Checkpoints for kafka source sometimes get 55 GB size (instead of 2 MB) and flink job fails during restoring from such checkpoint

Checkpoints for kafka source sometimes get 55 GB size (instead of 2 MB) and flink job fails during restoring from such checkpoint

|
Hello, Sometime our flink job starts creating large checkpoints which include 55 Gb (instead of 2 MB) related to kafka source. After the flink job creates first “abnormal” checkpoint all next checkpoints are “abnormal”
as well. Flink job can’t be restored from such checkpoint. Restoring from the checkpoint hangs/fails. Also flnk dashboard hangs and flink cluster crashs during the restoring from such checkpoint. We didn’t catch related error message. Also we don’t find
clear way to reproduce this problem (when the flink job creates “abnormal” checkpoints).
Configuration: We are using flink 1.8.1 on emr (emr 5.27) Kafka: confluence kafka 5.4.1 Flink kafka connector: org.apache.flink:flink-connector-kafka_2.11:1.8.1 (it includes org.apache.kafka:kafka-clients:2.0.1 dependencies)
Our input kafka topic has 32 partitions and related flink source has 32 parallelism We use pretty much all default flink kafka concumer setting. We only specified: CommonClientConfigs.BOOTSTRAP_SERVERS_CONFIG, ConsumerConfig.GROUP_ID_CONFIG, CommonClientConfigs.SECURITY_PROTOCOL_CONFIG Thanks a lot in advance! Oleg |
Re: Checkpoints for kafka source sometimes get 55 GB size (instead of 2 MB) and flink job fails during restoring from such checkpoint
|
|
Hi Oleg,
this sounds indeed like abnormal behavior. Are you sure that these large checkpoints are related to the Kafka consumer only? Are there other operators in the pipeline? Because internally the state kept in a Kafka consumer is pretty minimal and only related to Kafka partition and offset management. If you are sure that the Kafka consumer must produce such a state size, I would recommend to use a remote debugger and check what is checkpointed in the corresponding `FlinkKafkaConsumerBase#snapshotState`. Regards, Timo On 15.04.20 03:37, Oleg Vysotsky wrote: > Hello, > > Sometime our flink job starts creating large checkpoints which include > 55 Gb (instead of 2 MB) related to kafka source. After the flink job > creates first “abnormal” checkpoint all next checkpoints are “abnormal” > as well. Flink job can’t be restored from such checkpoint. Restoring > from the checkpoint hangs/fails. Also flnk dashboard hangs and flink > cluster crashs during the restoring from such checkpoint. We didn’t > catch related error message. Also we don’t find clear way to reproduce > this problem (when the flink job creates “abnormal” checkpoints). > > Configuration: > > We are using flink 1.8.1 on emr (emr 5.27) > > Kafka: confluence kafka 5.4.1 > > Flink kafka connector: > org.apache.flink:flink-connector-kafka_2.11:1.8.1 (it includes > org.apache.kafka:kafka-clients:2.0.1 dependencies) > > Our input kafka topic has 32 partitions and related flink source has 32 > parallelism > > We use pretty much all default flink kafka concumer setting. We only > specified: > > CommonClientConfigs.BOOTSTRAP_SERVERS_CONFIG, > > ConsumerConfig.GROUP_ID_CONFIG, > > CommonClientConfigs.SECURITY_PROTOCOL_CONFIG > > Thanks a lot in advance! > > Oleg > |
Re: Checkpoints for kafka source sometimes get 55 GB size (instead of 2 MB) and flink job fails during restoring from such checkpoint
|
|
Hi Timo,
Thank you for the suggestion! Last two days I tried to find the clear way to reproduce the problem and to define the root cause. The problem with "abnormal" checkpoints happened only on our largest flink job (which processes 6k-10k events per second). Similar smallerjobs (same code) don't have this problem. E.g. the similar job which processes about 3 times less events don't have this problem. As a result, remote debugging is quite challenging. Instead of debugging I added logging to FlinkKafkaConsumerBase#snapshotState and set commitOffsetsOnCheckpoints to false to disable "additional" logic in FlinkKafkaConsumerBase#snapshotState (please check my temp "log" changes below). The logging was as expected like {"lvl":"WARN","msg":"snapshotState fetcher: partition: KafkaTopicPartition{topic\u003d\u0027dsp-producer-z-clickstream-web-raw\u0027, partition\u003d2} offset:1091528771\n"} I didn't find any example of large entry added to "unionOffsetStates" Looks like the problem is that the flink job periodically (not often) creates continues set of "bad" checkpoints, which have reasonable "checkpoint" size for each operator. After restoring from such "bad" checkpoint the flink job starts creating "abnormal" checkpoint which includes 55 Gb for kafka source operator (please check the attachments, "Source: dsp-producer-z-clickstream-raw" is kafka source). Creating "abnormal" checkpoint is 100% reproducible in this case. Just in case, we just switched to use kafka source instead of kinesis source. We have the same job with kinesis for 1+ year and didn't have this problem. Any advices are appreciated. @Override public final void snapshotState(FunctionSnapshotContext context) throws Exception { if (!running) { LOG.debug("snapshotState() called on closed source"); } else { unionOffsetStates.clear(); final AbstractFetcher<?, ?