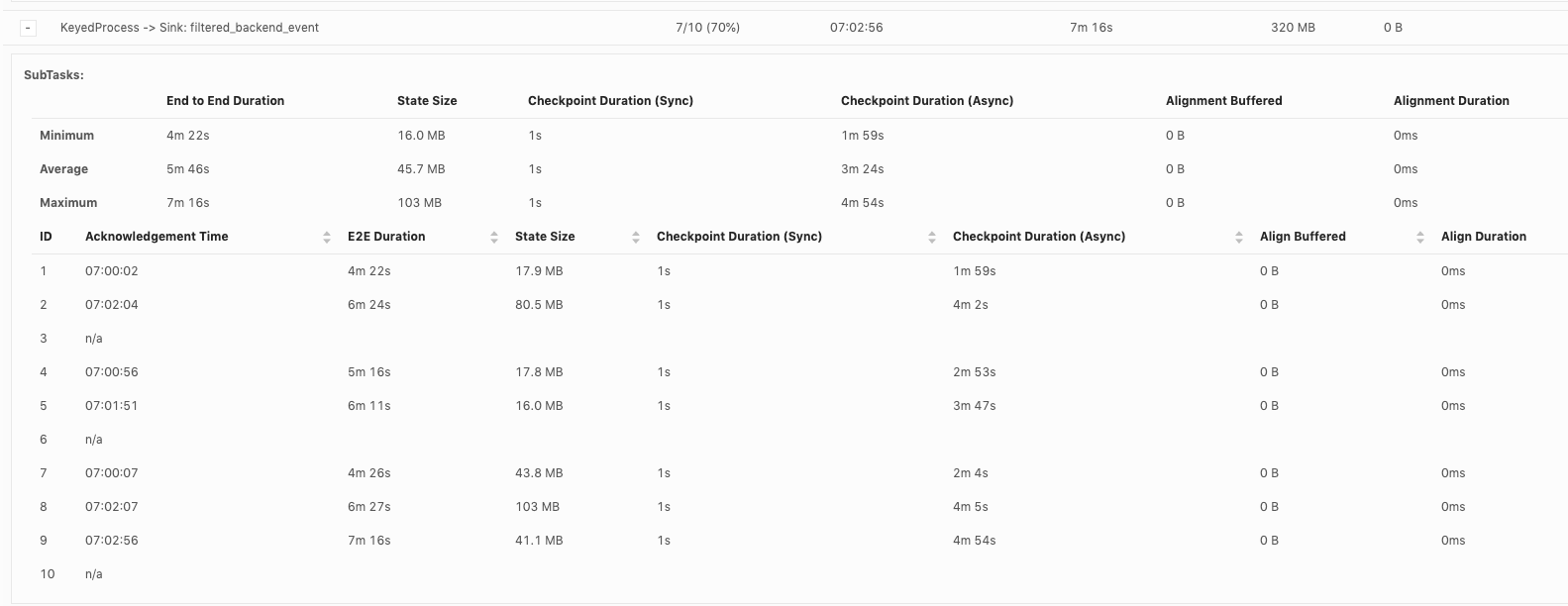
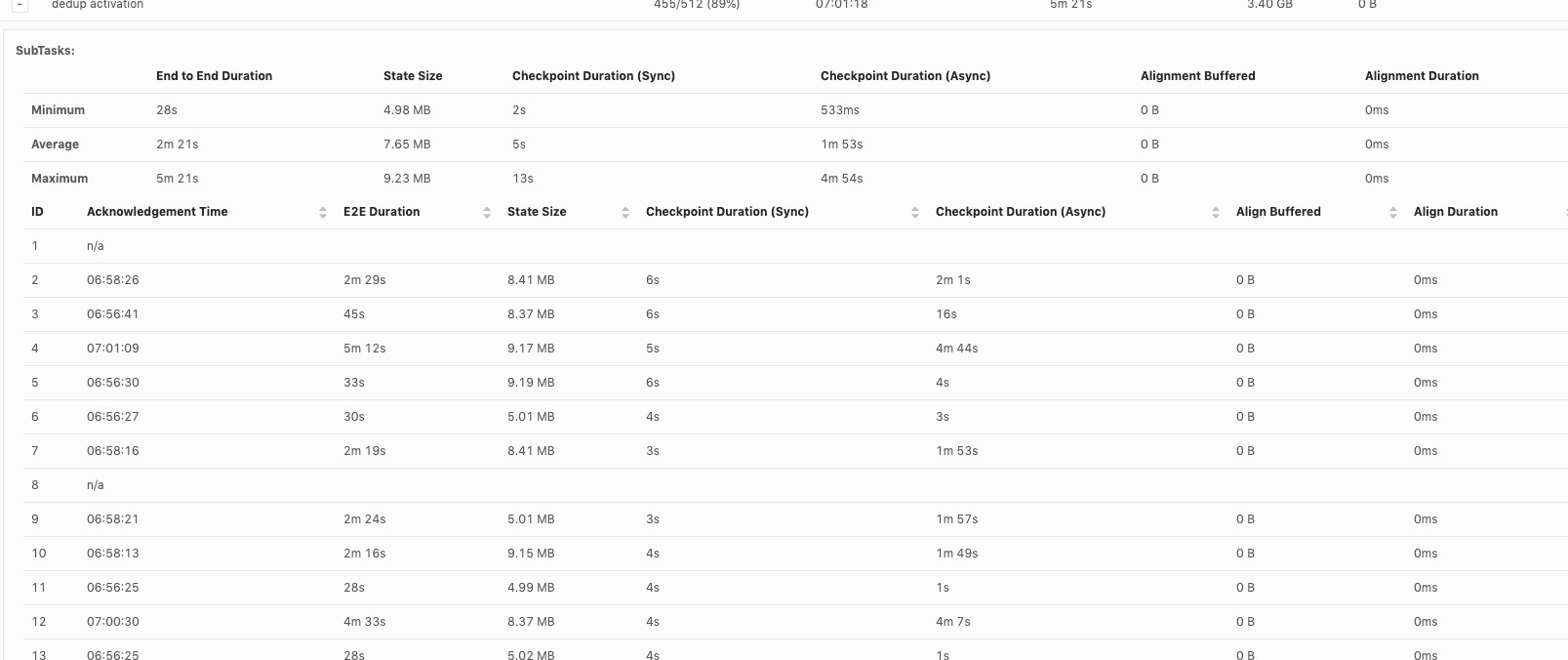
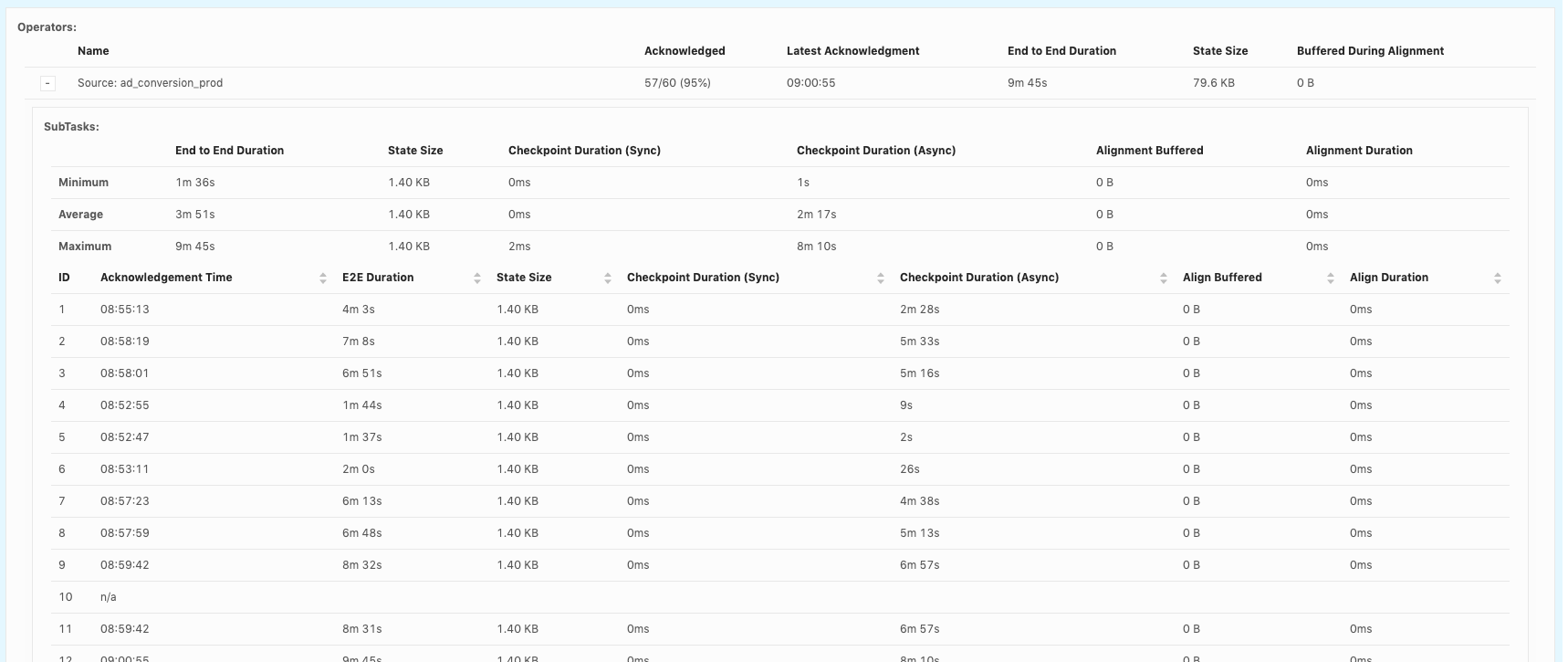
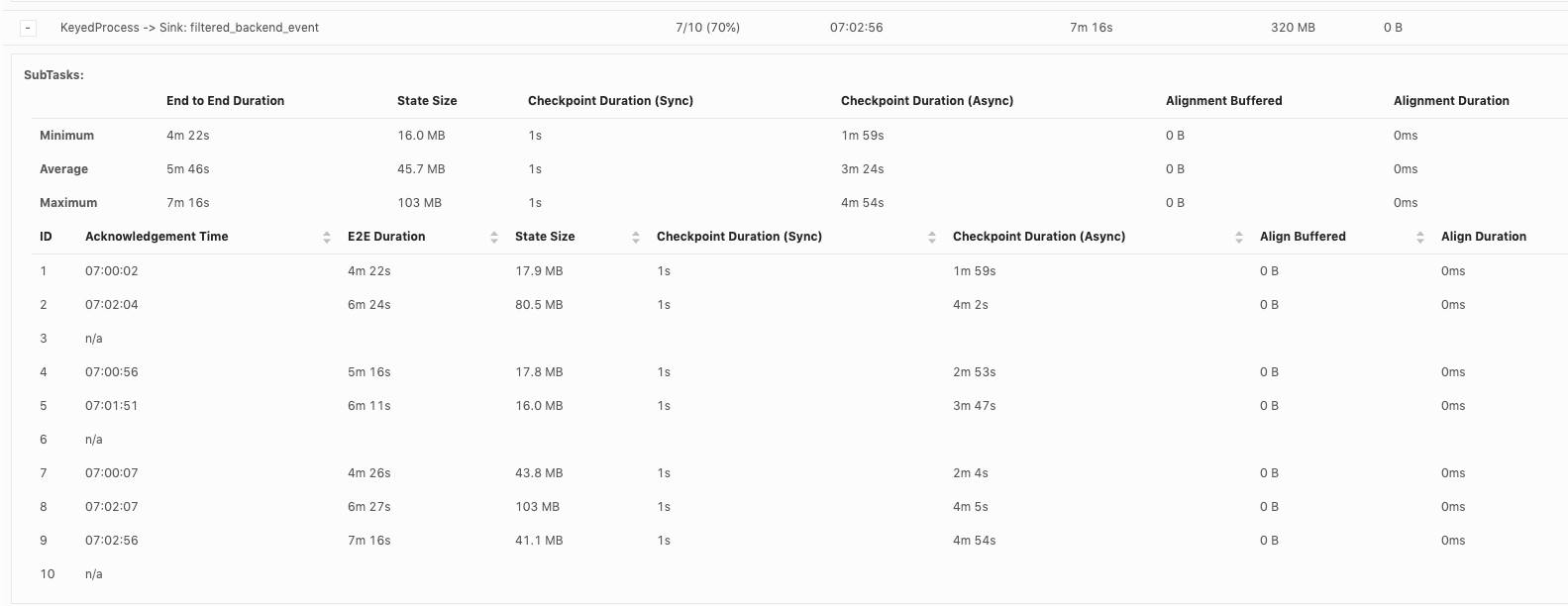
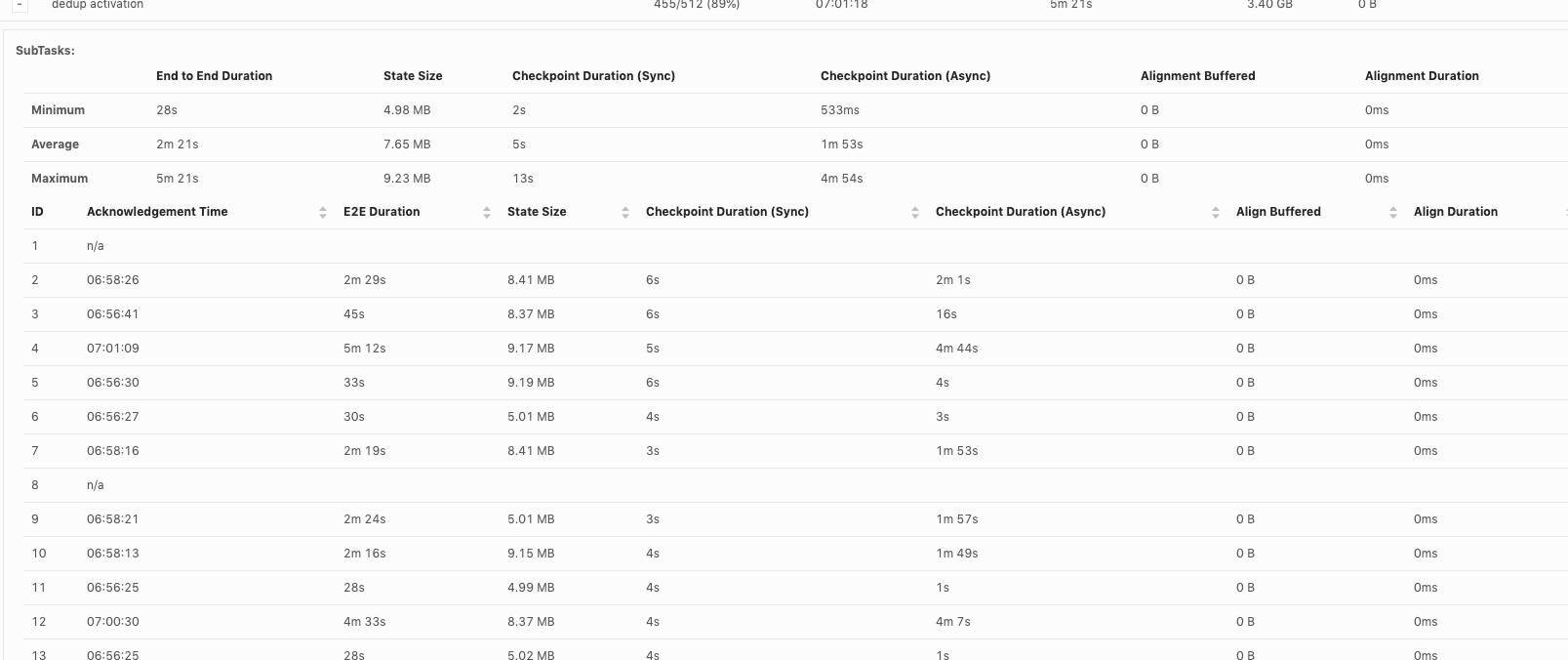
Hi, Piotr Thanks for checking! When our team debug checkpoint failures, I think we mainly hit 3 issues so far: 1. Which part contribute to slowness in async checkpoint and we've already