Checkpoint Failures from Backpressure, possibly due to overloaded network buffers?

Checkpoint Failures from Backpressure, possibly due to overloaded network buffers?

|
Hi, I have been troubleshooting a checkpoint failure for the past week. Here is our setup:
The checkpoint fails pretty fast, and I believe it is caused by high backpressure in the ProcessFn operator. My guess is that it is due to a network buffer overload issue, if that’s even possible. I read a bit about checkpoint barriers
not being able to be emitted if the buffers are full. The checkpoints fail in the the ProcessFn.onTimer() call, where it emits a lot of records. I have seen it fail on just 30,000 records emitted, but there are times (if in “catchup” mode) when there are over 2.5million records emitted, all
at once. In the case of 30,000 records emitted, I dissected our logs, and saw that the records are emitted at a rate of
~50records/second. The DB sink just performs simple inserts into an indexed table. Looking at the DB metrics, the inserts have an avg latency of 0.2 seconds, yet only about 40 rows are inserts/sec. I use the default JdbcExecutionOptions (batch size=5000,
batch interval=0), so I don’t think it’s the database. I eliminated the JdbcSink and just used a .print() sink instead, just to make sure, and it still fails. This makes me think it is a network latency issue, but not between Flink and the db. Is it possible
that the output buffer of the ProcessFn is being throttled? Another potential cause for the checkpoint timeouts is that the state is very large, and it’s taking that long to write it out to RocksDB. In the case of 2.5million records, the largest map state can be about 100MB. This is when it is catching
up for about 24hrs, and after that the checkpointed sizes should be smaller. Would it really take that long to write out 100mb to RocksDB though? I really have no idea. So 2 possible causes that I can think of that is causing the checkpoint timeout failures:
I want to experiment with solving #1 by reducing the number of elements being output. It’s possible to do this by sending an object with a start and end timestamp, and just generate SQL statements for each timestamp between start/end with
a given interval. However, it seems the only way to do this is to write my own JdbcSink, and override JdbcBatchingOutputFormat.writeRecord() (to adjust how batchCount is incremented). Doesn’t seem like it was designed to be overridden though, because it uses