> fetcher = this.kafkaFetcher; StringBuilder sb = new StringBuilder("snapshotState "); if (fetcher == null) { sb.append("null fetcher: "); // the fetcher has not yet been initialized, which means we need to return the // originally restored offsets or the assigned partitions for (Map.Entry<KafkaTopicPartition, Long> subscribedPartition : subscribedPartitionsToStartOffsets.entrySet()) { unionOffsetStates.add(Tuple2.of(subscribedPartition.getKey(), subscribedPartition.getValue())); sb.append("partition: ").append(subscribedPartition.getKey()).append(" offset:").append(subscribedPartition.getValue()).append('\n'); } if (offsetCommitMode == OffsetCommitMode.ON_CHECKPOINTS) { // the map cannot be asynchronously updated, because only one checkpoint call can happen // on this function at a time: either snapshotState() or notifyCheckpointComplete() pendingOffsetsToCommit.put(context.getCheckpointId(), restoredState); } } else { HashMap<KafkaTopicPartition, Long> currentOffsets = fetcher.snapshotCurrentState(); if (offsetCommitMode == OffsetCommitMode.ON_CHECKPOINTS) { // the map cannot be asynchronously updated, because only one checkpoint call can happen // on this function at a time: either snapshotState() or notifyCheckpointComplete() pendingOffsetsToCommit.put(context.getCheckpointId(), currentOffsets); } sb.append("fetcher: "); for (Map.Entry<KafkaTopicPartition, Long> kafkaTopicPartitionLongEntry : currentOffsets.entrySet()) { unionOffsetStates.add( Tuple2.of(kafkaTopicPartitionLongEntry.getKey(), kafkaTopicPartitionLongEntry.getValue())); sb.append("partition: ").append(kafkaTopicPartitionLongEntry.getKey()).append(" offset:").append(kafkaTopicPartitionLongEntry.getValue()).append('\n'); } } if (offsetCommitMode == OffsetCommitMode.ON_CHECKPOINTS) { // truncate the map of pending offsets to commit, to prevent infinite growth while (pendingOffsetsToCommit.size() > MAX_NUM_PENDING_CHECKPOINTS) { pendingOffsetsToCommit.remove(0); } } LOG.warn(sb.toString()); } } On 4/14/20, 11:44 PM, "Timo Walther" <[hidden email]> wrote: Hi Oleg, this sounds indeed like abnormal behavior. Are you sure that these large checkpoints are related to the Kafka consumer only? Are there other operators in the pipeline? Because internally the state kept in a Kafka consumer is pretty minimal and only related to Kafka partition and offset management. If you are sure that the Kafka consumer must produce such a state size, I would recommend to use a remote debugger and check what is checkpointed in the corresponding `FlinkKafkaConsumerBase#snapshotState`. Regards, Timo On 15.04.20 03:37, Oleg Vysotsky wrote: > Hello, > > Sometime our flink job starts creating large checkpoints which include > 55 Gb (instead of 2 MB) related to kafka source. After the flink job > creates first “abnormal” checkpoint all next checkpoints are “abnormal” > as well. Flink job can’t be restored from such checkpoint. Restoring > from the checkpoint hangs/fails. Also flnk dashboard hangs and flink > cluster crashs during the restoring from such checkpoint. We didn’t > catch related error message. Also we don’t find clear way to reproduce > this problem (when the flink job creates “abnormal” checkpoints). > > Configuration: > > We are using flink 1.8.1 on emr (emr 5.27) > > Kafka: confluence kafka 5.4.1 > > Flink kafka connector: > org.apache.flink:flink-connector-kafka_2.11:1.8.1 (it includes > org.apache.kafka:kafka-clients:2.0.1 dependencies) > > Our input kafka topic has 32 partitions and related flink source has 32 > parallelism > > We use pretty much all default flink kafka concumer setting. We only > specified: > > CommonClientConfigs.BOOTSTRAP_SERVERS_CONFIG, > > ConsumerConfig.GROUP_ID_CONFIG, > > CommonClientConfigs.SECURITY_PROTOCOL_CONFIG > > Thanks a lot in advance! > > Oleg > |
Re: Checkpoints for kafka source sometimes get 55 GB size (instead of 2 MB) and flink job fails during restoring from such checkpoint
|
|
This sounds a lot like an issue I just went through (http://apache-flink-user-mailing-list-archive.2336050.n4.nabble.com/Very-large-metadata-file-td33356.html). Are you using a union list state anywhere? You could also use the debugging steps mentioned in that thread to inspect the contents of the bad checkpoint. On Fri, Apr 17, 2020 at 4:46 PM Oleg Vysotsky <[hidden email]> wrote: Hi Timo, Jacob Sevart Software Engineer, Safety |
|
|
Hi Oleg
If your can only view the log of "snapshotState fetcher: partition: KafkaTopicPartition{topic\u003d\u0027dsp-producer-z-clickstream-web-raw\u0027, partition\u003d2} offset:1091528771\n"
when the checkpoint of that subtask has reached to 1GB+. This is really weird, as the state in unionOffsetStates should be only one record.