covered it. I will follow up in https://issues.apache.org/jira/browse/FLINK-17468. 2. subtask checkpoint stats are not exposed through metrics system, making it hard to check metrics in history. 3. N/A status in subtask checkpointing, shown as below. This could happen in all the operators including source. 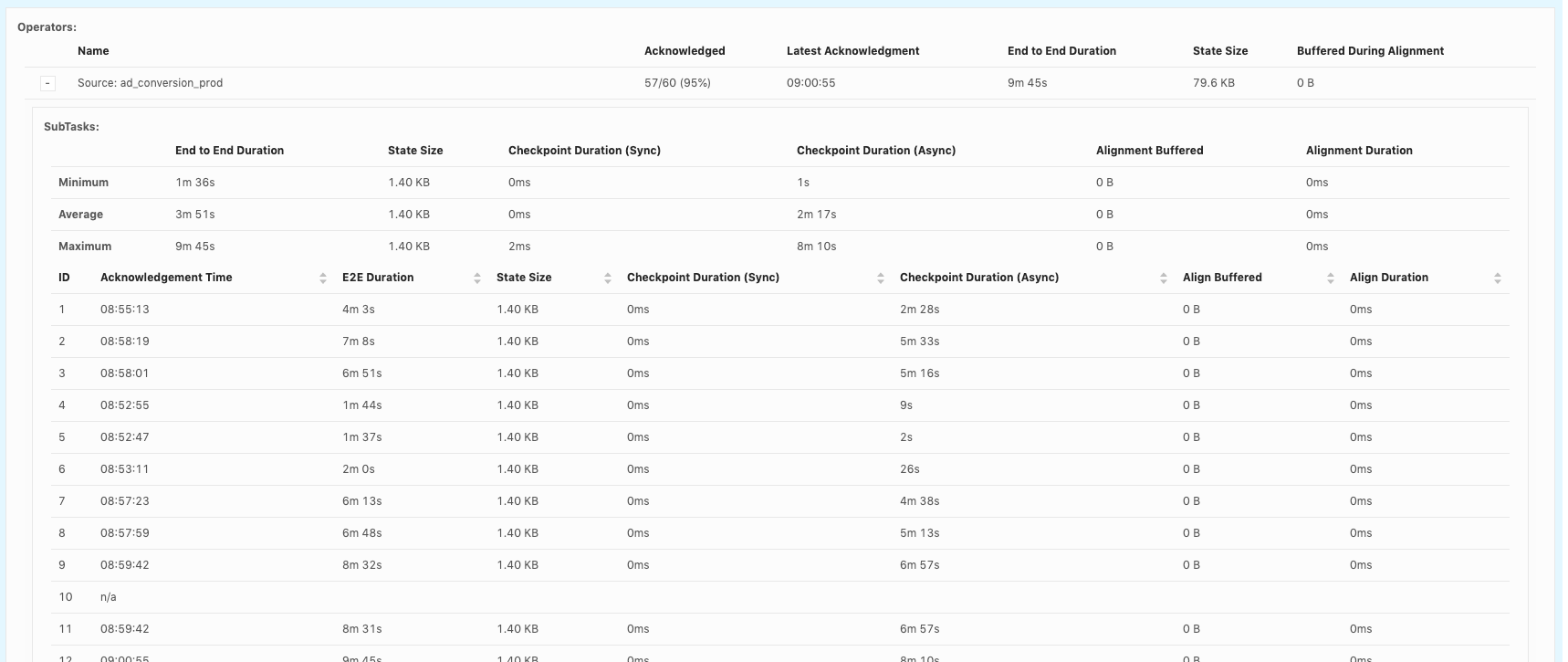 or 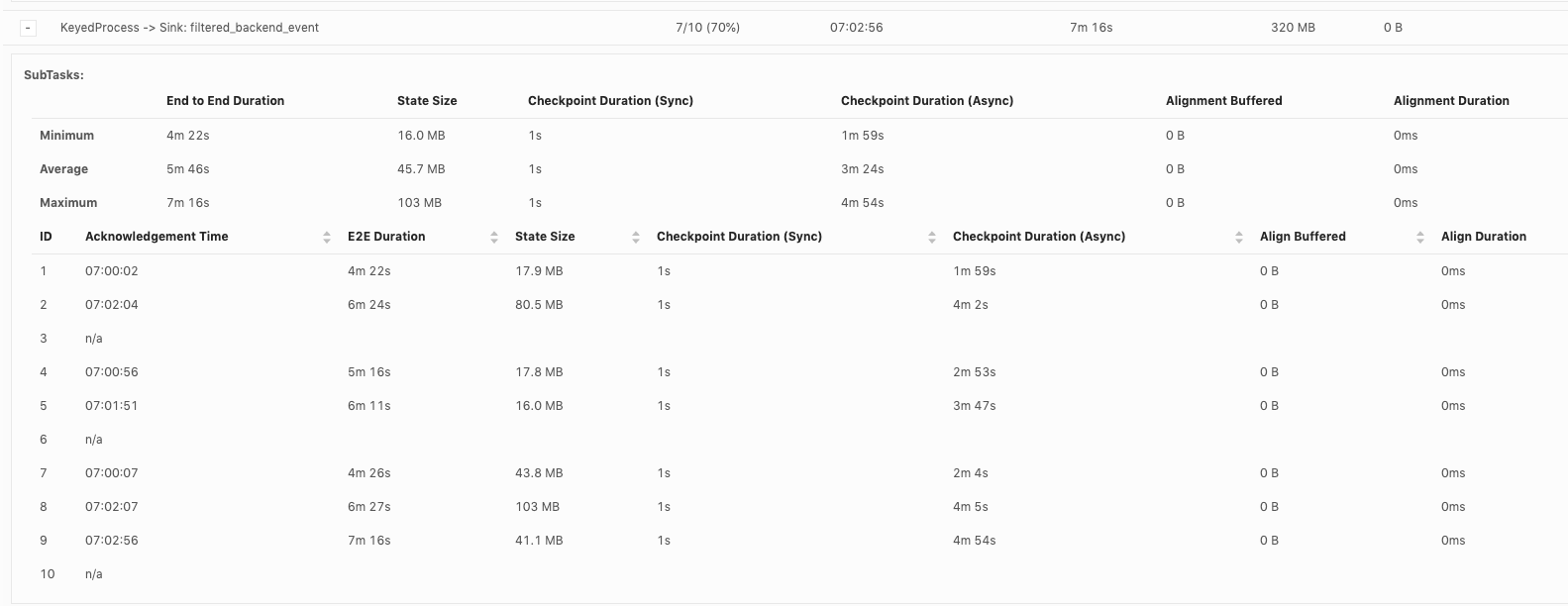 