some internal classes, like JdbcExec. If the problem is #2, then we will need to figure out a way to speed up the checkpoint writes, by either drastically reducing state size, or optimizing our configuration/adding more resources. So in summary, my questions are:
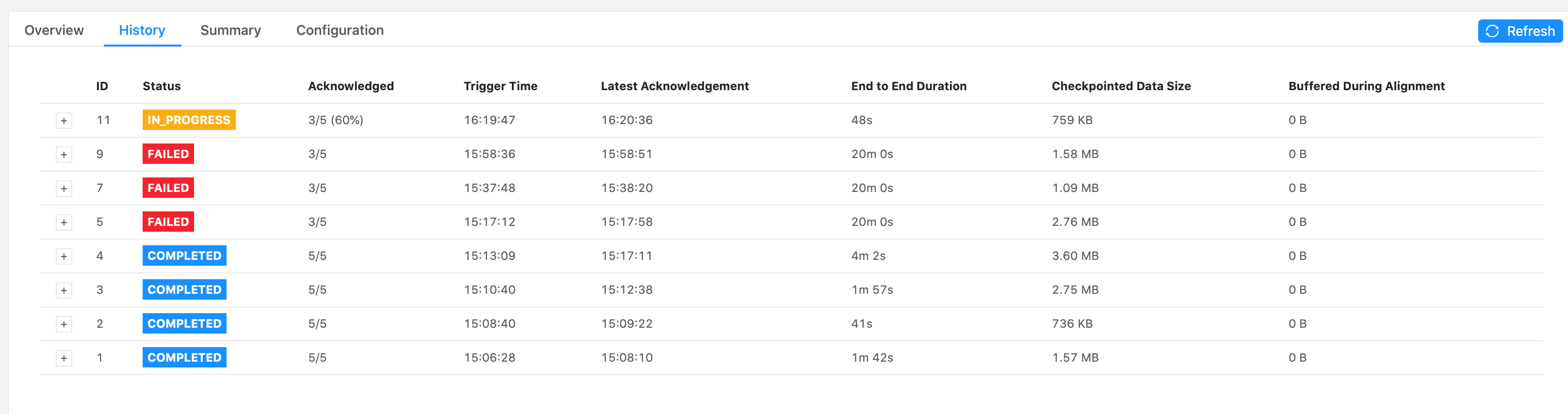
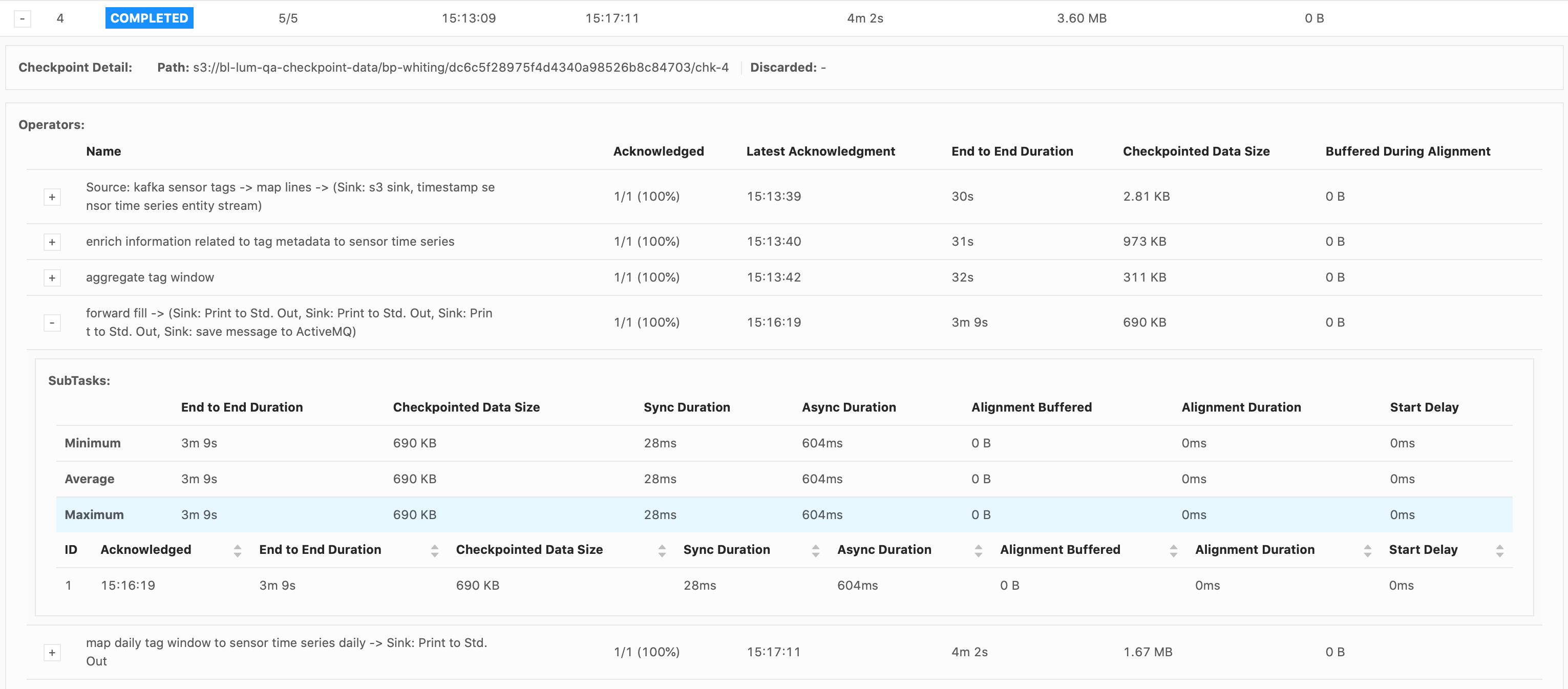
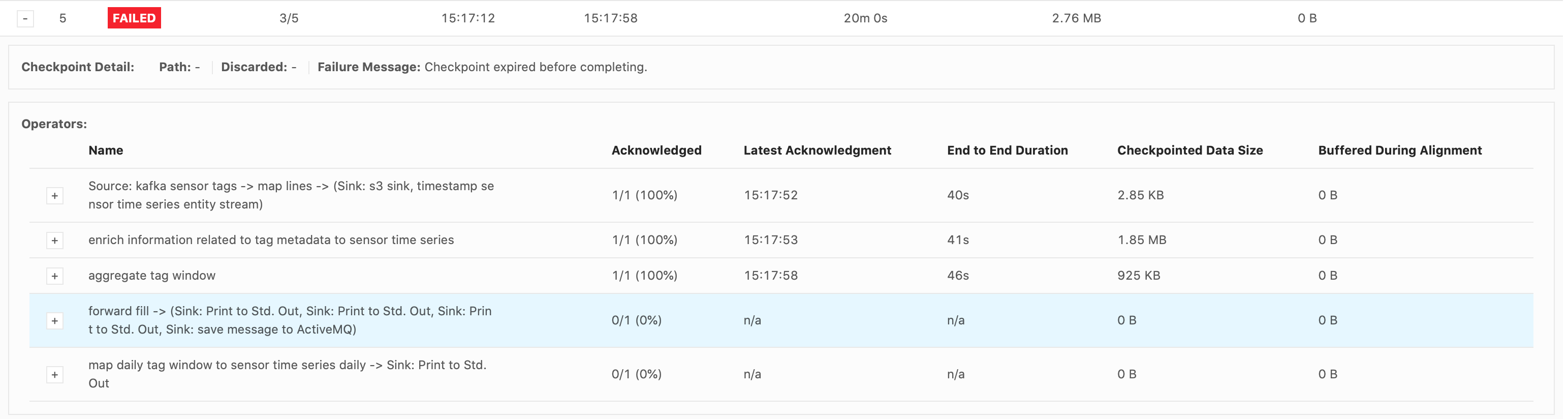
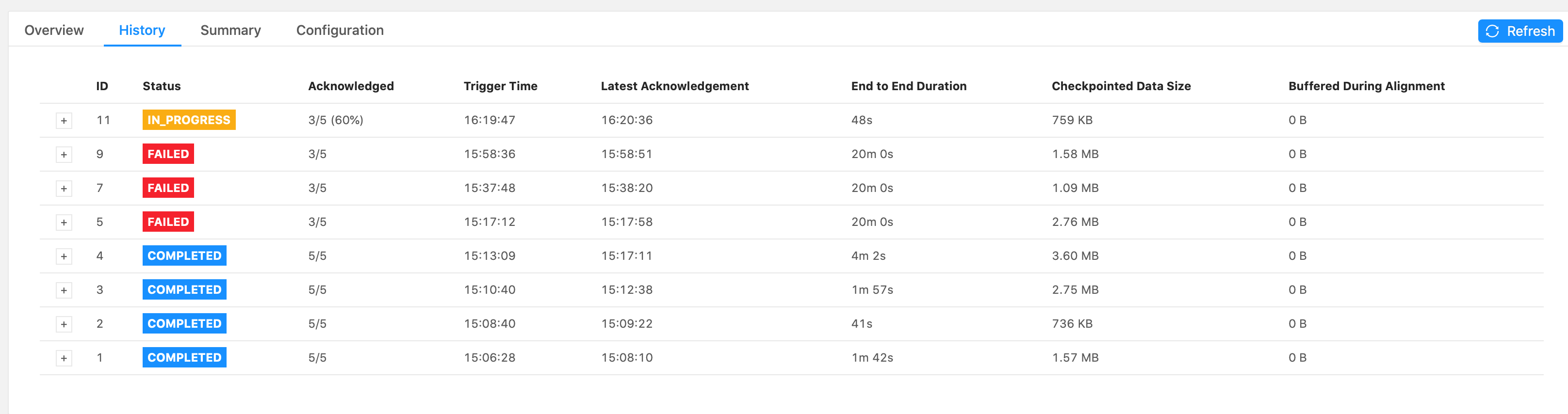
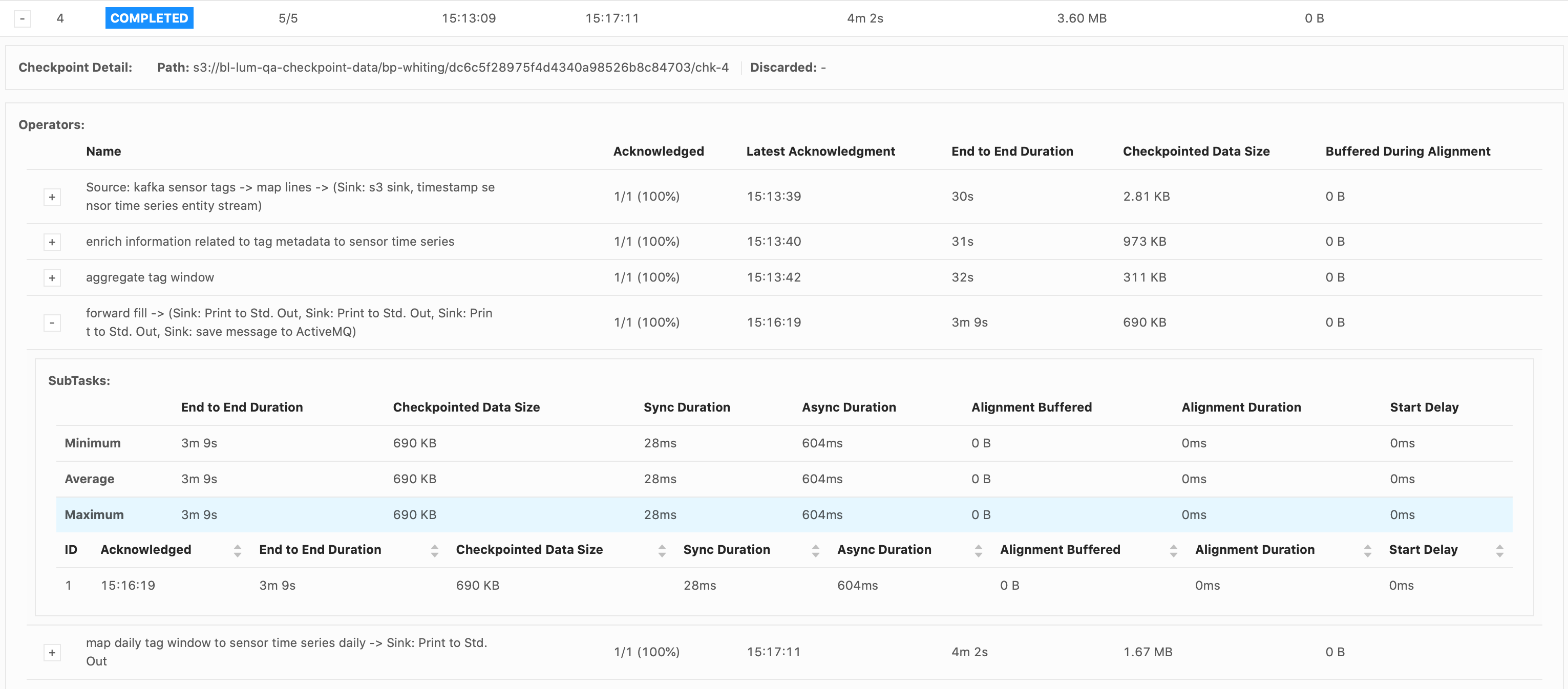
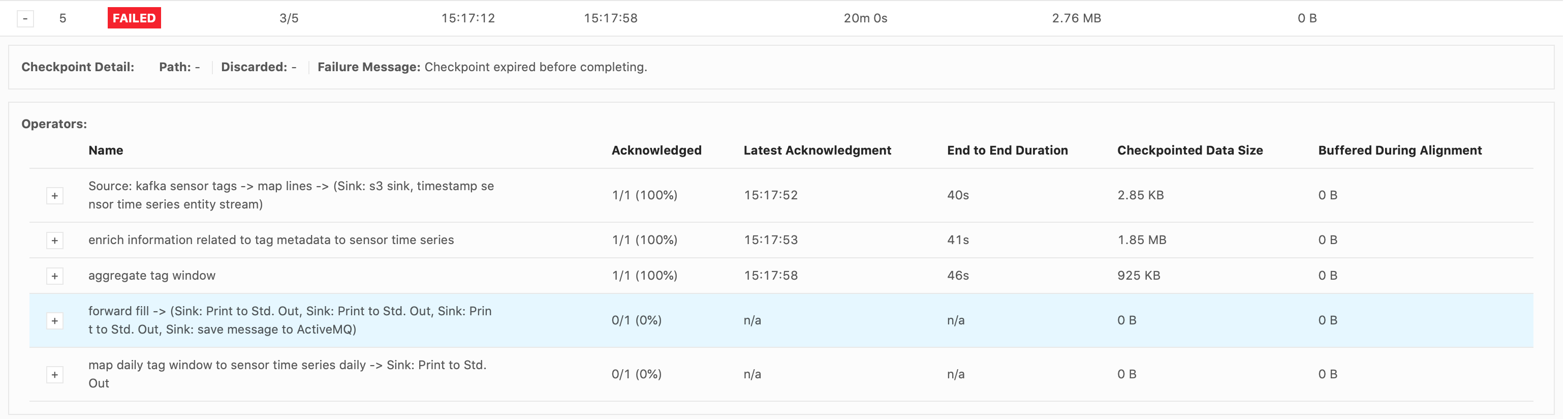
Please let me know if you need more information. I attached some screenshots of the Flink UI below, when it failed on the 2.5million emission (forward-fill flow). Thank you for your time, Cecile
|

Re: Checkpoint Failures from Backpressure, possibly due to overloaded network buffers?
|
|
Hi, From what you have described indeed it sounds that the backpressure is the most likely explanation. Note that you are using parallelism one, in which case there is a bug/limitation in how the `start delay` metric is calculated, that will be fixed only in the 1.13.0 [0], so you can not rely on this metric. However keep in mind that "Start Delay" = "End to End duration" - "Sync duration" - "Async duration" With that in mind, your screenshots strongly indicate that the barrier was travelling a very long time (3+ minutes) in this one completed checkpoint. There are a couple of things that you could do 1. Fix the backpressure problem. First you should detect where the bottleneck is and then try to address the problem. Once the backpressure is no longer an issue, checkpoints should be working much quicker. Also make sure that your job is making progress at all, and that it's not completely stuck on something. 2. Reduce the amount of buffered records during the backpressure. Since you have very low records throughput (57 records/s produced at the source) and your records are small (~482bytes/record at the source?), so the total throughput is ~27KB/s. This value is so small, that you can safely reduce the amount of buffered data. You can reduce both the amount of exclusive buffers per channel (from 2 down to 1) [1] and floating (from 8 to 1 or even 0?) [2] and the buffer size as well [3] (from 32KB to 1KB? 512Bytes?). [1] and [2] will reduce the latency of exchanging the buffers a bit. Especially if you have just a single buffer, the upstream task will not be able to produce any records while the buffer is being passed to the downstream task. However I doubt you would even notice this delay. Reducing