Please follow the thread Jacob mentioned, use
Checkpoints.loadCheckpointMetadata to load the _metadata to see how many records in the offsets meta. BTW, could you also share the code of how to create the "dsp-producer-z-clickstream-web-raw"
source?
Best
Yun Tang
From: Jacob Sevart <[hidden email]>
Sent: Saturday, April 18, 2020 9:22 To: Oleg Vysotsky <[hidden email]> Cc: Timo Walther <[hidden email]>; [hidden email] <[hidden email]>; Long Nguyen <[hidden email]> Subject: Re: Checkpoints for kafka source sometimes get 55 GB size (instead of 2 MB) and flink job fails during restoring from such checkpoint This sounds a lot like an issue I just went through (http://apache-flink-user-mailing-list-archive.2336050.n4.nabble.com/Very-large-metadata-file-td33356.html).
Are you using a union list state anywhere?
You could also use the debugging steps mentioned in that thread to inspect the contents of the bad checkpoint.
On Fri, Apr 17, 2020 at 4:46 PM Oleg Vysotsky <[hidden email]> wrote:
Hi Timo, Jacob Sevart
Software Engineer, Safety
|
Re: Checkpoints for kafka source sometimes get 55 GB size (instead of 2 MB) and flink job fails during restoring from such checkpoint
|
|
In reply to this post by Jacob Sevart
Hi Jacob & Timo, Thank you for checking! I don’t use union list state in my app. FlinkKafkaConsumerBase (from kafka connector) uses it to store offsets per partition, but partitions are small (input topic has 32 partitions). The metadata file is large (about 1.5 Gb) in case of
“abnormal” checkpoint. Usual checkpoints have metadata file around 180-190 Mb. I use MemoryStateBackend with state.backend.fs.memory-threshold = 1024000.
In one of my experiment I modified FlinkKafkaConsumerBase to disable initializing states in FlinkKafkaConsumerBase#initializeState and disabled saving states in FlinkKafkaConsumerBase#snapshotState. I also force “ to use the partition
discoverer to fetch the initial seed partitions” by changing FlinkKafkaConsumerBase#open method (please check the code below). The problem is still there: when I restore from “bad” checkpoint the flink job creates “abnormal” checkpoints with 55 Gb associated
to kafka source. Looks like flink stores not only data related to partition offsets in checkpoint which are associated with kafka source. Any idea? Looks like the problem does relate to kafka source. E.g. switching source from kafka to kinesis and back temporary fix the problem: If I restore flink job from "bad" checkpoint (which creates the problem: not "abnormal" checkpoint) with switching from kafka to kinesis input (which has identical data). After "restored" flink job creates flrst checkpoint I cancel and
restore the flink job from “new” checkpoint with kafka input from specific timestamp. The flink job creates correct checkpoints.
Just in case, I attached two “snapshots” from flink ui with example of abnormal checkpoint. Thanks a lot! Oleg @Override @Override @Override From: Jacob Sevart <[hidden email]> This sounds a lot like an issue I just went through (http://apache-flink-user-mailing-list-archive.2336050.n4.nabble.com/Very-large-metadata-file-td33356.html).
Are you using a union list state anywhere? You could also use the debugging steps mentioned in that thread to inspect the contents of the bad checkpoint. On Fri, Apr 17, 2020 at 4:46 PM Oleg Vysotsky <[hidden email]> wrote:
-- Jacob Sevart Software Engineer, Safety |
|
|
Hi Oleg
Have you ever checked to load the _metadata via
Checkpoints.loadCheckpointMetadata
to see how many records in the offsets meta? If only one record which is indicated from the logs, that will be really weird.
Moreover, I have several comments based on your description:
Yun Tang
From: Oleg Vysotsky <[hidden email]>
Sent: Tuesday, April 21, 2020 6:45 To: Jacob Sevart <[hidden email]>; Timo Walther <[hidden email]>; [hidden email] <[hidden email]> Cc: Long Nguyen <[hidden email]>; Gurpreet Singh <[hidden email]> Subject: Re: Checkpoints for kafka source sometimes get 55 GB size (instead of 2 MB) and flink job fails during restoring from such checkpoint Hi Jacob & Timo, Thank you for checking!