or 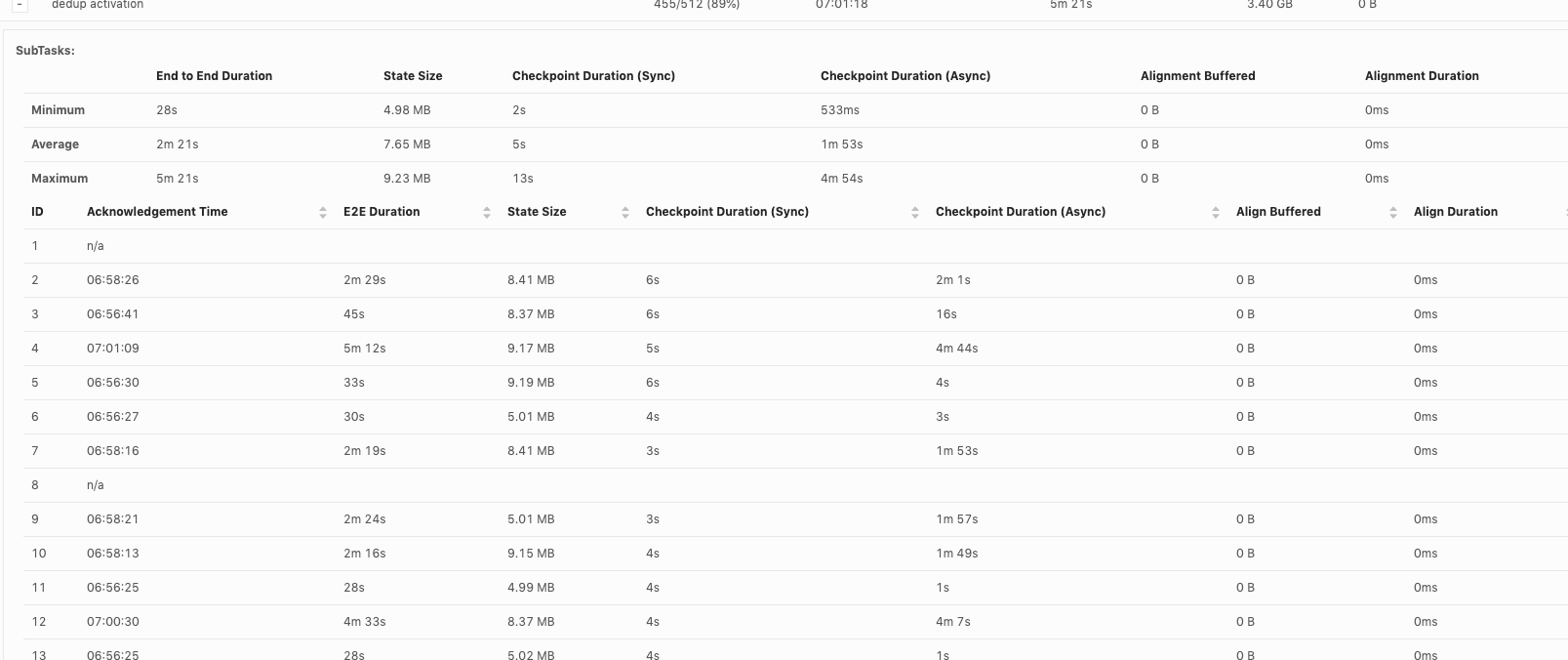 Could you share your insights on 2 and 3 as well? For 3, why subtask fails to report stats to JobManager? is there something we could improve? Thanks! Best Lu On Wed, Apr 29, 2020 at 8:50 AM Piotr Nowojski <[hidden email]> wrote:
|
Re: Debug Slowness in Async Checkpointing
|
|
2) What metrics would you have in mind?