buffer size [3] would mean that the buffers would need to be exchanged more often, so causing a bit more network traffic, but again, with ~27KB/s you shouldn't notice it. All combined would reduce your buffered data from 320KB down to 512bytes per channel. This should speed up propagation of the Checkpoint Barriers roughly 640x times. You can read more about how to tune network stack here [6][7] 3. Use Unaligned Checkpoints [4]. However keep in mind that in 1.12.x Unaligned Checkpoints can cause in some rare situations stream corruption in 1.12.x. This will be probably fixed in 1.12.2 [5] Piotrek sob., 30 sty 2021 o 20:26 Cecile Kim <[hidden email]> napisał(a):
|

Re: Checkpoint Failures from Backpressure, possibly due to overloaded network buffers?
|
|
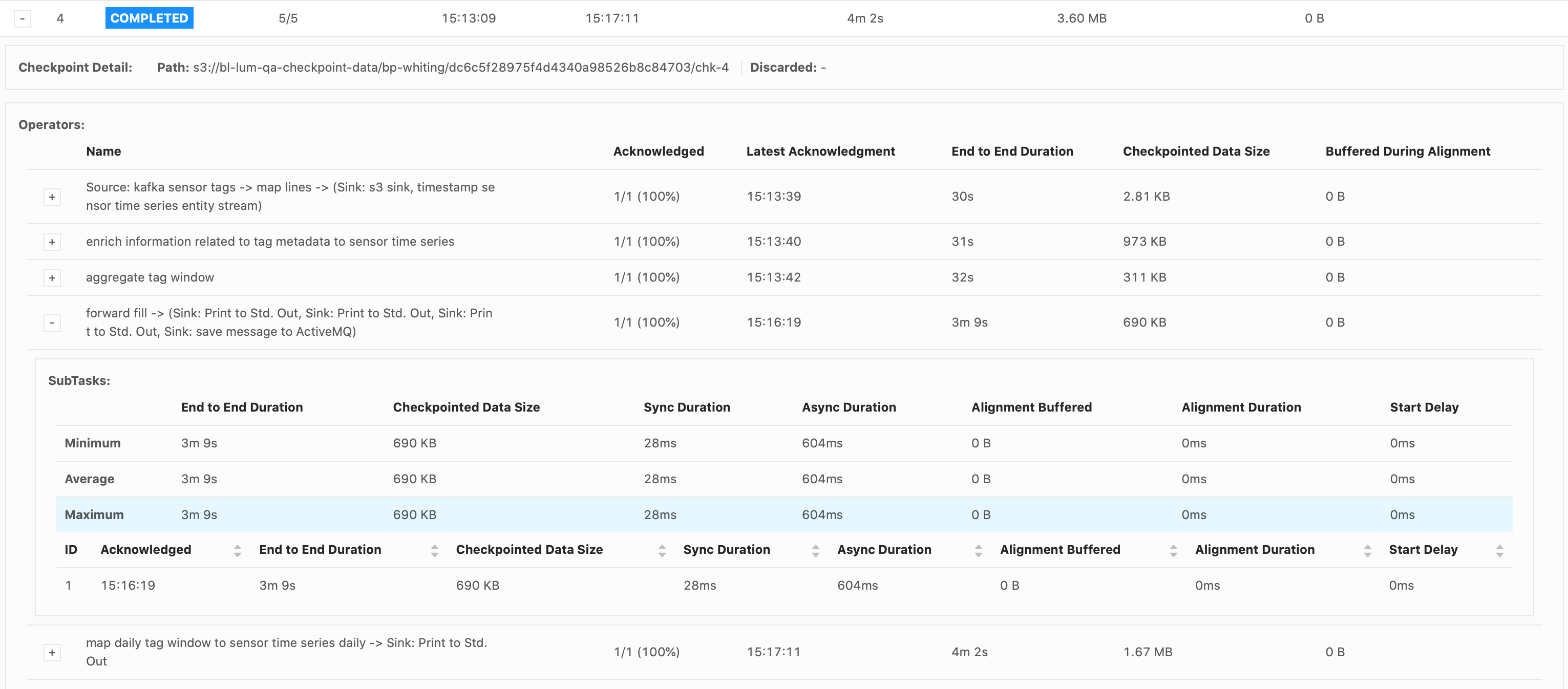
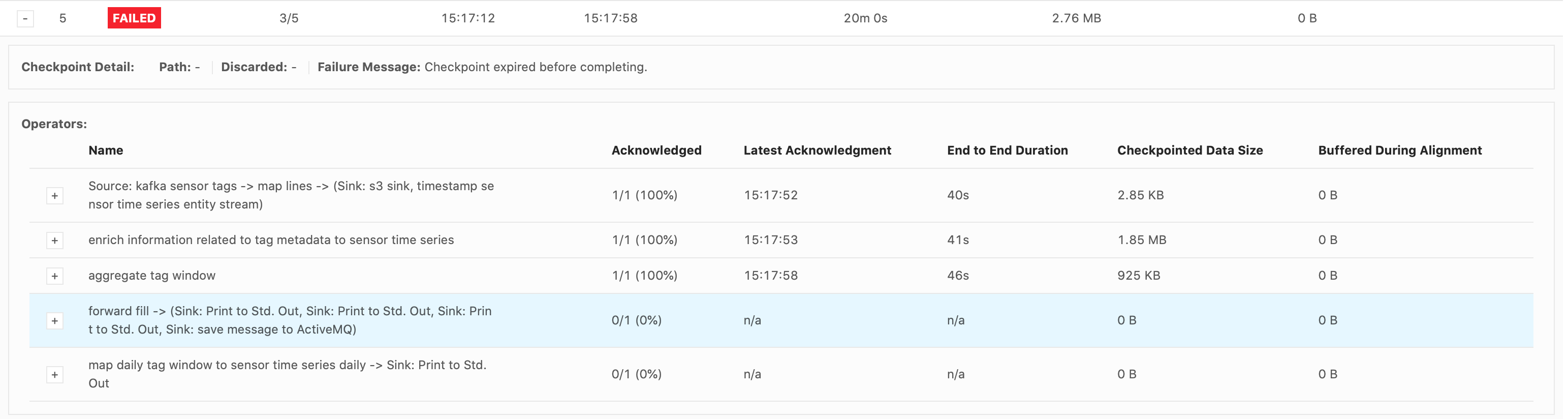
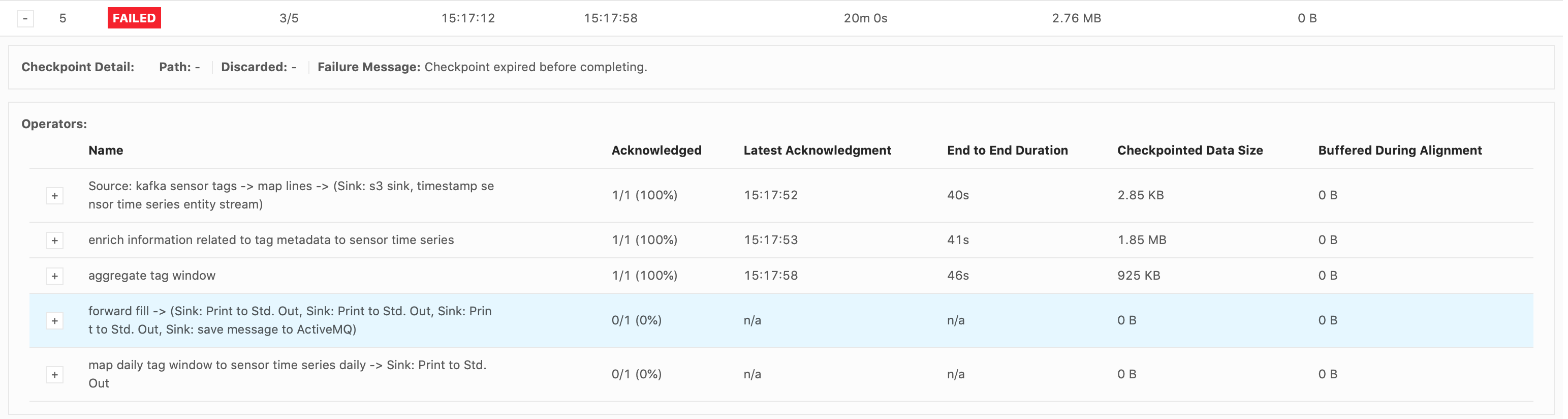
Hi Piotr, Thank you for your response. Good to know about the Start Delay bug. I do believe that the bottleneck occurs when emitting over 28,000 (up to 25million) records all at once in the forward-fill ProcessFunction.
Also, that screenshot below had a problem with the input data stream. Our actual input rate is about
186 records/s. Should I still try setting the configs the same as you suggested?
I will let you know my results of changing the above configuration. Thank you for the links on tuning the network stack. I will go over them more carefully to make sure I understand. I will also try unaligned checkpoints next, if the config
changes alone don’t resolve it. As for eliminating the source of the backpressure, that’s what I’m struggling with at the moment. The failure always occurs as the forward-fill ProcessFunction is emitting a lot of records at once, every 15mins (from 30,000 records up to
over 25million). I replaced the db sink with a print() sink immediately after the forward-fill function, and the failure still occurs. So this is why I thought it was a network buffer/latency issue? We only have one Task Manager though so I don’t understand
why just printing the results would cause backpressure, since there shouldn’t be data transferred between different TMs. Maybe I am not understanding something about the network flow. I was considering trying to resolve the backpressure by drastically reducing the numbers of records emitted by the forward-fill function, but it will take a significant redesign. Do you think this could eliminate the backpressure?
Thank you, Cecile From:
