Checkpoint dir is not cleaned up after cancel the job with monitoring API

Checkpoint dir is not cleaned up after cancel the job with monitoring API

|
Hi experts,
I am running flink 1.10.2 on kubernetes as per job cluster. Checkpoint is enabled, with interval 3s, minimumPause 1s, timeout 10s. I'm using FsStateBackend, snapshots are persisted to azure blob storage (Microsoft cloud storage service). Checkpointed state is just source kafka topic offsets, the flink job is stateless as it does filter/json transformation. The way I am trying to stop the flink job is via monitoring rest api mentioned in doc e.g. curl -X PATCH \ 'http://localhost:8081/jobs/3c00535c182a3a00258e2f57bc11fb1a?mode=cancel' \ -H 'Content-Type: application/json' \ -d '{}' This call returned successfully with statusCode 202, then I stopped the task manager pods and job manager pod. According to the doc, the checkpoint should be cleaned up after the job is stopped/cancelled. What I have observed is, the checkpoint dir is not cleaned up, can you please shield some lights on what I did wrong? Below shows the checkpoint dir for a cancelled flink job. 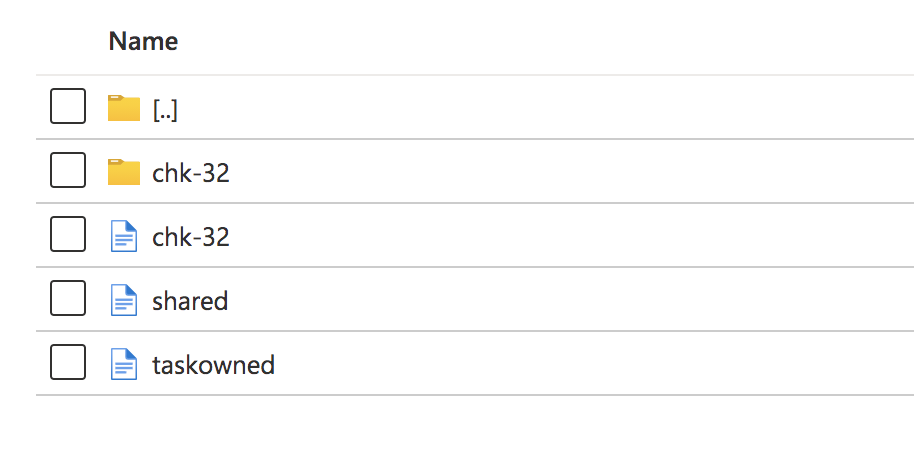 Thanks! Eleanore |
Re: Checkpoint dir is not cleaned up after cancel the job with monitoring API
|
|
Hi Eleanore What the `CheckpointRetentionPolicy`[1] did you set for your job? if `ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION` is set, then the checkpoint will be kept when canceling a job. PS the image did not show Eleanore Jin <[hidden email]> 于2020年9月27日周日 下午1:50写道:
|
Re: Checkpoint dir is not cleaned up after cancel the job with monitoring API
|
|
Hi Congxian, I am making rest call to get the checkpoint config: curl -X GET \ http://localhost:8081/jobs/d2c91a44f23efa2b6a0a89b9f1ca5a3d/checkpoints/configand here is the response: { "mode": "at_least_once", "interval": 3000, "timeout": 10000, "min_pause": 1000, "max_concurrent": 1, "externalization": { "enabled": false, "delete_on_cancellation": true }, "state_backend": "FsStateBackend" } I uploaded a screenshot of how azure blob storage looks like after the cancel call : https://ibb.co/vY64pMZ Thanks a lot! Eleanore On Sat, Sep 26, 2020 at 11:23 PM Congxian Qiu <[hidden email]> wrote:
|
Re: Checkpoint dir is not cleaned up after cancel the job with monitoring API
|
|
I have noticed this: if I have Thread.sleep(1500); after the patch call returned 202, then the directory gets cleaned up, in the meanwhile, it shows the job-manager pod is in completed state before getting terminated: see screenshot: https://ibb.co/3F8HsvG So the patch call is async to terminate the job? Is there a way to check if cancel is completed? So that the stop tm and jm can be called afterwards? Thanks a lot! Eleanore On Sun, Sep 27, 2020 at 9:37 AM Eleanore Jin <[hidden email]> wrote:
|
Re: Checkpoint dir is not cleaned up after cancel the job with monitoring API
|
|
Yes, the patch call only triggers the
cancellation.
You can check whether it is complete by
polling the job status via jobs/<jobid> and checking whether
state is CANCELED.
On 9/27/2020 7:02 PM, Eleanore Jin
wrote:
|
Re: Checkpoint dir is not cleaned up after cancel the job with monitoring API
|
|
Thanks a lot for the confirmation. Eleanore On Fri, Oct 2, 2020 at 2:42 AM Chesnay Schepler <[hidden email]> wrote:
|
«
Return to (DEPRECATED) Apache Flink User Mailing List archive.
|
1 view|%1 views
| Free forum by Nabble | Edit this page |