We generally avoid exposing static data as metric (as in,
constantly exposing the stats for each subtask), but I could see
something like "lastCheckpointAcknowledgementTime" being feasible.
3) This likely means that the
checkpoint has failed.
On 29/04/2020 20:13, Lu Niu wrote:
|
|
|
Hi Lu
For issue-3, since you are using Flink-1.9.1, I think the main reason why source operator could not report checkpoint status within timeout duration is due to source operator cannot grab the lock [1]. Did you UDF stuck in your source?
Best
Yun Tang
From: Chesnay Schepler <[hidden email]>
Sent: Thursday, April 30, 2020 16:53 To: Lu Niu <[hidden email]>; Piotr Nowojski <[hidden email]> Cc: Chen Q <[hidden email]>; user <[hidden email]> Subject: Re: Debug Slowness in Async Checkpointing 2) What metrics would you have in mind? We generally avoid exposing static data as metric (as in, constantly exposing the stats for each subtask), but I could see something like "lastCheckpointAcknowledgementTime" being feasible.
3) This likely means that the checkpoint has failed.
On 29/04/2020 20:13, Lu Niu wrote:
|
|
|
Thanks for replying, Yun and Chesnay! I think in any cases subtasks should report failure even if it failed or timeout. Otherwise it just adds difficulty to debug. [hidden email] Thanks for the information. As this N/A happens across source, regular operator and sink, I didn't focus on failure on source only yet. I will check and let you know. Best Lu On Thu, Apr 30, 2020 at 2:05 AM Yun Tang <[hidden email]> wrote:
|
| Free forum by Nabble | Edit this page |