Piotr Nowojski <[hidden email]> Hi, From what you have described indeed it sounds that the backpressure is the most likely explanation. Note that you are using parallelism one, in which case there is a bug/limitation in how the `start delay` metric is calculated, that will
be fixed only in the 1.13.0 [0], so you can not rely on this metric. However keep in mind that "Start Delay" = "End to End duration" - "Sync duration" - "Async duration" With that in mind, your screenshots strongly indicate that the barrier was travelling a very long time (3+ minutes) in this one completed checkpoint. There are a couple of things that you could do 1. Fix the backpressure problem. First you should detect where the bottleneck is and then try to address the problem. Once the backpressure is no longer an issue, checkpoints should be working much quicker. Also make sure that your job is making progress at all, and that it's not completely stuck on something. 2. Reduce the amount of buffered records during the backpressure. Since you have very low records throughput (57 records/s produced at the source) and your records are small (~482bytes/record at the source?), so the total throughput is ~27KB/s. This value is so small, that you can safely reduce the amount
of buffered data. You can reduce both the amount of exclusive buffers per channel (from 2 down to 1) [1] and floating (from 8 to 1 or even 0?) [2] and the buffer size as well [3] (from 32KB to 1KB? 512Bytes?). [1] and [2] will reduce the latency of exchanging
the buffers a bit. Especially if you have just a single buffer, the upstream task will not be able to produce any records while the buffer is being passed to the downstream task. However I doubt you would even notice this delay. Reducing buffer size [3] would
mean that the buffers would need to be exchanged more often, so causing a bit more network traffic, but again, with ~27KB/s you shouldn't notice it. All combined would reduce your buffered data from 320KB down to 512bytes per channel. This should speed up
propagation of the Checkpoint Barriers roughly 640x times. You can read more about how to tune network stack here [6][7] 3. Use Unaligned Checkpoints [4]. However keep in mind that in 1.12.x Unaligned Checkpoints can cause in some rare situations stream corruption in 1.12.x. This will be probably fixed in 1.12.2 [5] Piotrek sob., 30 sty 2021 o 20:26 Cecile Kim <[hidden email]> napisał(a):
|

Re: Checkpoint Failures from Backpressure, possibly due to overloaded network buffers?