I don’t use union list state in my app. FlinkKafkaConsumerBase (from kafka connector) uses it to store offsets per partition, but partitions are small (input topic has 32 partitions). The metadata file is large (about 1.5 Gb) in case of “abnormal” checkpoint. Usual checkpoints have metadata file around 180-190 Mb. I use MemoryStateBackend with state.backend.fs.memory-threshold = 1024000.
In one of my experiment I modified FlinkKafkaConsumerBase to disable initializing states in FlinkKafkaConsumerBase#initializeState and disabled saving states in FlinkKafkaConsumerBase#snapshotState. I also force “ to use the partition discoverer to fetch the initial seed partitions” by changing FlinkKafkaConsumerBase#open method (please check the code below). The problem is still there: when I restore from “bad” checkpoint the flink job creates “abnormal” checkpoints with 55 Gb associated to kafka source. Looks like flink stores not only data related to partition offsets in checkpoint which are associated with kafka source. Any idea?
Looks like the problem does relate to kafka source. E.g. switching source from kafka to kinesis and back temporary fix the problem: If I restore flink job from "bad" checkpoint (which creates the problem: not "abnormal" checkpoint) with switching from kafka to kinesis input (which has identical data). After "restored" flink job creates flrst checkpoint I cancel and restore the flink job from “new” checkpoint with kafka input from specific timestamp. The flink job creates correct checkpoints.
Just in case, I attached two “snapshots” from flink ui with example of abnormal checkpoint.
Thanks a lot! Oleg
@Override
@Override
@Override
From:
Jacob Sevart <[hidden email]>
This sounds a lot like an issue I just went through (http://apache-flink-user-mailing-list-archive.2336050.n4.nabble.com/Very-large-metadata-file-td33356.html). Are you using a union list state anywhere?
You could also use the debugging steps mentioned in that thread to inspect the contents of the bad checkpoint.
On Fri, Apr 17, 2020 at 4:46 PM Oleg Vysotsky <[hidden email]> wrote:
-- Jacob Sevart Software Engineer, Safety |
Re: Checkpoints for kafka source sometimes get 55 GB size (instead of 2 MB) and flink job fails during restoring from such checkpoint
|
|
Hi Yun, Thank you for the advices and thank you for pointing to Checkpoints.loadCheckpointMetadata!
{Integer@1999} 0 -> {OperatorSubtaskState@2000} "SubtaskState{operatorStateFromBackend=StateObjectCollection{[OperatorStateHandle{stateNameToPartitionOffsets={Kinesis-Stream-Shard-State=StateMetaInfo{offsets=[4589,
4872, 5156, 5438, 5722, 6006, 6288, 6572, 6854, 7138, 7422, 7706, 7988, 8272, 8554, 8838, 9121, 9404, 9686, 9968, 10252, 10536, 10820, 11104, 11388, 11632, 11916, 12200, 12481, 12765, 13049, 13331, 13615, 13899, 14183, 14465, 14747, 15031, 15315, 15597, 15879,
16163, 16447, 16731, 17015, 17299, 17581, 17865, 18149, 18433, 18715, 18999, 19283, 19567, 19849, 20133, 20415, 20697, 20981, 21265, 21549, 21833, 22117, 22401, 22681, 22965, 23248, 23532, 23814, 24098, 24382, 24666, 24948, 25232, 25516, 25796, 26078, 26360,
26644, 26928, 27212, 27496, 27780, 28064, 28347, 28631, 28913, 29197, 29479, 29762, 30046, 30329, 30613, 30897, 31181, 31463, 31745, 32029, 32313, 32597, 32881, 33163, 33447, 33731, 34015, 34297, 34581, 34863, 35147, 35431, 35715, 35999, 36281, 36563, 36847,
37131, 37413, 37696, 37980, 38262, 38546, 38830, 39112," When I start job from scratch there is no ref to kinesis (which is expected): {Integer@1999} 0 -> {OperatorSubtaskState@2000} "SubtaskState{operatorStateFromBackend=StateObjectCollection{[OperatorStateHandle{stateNameToPartitionOffsets={_default_=StateMetaInfo{offsets=[], distributionMode=SPLIT_DISTRIBUTE},
topic-partition-offset-states=StateMetaInfo{offsets=[1523], distributionMode=UNION}}, delegateStateHandle=ByteStreamStateHandle{handleName='file:/efs/zillow-analytics-prod/prod/emr/flink/checkpoints/e34050eb668e245d265776f869a022c6/chk-4/a4240c1e-ca5c-4393-ad42-a09cc5843152',
dataBytes=1574}}]}, operatorStateFromStream=StateObjectCollection{[]}, keyedStateFromBackend=StateObjectCollection{[]}, keyedStateFromStream=StateObjectCollection{[]}, stateSize=1574}"
topicConfig: cleanup.policy: "delete" retention.ms: 604800000 retention.bytes: 5000000000 partitions: 32 replicationFactor: 3 Thanks a lot! Oleg From: Yun Tang <[hidden email]> Hi Oleg Have you ever checked to load the _metadata via
Checkpoints.loadCheckpointMetadata to see how many records in the offsets meta? If only one record which is indicated from the logs, that will be really weird. Moreover, I have several comments based on your description:
Best Yun Tang From: Oleg Vysotsky <[hidden email]> Hi Jacob & Timo, Thank you for checking! I don’t use union list state in my app. FlinkKafkaConsumerBase (from kafka connector) uses it to store offsets per partition, but partitions are small (input topic has 32 partitions). The metadata file is large (about 1.5 Gb) in case of
“abnormal” checkpoint. Usual checkpoints have metadata file around 180-190 Mb. I use MemoryStateBackend with state.backend.fs.memory-threshold = 1024000.
