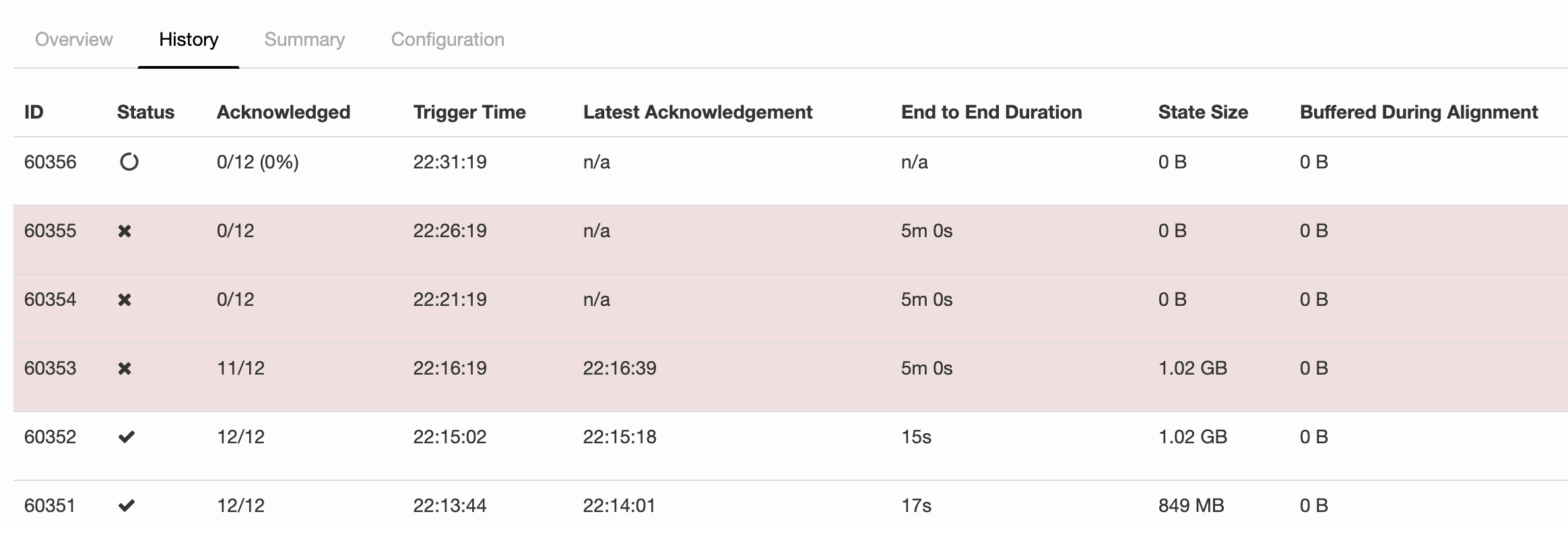
I've looked into this problem a little bit more. And it looks like the
problem is caused by some problem with Kinesis sink. There is an exception
in the logs at the moment in time when the job gets restored after being
stalled for about 15 minutes:
Encountered an unexpected expired iterator
AAAAAAAAAAGzsd7J/muyVo6McROAzdW+UByN+g4ttJjFS/LkswyZHprdlBxsH6B7UI/8DIJu6hj/Vph9OQ6Oz7Rhxg9Dj64w58osOSwf05lX/N+c8EUVRIQY/yZnwjtlmZw1HAKWSBIblfkGIMmmWFPu/UpQqzX7RliA2XWeDvkLAdOcogGmRgceI95rOMEUIWYP7z2PmiQ7TlL4MOG+q/NYEiLgyuoVw7bkm+igE+34caD7peXuZA==
for shard StreamShardHandle{streamName='staging-datalake-struct',
shard='{ShardId: shardId-000000000005,ParentShardId:
shardId-000000000001,HashKeyRange: {StartingHashKey:
255211775190703847597530955573826158592,EndingHashKey:
340282366920938463463374607431768211455},SequenceNumberRange:
{StartingSequenceNumber:
49591208977124932291714633368622679061889586376843722834,}}'}; refreshing
the iterator ...
It's logged by
org.apache.flink.streaming.connectors.kinesis.internals.ShardConsumer
--
Sent from:
http://apache-flink-user-mailing-list-archive.2336050.n4.nabble.com/