|
|
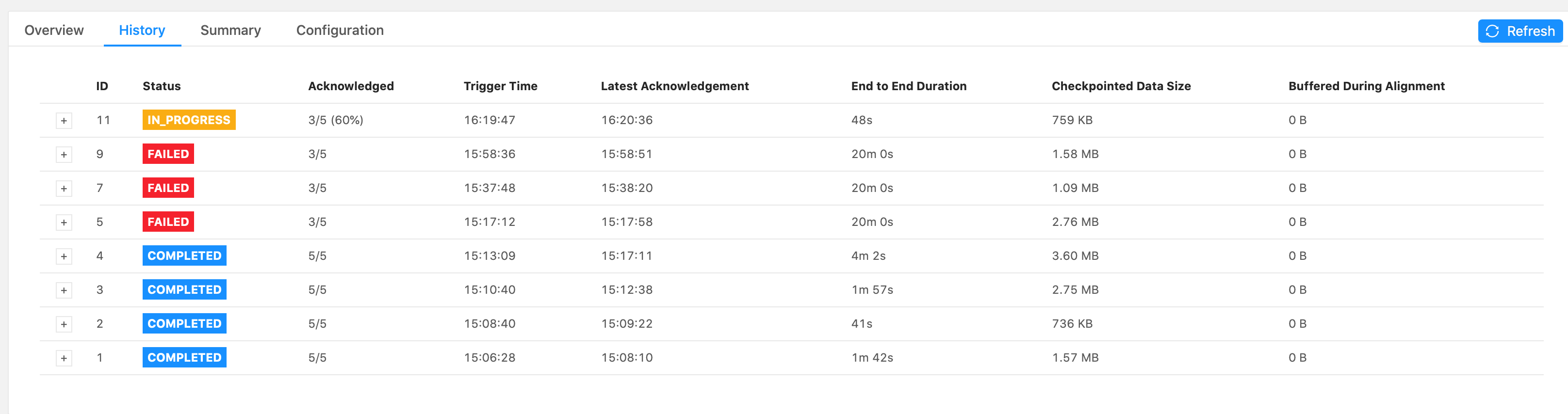
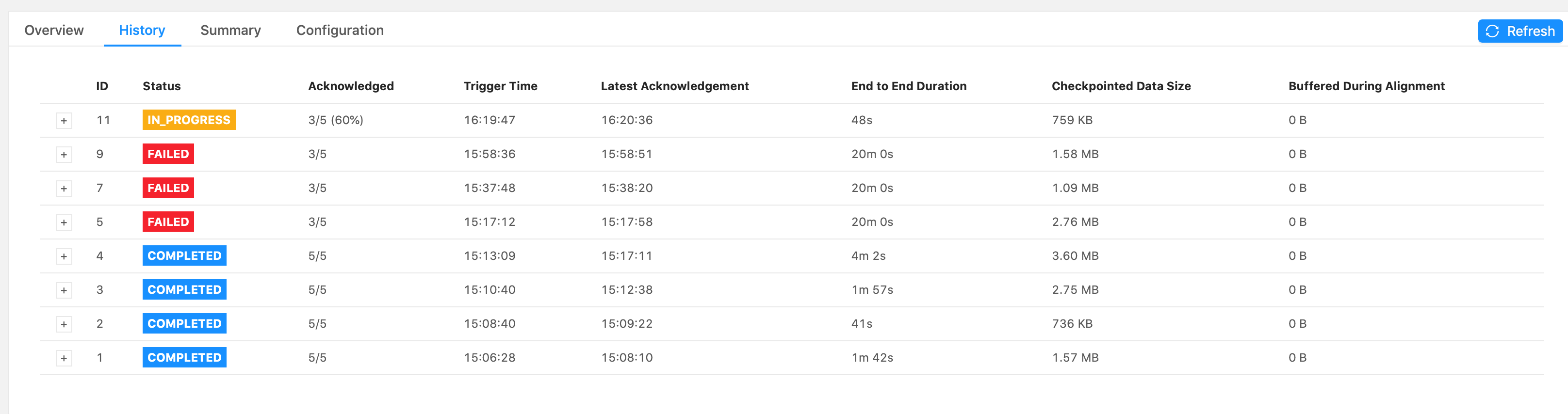
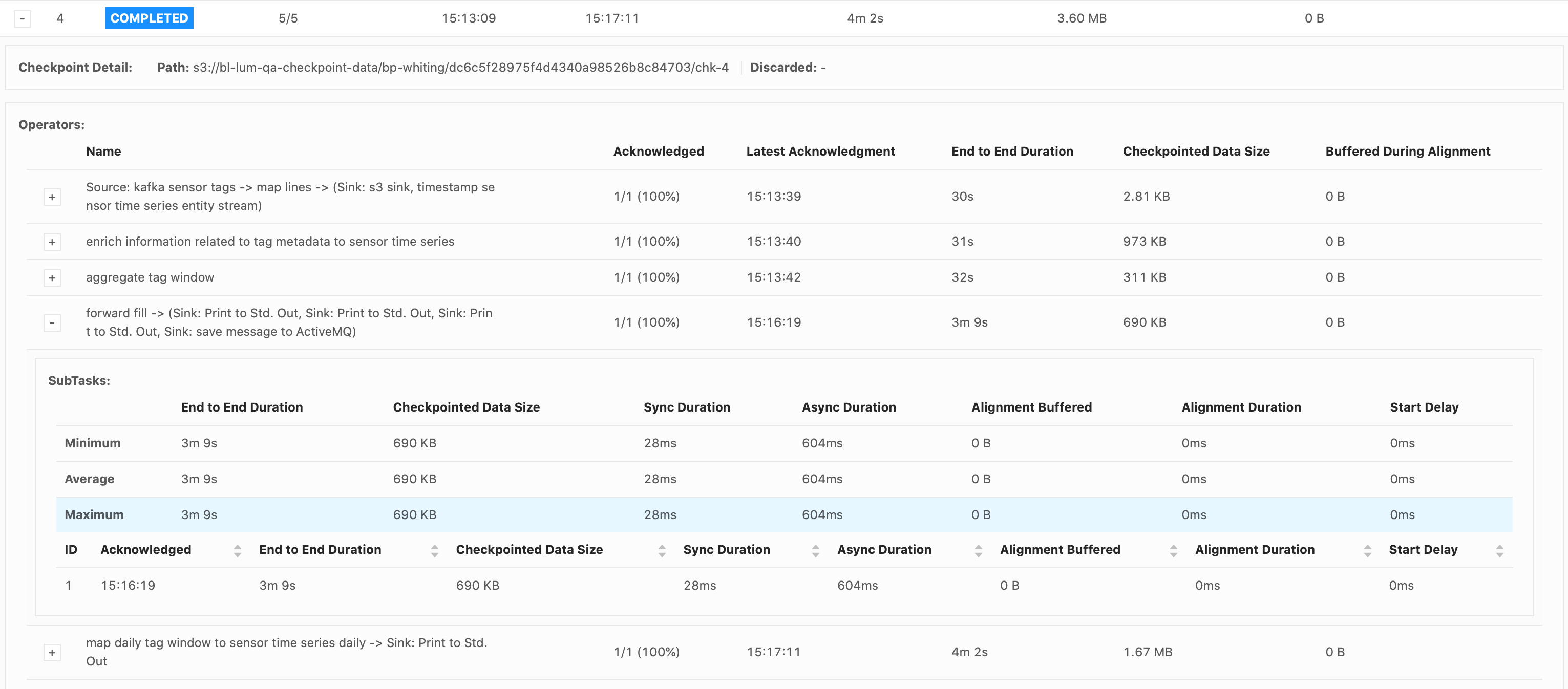
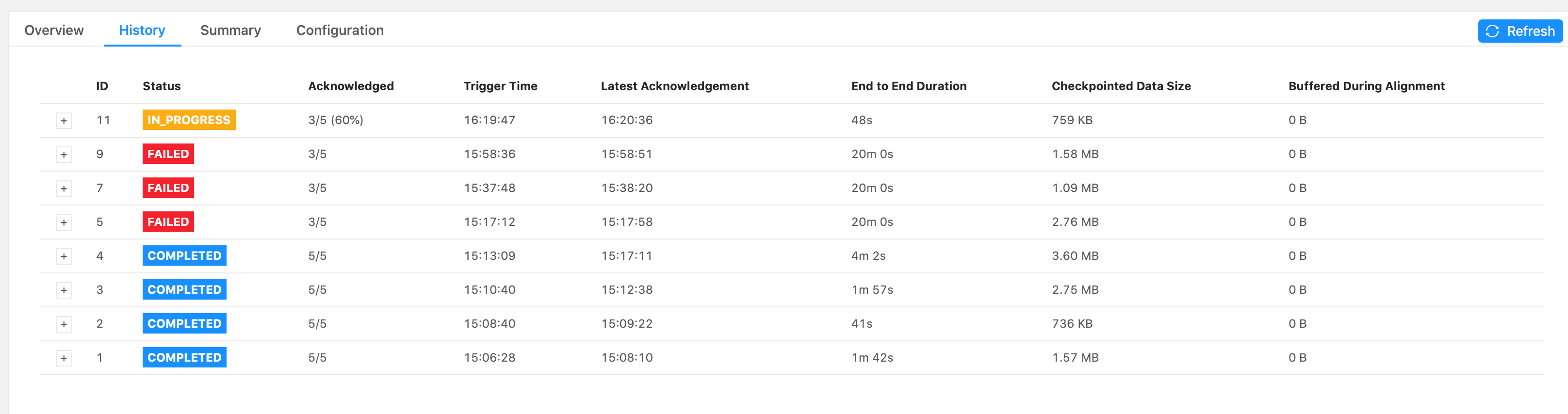
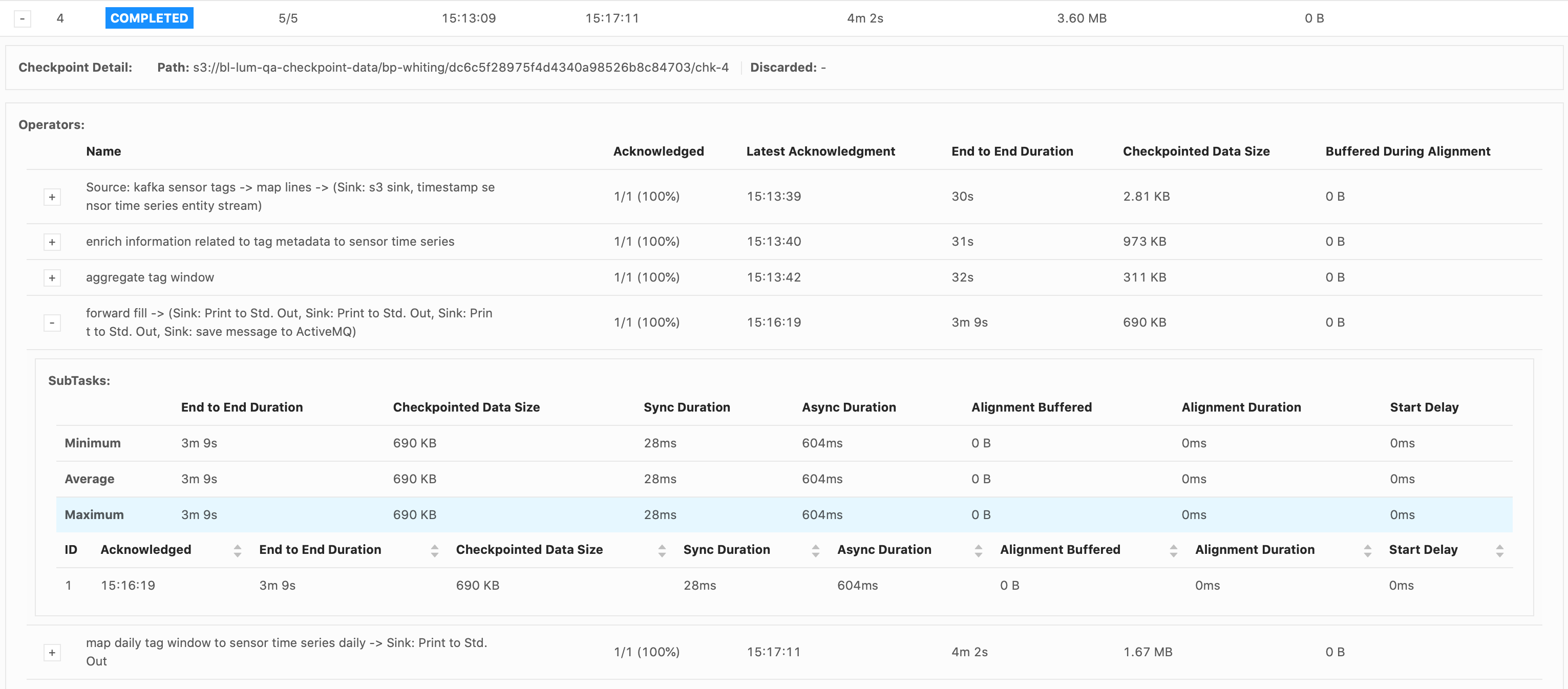
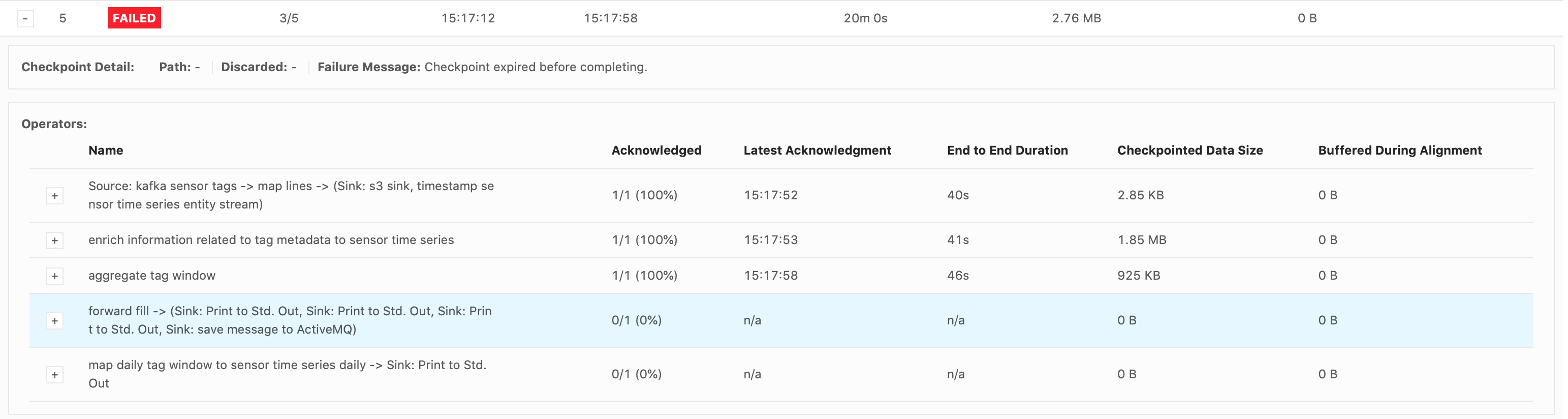
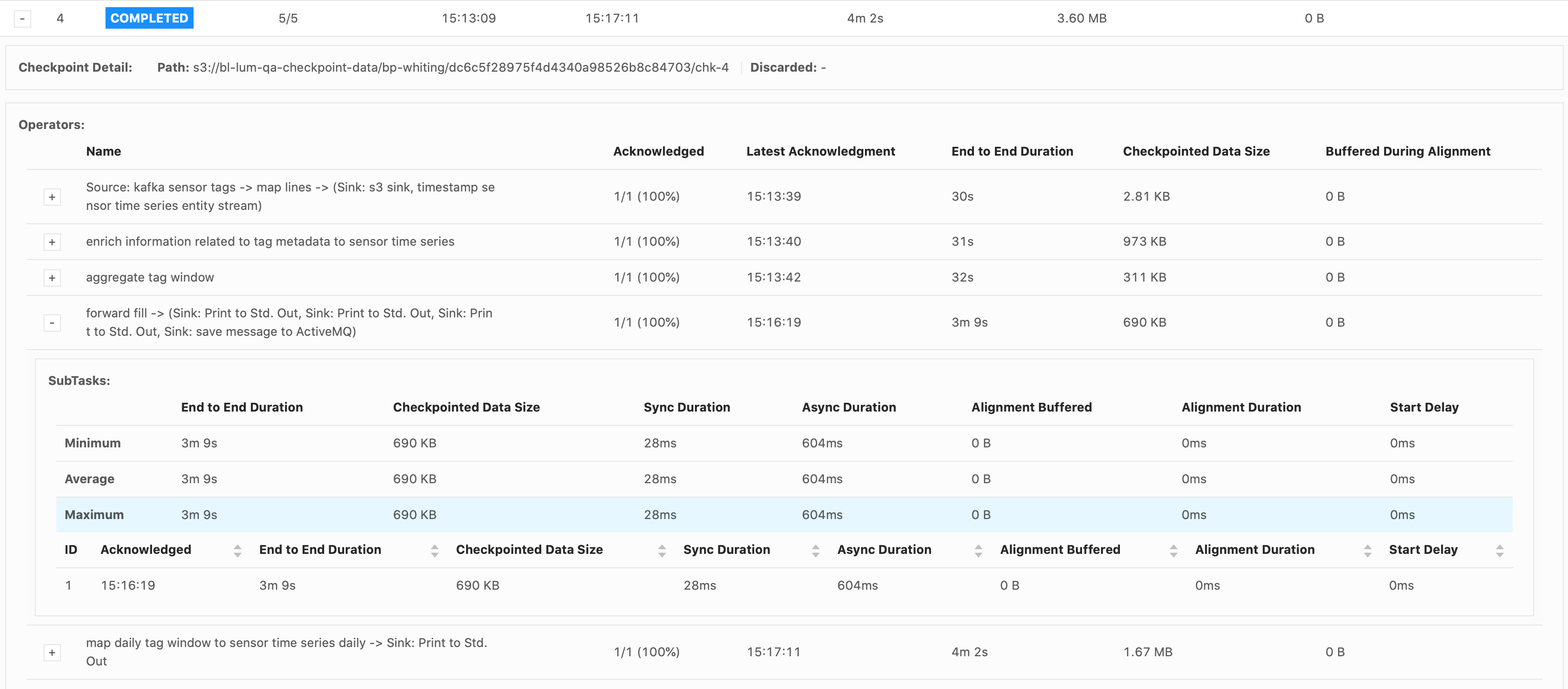
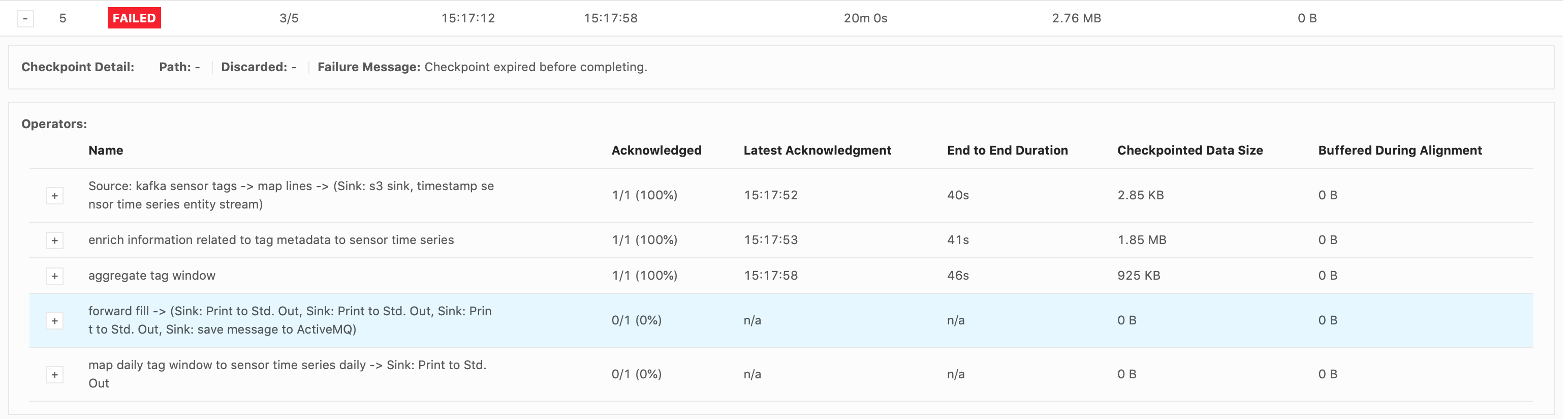
Hi Piotr, The job failed at the same spot, in the forwardFill ProcessFunction’s .onTimer() call, when emitting 32,650 tags. These were my configs:
Again, it’s just a print() sink. I see that it takes a while to print everything out. The forwardFill fn start to emit 32650 tags (tags list already built, it’s simply looping thru the list to emit all of them) at 21:04: 2021-02-01 21:04:08,000 DEBUG ai.beyond.luminai.sensor.pipeline.stream.functions.process.ForwardFillKeyedProcessFunction [] - Emitting