In one of my experiment I modified FlinkKafkaConsumerBase to disable initializing states in FlinkKafkaConsumerBase#initializeState and disabled saving states in FlinkKafkaConsumerBase#snapshotState. I also force “ to use the partition
discoverer to fetch the initial seed partitions” by changing FlinkKafkaConsumerBase#open method (please check the code below). The problem is still there: when I restore from “bad” checkpoint the flink job creates “abnormal” checkpoints with 55 Gb associated
to kafka source. Looks like flink stores not only data related to partition offsets in checkpoint which are associated with kafka source. Any idea? Looks like the problem does relate to kafka source. E.g. switching source from kafka to kinesis and back temporary fix the problem: If I restore flink job from "bad" checkpoint (which creates the problem: not "abnormal" checkpoint) with switching from kafka to kinesis input (which has identical data). After "restored" flink job creates flrst checkpoint I cancel and
restore the flink job from “new” checkpoint with kafka input from specific timestamp. The flink job creates correct checkpoints.
Just in case, I attached two “snapshots” from flink ui with example of abnormal checkpoint. Thanks a lot! Oleg @Override @Override @Override From:
Jacob Sevart <[hidden email]> This sounds a lot like an issue I just went through (http://apache-flink-user-mailing-list-archive.2336050.n4.nabble.com/Very-large-metadata-file-td33356.html).
Are you using a union list state anywhere? You could also use the debugging steps mentioned in that thread to inspect the contents of the bad checkpoint. On Fri, Apr 17, 2020 at 4:46 PM Oleg Vysotsky <[hidden email]> wrote:
-- Jacob Sevart Software Engineer, Safety |
|
|
Hi Oleg
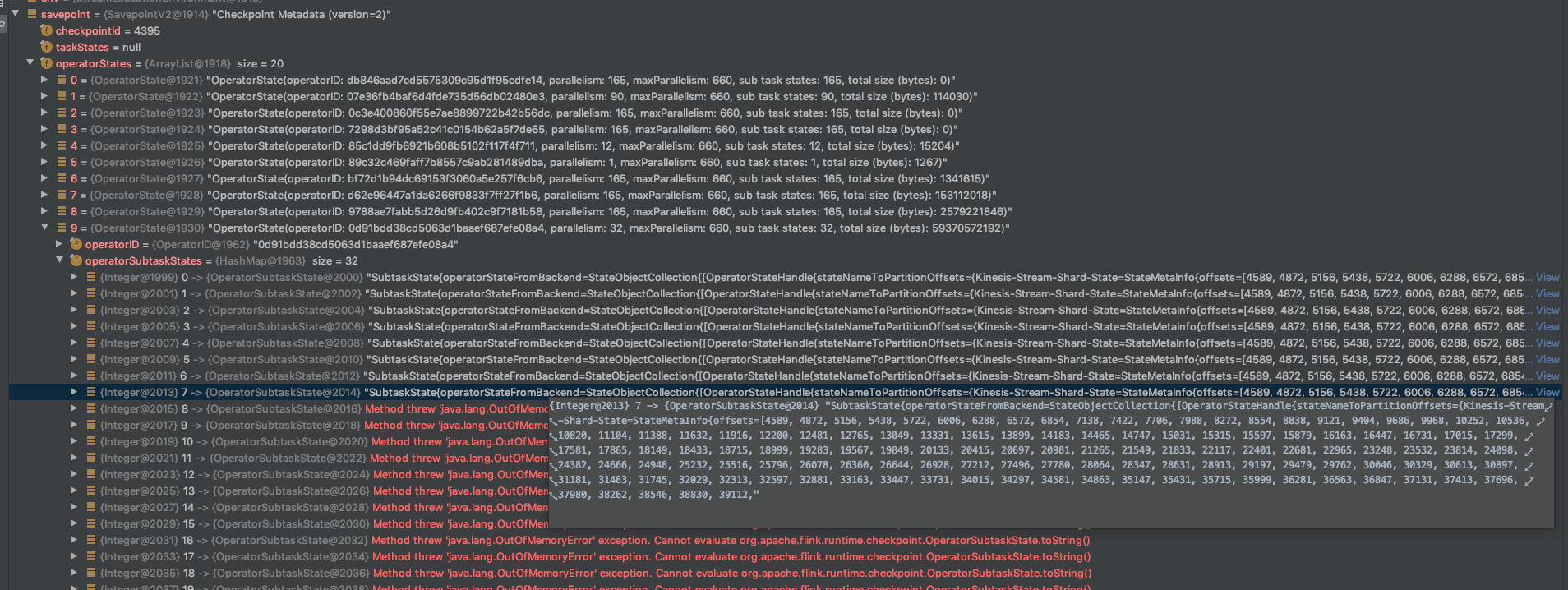
If the "stateNameToPartitionOffsets" in abnormal checkpoints (sub state > 1GB) is "Kinesis-Stream-Shard-State" [1] instead of "topic-partition-offset-states"
[2], I doubt all your descriptions. The _metadata tells us that it is generated from kniesis instead of kafka, and the offsets recorded [3] indicate the state handle size should be near to 39112 bytes.