32650 tags at current step And the job fails at about 21:29 (Failed checkpoint trigger time is 20:59:19). 29,272 tags out of the 32,650 tags were printed to the sink before failing. I’m not understanding why it would take so long to just emit and print 32,650 tags? Please advise.
Thank you, Cecile From:
Cecile Kim <[hidden email]> Hi Piotr, Thank you for your response. Good to know about the Start Delay bug. I do believe that the bottleneck occurs when emitting over 28,000 (up to 25million) records all at once in the forward-fill ProcessFunction.
Also, that screenshot below had a problem with the input data stream. Our actual input rate is about
186 records/s. Should I still try setting the configs the same as you suggested?
I will let you know my results of changing the above configuration. Thank you for the links on tuning the network stack. I will go over them more carefully to make sure I understand. I will also try unaligned checkpoints next, if the config
changes alone don’t resolve it. As for eliminating the source of the backpressure, that’s what I’m struggling with at the moment. The failure always occurs as the forward-fill ProcessFunction is emitting a lot of records at once, every 15mins (from 30,000 records up to
over 25million). I replaced the db sink with a print() sink immediately after the forward-fill function, and the failure still occurs. So this is why I thought it was a network buffer/latency issue? We only have one Task Manager though so I don’t understand
why just printing the results would cause backpressure, since there shouldn’t be data transferred between different TMs. Maybe I am not understanding something about the network flow. I was considering trying to resolve the backpressure by drastically reducing the numbers of records emitted by the forward-fill function, but it will take a significant redesign. Do you think this could eliminate the backpressure?