If that is the real abnormal checkpoint, and the source operator state offset recorded should be larger than 1073741824, please check the _metadata again to know the facts.
Best
Yun Tang
From: Oleg Vysotsky <[hidden email]>
Sent: Tuesday, April 21, 2020 13:53 To: Yun Tang <[hidden email]>; Jacob Sevart <[hidden email]>; Timo Walther <[hidden email]>; [hidden email] <[hidden email]> Cc: Long Nguyen <[hidden email]>; Gurpreet Singh <[hidden email]> Subject: Re: Checkpoints for kafka source sometimes get 55 GB size (instead of 2 MB) and flink job fails during restoring from such checkpoint Hi Yun, Thank you for the advices and thank you for pointing to Checkpoints.loadCheckpointMetadata!
{Integer@1999} 0 -> {OperatorSubtaskState@2000} "SubtaskState{operatorStateFromBackend=StateObjectCollection{[OperatorStateHandle{stateNameToPartitionOffsets={Kinesis-Stream-Shard-State=StateMetaInfo{offsets=[4589, 4872, 5156, 5438, 5722, 6006, 6288, 6572, 6854, 7138, 7422, 7706, 7988, 8272, 8554, 8838, 9121, 9404, 9686, 9968, 10252, 10536, 10820, 11104, 11388, 11632, 11916, 12200, 12481, 12765, 13049, 13331, 13615, 13899, 14183, 14465, 14747, 15031, 15315, 15597, 15879, 16163, 16447, 16731, 17015, 17299, 17581, 17865, 18149, 18433, 18715, 18999, 19283, 19567, 19849, 20133, 20415, 20697, 20981, 21265, 21549, 21833, 22117, 22401, 22681, 22965, 23248, 23532, 23814, 24098, 24382, 24666, 24948, 25232, 25516, 25796, 26078, 26360, 26644, 26928, 27212, 27496, 27780, 28064, 28347, 28631, 28913, 29197, 29479, 29762, 30046, 30329, 30613, 30897, 31181, 31463, 31745, 32029, 32313, 32597, 32881, 33163, 33447, 33731, 34015, 34297, 34581, 34863, 35147, 35431, 35715, 35999, 36281, 36563, 36847, 37131, 37413, 37696, 37980, 38262, 38546, 38830, 39112,"
When I start job from scratch there is no ref to kinesis (which is expected): {Integer@1999} 0 -> {OperatorSubtaskState@2000} "SubtaskState{operatorStateFromBackend=StateObjectCollection{[OperatorStateHandle{stateNameToPartitionOffsets={_default_=StateMetaInfo{offsets=[], distributionMode=SPLIT_DISTRIBUTE}, topic-partition-offset-states=StateMetaInfo{offsets=[1523], distributionMode=UNION}}, delegateStateHandle=ByteStreamStateHandle{handleName='file:/efs/zillow-analytics-prod/prod/emr/flink/checkpoints/e34050eb668e245d265776f869a022c6/chk-4/a4240c1e-ca5c-4393-ad42-a09cc5843152', dataBytes=1574}}]}, operatorStateFromStream=StateObjectCollection{[]}, keyedStateFromBackend=StateObjectCollection{[]}, keyedStateFromStream=StateObjectCollection{[]}, stateSize=1574}"
topicConfig: cleanup.policy: "delete" retention.ms: 604800000 retention.bytes: 5000000000 partitions: 32 replicationFactor: 3
Thanks a lot! Oleg From:
Yun Tang <[hidden email]>
Hi Oleg
Have you ever checked to load the _metadata via Checkpoints.loadCheckpointMetadata to see how many records in the offsets meta? If only one record which is indicated from the logs, that will be really weird. Moreover, I have several comments based on your description:
Best Yun Tang From: Oleg Vysotsky <[hidden email]>
Hi Jacob & Timo, Thank you for checking!
I don’t use union list state in my app. FlinkKafkaConsumerBase (from kafka connector) uses it to store offsets per partition, but partitions are small (input topic has 32 partitions). The metadata file is large (about 1.5 Gb) in case of “abnormal” checkpoint. Usual checkpoints have metadata file around 180-190 Mb. I use MemoryStateBackend with state.backend.fs.memory-threshold = 1024000.
In one of my experiment I modified FlinkKafkaConsumerBase to disable initializing states in FlinkKafkaConsumerBase#initializeState and disabled saving states in FlinkKafkaConsumerBase#snapshotState. I also force “ to use the partition discoverer to fetch the initial seed partitions” by changing FlinkKafkaConsumerBase#open method (please check the code below). The problem is still there: when I restore from “bad” checkpoint the flink job creates “abnormal” checkpoints with 55 Gb associated to kafka source. Looks like flink stores not only data related to partition offsets in checkpoint which are associated with kafka source. Any idea?
Looks like the problem does relate to kafka source. E.g. switching source from kafka to kinesis and back temporary fix the problem: If I restore flink job from "bad" checkpoint (which creates the problem: not "abnormal" checkpoint) with switching from kafka to kinesis input (which has identical data). After "restored" flink job creates flrst checkpoint I cancel and restore the flink job from “new” checkpoint with kafka input from specific timestamp. The flink job creates correct checkpoints.
Just in case, I attached two “snapshots” from flink ui with example of abnormal checkpoint.
Thanks a lot! Oleg
@Override
@Override
@Override
From:
Jacob Sevart <[hidden email]>
This sounds a lot like an issue I just went through (http://apache-flink-user-mailing-list-archive.2336050.n4.nabble.com/Very-large-metadata-file-td33356.html). Are you using a union list state anywhere?
You could also use the debugging steps mentioned in that thread to inspect the contents of the bad checkpoint.
On Fri, Apr 17, 2020 at 4:46 PM Oleg Vysotsky <[hidden email]> wrote:
-- Jacob Sevart Software Engineer, Safety |
Re: Checkpoints for kafka source sometimes get 55 GB size (instead of 2 MB) and flink job fails during restoring from such checkpoint
|
|
Hi Yun, Thank a lot for your tips! I found and fixed the problem. The problem was that I didn’t change uuid for source when I switched between kinesis and kafka sources. Looks like the flink continue to use “Kinesis-Stream-Shard-State” during the
checkpointing because the uuid was not changed. It can be reproduced. Defining different uuid for kafka and kinesis sources fixed the problem. The information which I provided early was correct. There were much more offsets per operator subtask. I just copied
the beginning of the list (sorry that I didn’t clarify it). The checkpoint “source” size was around 55 Gb (please check the picture below).
Thanks a lot! Oleg From: Yun Tang <[hidden email]> Hi Oleg If the "stateNameToPartitionOffsets" in abnormal checkpoints (sub state > 1GB) is "Kinesis-Stream-Shard-State" [1] instead of "topic-partition-offset-states" [2],
I doubt all your descriptions. The _metadata tells us that it is generated from kniesis instead of kafka, and the offsets recorded [3] indicate the state handle size should be near to 39112 bytes. If that is the real abnormal checkpoint, and the source operator state offset recorded should be larger than 1073741824, please check the _metadata again to know the facts. Best Yun Tang From: Oleg Vysotsky <[hidden email]> Hi Yun, Thank you for the advices and thank you for pointing to
Checkpoints.loadCheckpointMetadata!
1.