Thank you, Cecile From:
Piotr Nowojski <[hidden email]> Hi, From what you have described indeed it sounds that the backpressure is the most likely explanation. Note that you are using parallelism one, in which case there is a bug/limitation in how the `start delay` metric is calculated, that will
be fixed only in the 1.13.0 [0], so you can not rely on this metric. However keep in mind that "Start Delay" = "End to End duration" - "Sync duration" - "Async duration" With that in mind, your screenshots strongly indicate that the barrier was travelling a very long time (3+ minutes) in this one completed checkpoint. There are a couple of things that you could do 1. Fix the backpressure problem. First you should detect where the bottleneck is and then try to address the problem. Once the backpressure is no longer an issue, checkpoints should be working much quicker. Also make sure that your job is making progress at all, and that it's not completely stuck on something. 2. Reduce the amount of buffered records during the backpressure. Since you have very low records throughput (57 records/s produced at the source) and your records are small (~482bytes/record at the source?), so the total throughput is ~27KB/s. This value is so small, that you can safely reduce the amount
of buffered data. You can reduce both the amount of exclusive buffers per channel (from 2 down to 1) [1] and floating (from 8 to 1 or even 0?) [2] and the buffer size as well [3] (from 32KB to 1KB? 512Bytes?). [1] and [2] will reduce the latency of exchanging
the buffers a bit. Especially if you have just a single buffer, the upstream task will not be able to produce any records while the buffer is being passed to the downstream task. However I doubt you would even notice this delay. Reducing buffer size [3] would
mean that the buffers would need to be exchanged more often, so causing a bit more network traffic, but again, with ~27KB/s you shouldn't notice it. All combined would reduce your buffered data from 320KB down to 512bytes per channel. This should speed up
propagation of the Checkpoint Barriers roughly 640x times. You can read more about how to tune network stack here [6][7] 3. Use Unaligned Checkpoints [4]. However keep in mind that in 1.12.x Unaligned Checkpoints can cause in some rare situations stream corruption in 1.12.x. This will be probably fixed in 1.12.2 [5] Piotrek sob., 30 sty 2021 o 20:26 Cecile Kim <[hidden email]> napisał(a):
|

Re: Checkpoint Failures from Backpressure, possibly due to overloaded network buffers?
|
|
Hi Piotr, Just an update on this problem – I read all the links you shared about the network stack, and I verified that it is not a network issue (no high values for floating buffers, input/outputPools, etc). I think I found the cause of the backpressure
(it was not what I had expected). I eliminated the suspected culprit from the pipeline and also applied your recommended configs for the taskmanager.network/memory.segment.size. I no longer have high backpressure in any of my tasks and no more checkpoint failures.
I re-enabled the db sink and will let it run over night. Thank you for your help! Cecile From:
Cecile Kim <[hidden email]> Hi Piotr, The job failed at the same spot, in the forwardFill ProcessFunction’s .onTimer() call, when emitting 32,650 tags. These were my configs:
Again, it’s just a print() sink. I see that it takes a while to print everything out. The forwardFill fn start to emit 32650 tags (tags list already built, it’s simply looping thru the list to emit all of them) at 21:04: 2021-02-01 21:04:08,000 DEBUG ai.beyond.luminai.sensor.pipeline.stream.functions.process.ForwardFillKeyedProcessFunction [] - Emitting
32650 tags at current step And the job fails at about 21:29 (Failed checkpoint trigger time is 20:59:19). 29,272 tags out of the 32,650 tags were printed to the sink before failing. I’m not understanding why it would take so long to just emit and print 32,650 tags? Please advise.
Thank you, Cecile From:
Cecile Kim <[hidden email]> Hi Piotr, Thank you for your response. Good to know about the Start Delay bug. I do believe that the bottleneck occurs when emitting over 28,000 (up to 25million) records all at once in the forward-fill ProcessFunction.
Also, that screenshot below had a problem with the input data stream. Our actual input rate is about
186 records/s. Should I still try setting the configs the same as you suggested?
I will let you know my results of changing the above configuration. Thank you for the links on tuning the network stack. I will go over them more carefully to make sure I understand. I will also try unaligned checkpoints next, if the config
changes alone don’t resolve it. As for eliminating the source of the backpressure, that’s what I’m struggling with at the moment. The failure always occurs as the forward-fill ProcessFunction is emitting a lot of records at once, every 15mins (from 30,000 records up to
over 25million). I replaced the db sink with a print() sink immediately after the forward-fill function, and the failure still occurs. So this is why I thought it was a network buffer/latency issue? We only have one Task Manager though so I don’t understand
why just printing the results would cause backpressure, since there shouldn’t be data transferred between different TMs. Maybe I am not understanding something about the network flow. I was considering trying to resolve the backpressure by drastically reducing the numbers of records emitted by the forward-fill function, but it will take a significant redesign. Do you think this could eliminate the backpressure?
Thank you, Cecile From:
Piotr Nowojski <[hidden email]> Hi, From what you have described indeed it sounds that the backpressure is the most likely explanation. Note that you are using parallelism one, in which case there is a bug/limitation in how the `start delay` metric is calculated, that will
be fixed only in the 1.13.0 [0], so you can not rely on this metric. However keep in mind that "Start Delay" = "End to End duration" - "Sync duration" - "Async duration" With that in mind, your screenshots strongly indicate that the barrier was travelling a very long time (3+ minutes) in this one completed checkpoint. There are a couple of things that you could do 1. Fix the backpressure problem. First you should detect where the bottleneck is and then try to address the problem. Once the backpressure is no longer an issue, checkpoints should be working much quicker. Also make sure that your job is making progress at all, and that it's not completely stuck on something. 2. Reduce the amount of buffered records during the backpressure. Since you have very low records throughput (57 records/s produced at the source) and your records are small (~482bytes/record at the source?), so the total throughput is ~27KB/s. This value is so small, that you can safely reduce the amount
of buffered data. You can reduce both the amount of exclusive buffers per channel (from 2 down to 1) [1] and floating (from 8 to 1 or even 0?) [2] and the buffer size as well [3] (from 32KB to 1KB? 512Bytes?). [1] and [2] will reduce the latency of exchanging
the buffers a bit. Especially if you have just a single buffer, the upstream task will not be able to produce any records while the buffer is being passed to the downstream task. However I doubt you would even notice this delay. Reducing buffer size [3] would
mean that the buffers would need to be exchanged more often, so causing a bit more network traffic, but again, with ~27KB/s you shouldn't notice it. All combined would reduce your buffered data from 320KB down to 512bytes per channel. This should speed up
propagation of the Checkpoint Barriers roughly 640x times. You can read more about how to tune network stack here [6][7] 3. Use Unaligned Checkpoints [4]. However keep in mind that in 1.12.x Unaligned Checkpoints can cause in some rare situations stream corruption in 1.12.x. This will be probably fixed in 1.12.2 [5] Piotrek sob., 30 sty 2021 o 20:26 Cecile Kim <[hidden email]> napisał(a):
|

Re: Checkpoint Failures from Backpressure, possibly due to overloaded network buffers?
|
|
Hi Cecile, Thanks for getting back to us and I'm glad that it's working for you (at least so far). FYI, in Flink 1.13 the back pressure detection should be much easier in the WebUI [1] Piotrek wt., 2 lut 2021 o 07:35 Cecile Kim <[hidden email]> napisał(a):
|

| Free forum by Nabble | Edit this page |