According to Checkpoints.loadCheckpointMetadata
the “bad” and “abnormal” checkpoints metadata has > 123 offsets for “kafka source”. What is not expected that it uses “Kinesis-Stream-Shard-State” (it can be the root cause of the problem and happened because I restored from
“kinesis” checkpoint). What do you think? {Integer@1999} 0 -> {OperatorSubtaskState@2000} "SubtaskState{operatorStateFromBackend=StateObjectCollection{[OperatorStateHandle{stateNameToPartitionOffsets={Kinesis-Stream-Shard-State=StateMetaInfo{offsets=[4589,
4872, 5156, 5438, 5722, 6006, 6288, 6572, 6854, 7138, 7422, 7706, 7988, 8272, 8554, 8838, 9121, 9404, 9686, 9968, 10252, 10536, 10820, 11104, 11388, 11632, 11916, 12200, 12481, 12765, 13049, 13331, 13615, 13899, 14183, 14465, 14747, 15031, 15315, 15597, 15879,
16163, 16447, 16731, 17015, 17299, 17581, 17865, 18149, 18433, 18715, 18999, 19283, 19567, 19849, 20133, 20415, 20697, 20981, 21265, 21549, 21833, 22117, 22401, 22681, 22965, 23248, 23532, 23814, 24098, 24382, 24666, 24948, 25232, 25516, 25796, 26078, 26360,
26644, 26928, 27212, 27496, 27780, 28064, 28347, 28631, 28913, 29197, 29479, 29762, 30046, 30329, 30613, 30897, 31181, 31463, 31745, 32029, 32313, 32597, 32881, 33163, 33447, 33731, 34015, 34297, 34581, 34863, 35147, 35431, 35715, 35999, 36281, 36563, 36847,
37131, 37413, 37696, 37980, 38262, 38546, 38830, 39112," When I start job from scratch
there is no ref to kinesis (which is expected): {Integer@1999} 0 -> {OperatorSubtaskState@2000} "SubtaskState{operatorStateFromBackend=StateObjectCollection{[OperatorStateHandle{stateNameToPartitionOffsets={_default_=StateMetaInfo{offsets=[], distributionMode=SPLIT_DISTRIBUTE},
topic-partition-offset-states=StateMetaInfo{offsets=[1523], distributionMode=UNION}}, delegateStateHandle=ByteStreamStateHandle{handleName='file:/efs/zillow-analytics-prod/prod/emr/flink/checkpoints/e34050eb668e245d265776f869a022c6/chk-4/a4240c1e-ca5c-4393-ad42-a09cc5843152',
dataBytes=1574}}]}, operatorStateFromStream=StateObjectCollection{[]}, keyedStateFromBackend=StateObjectCollection{[]}, keyedStateFromStream=StateObjectCollection{[]}, stateSize=1574}"
2.
I am sorry for the incorrect information (paste and copy error). We use
FsStateBackend (more precise efs attached to each node of emr cluster) and
state.backend.fs.memory-threshold = 1024000
3.
It is correct I used
4.
Kafka topic was created by other team. It was created based on following properties. Also we have 6 kafka brokers. Please let me know if you need more details or you interested in specific kafka parameter value.
topicConfig: cleanup.policy: "delete" retention.ms: 604800000 retention.bytes: 5000000000 partitions: 32 replicationFactor: 3 Thanks a lot! Oleg From:
Yun Tang <[hidden email]> Hi Oleg Have you ever checked to load the _metadata via
Checkpoints.loadCheckpointMetadata to see how many records in the offsets meta? If only one record which is indicated from the logs, that will be really weird. Moreover, I have several comments based on your description:
Best Yun Tang From: Oleg Vysotsky <[hidden email]> Hi Jacob & Timo, Thank you for checking! I don’t use union list state in my app. FlinkKafkaConsumerBase (from kafka connector) uses it to store offsets per partition, but partitions are small (input topic has 32 partitions). The metadata file is large (about 1.5 Gb) in case
of “abnormal” checkpoint. Usual checkpoints have metadata file around 180-190 Mb. I use MemoryStateBackend with state.backend.fs.memory-threshold = 1024000.
In one of my experiment I modified FlinkKafkaConsumerBase to disable initializing states in FlinkKafkaConsumerBase#initializeState and disabled saving states in FlinkKafkaConsumerBase#snapshotState. I also force “ to use the partition
discoverer to fetch the initial seed partitions” by changing FlinkKafkaConsumerBase#open method (please check the code below). The problem is still there: when I restore from “bad” checkpoint the flink job creates “abnormal” checkpoints with 55 Gb associated
to kafka source. Looks like flink stores not only data related to partition offsets in checkpoint which are associated with kafka source. Any idea? Looks like the problem does relate to kafka source. E.g. switching source from kafka to kinesis and back temporary fix the problem: If I restore flink job from "bad" checkpoint (which creates the problem: not "abnormal" checkpoint) with switching from kafka to kinesis input (which has identical data). After "restored" flink job creates flrst checkpoint I cancel and
restore the flink job from “new” checkpoint with kafka input from specific timestamp. The flink job creates correct checkpoints.
Just in case, I attached two “snapshots” from flink ui with example of abnormal checkpoint. Thanks a lot! Oleg @Override @Override @Override From:
Jacob Sevart <[hidden email]> This sounds a lot like an issue I just went through (http://apache-flink-user-mailing-list-archive.2336050.n4.nabble.com/Very-large-metadata-file-td33356.html).
Are you using a union list state anywhere? You could also use the debugging steps mentioned in that thread to inspect the contents of the bad checkpoint. On Fri, Apr 17, 2020 at 4:46 PM Oleg Vysotsky <[hidden email]> wrote:
-- Jacob Sevart Software Engineer, Safety |
| Free forum by Nabble | Edit this page |