Cannot resume from Savepoint when operator changes

Cannot resume from Savepoint when operator changes

|
Hi experts,
I am using Beam 2.23.0, with flink runner 1.8.2. I am trying to explore when enabling checkpoint and beam kafkaIO EOS, different scenarios to resume a job from a savepoint. I am running Kafka and a standalone flink cluster locally on my laptop. Below are the scenarios that I have tried out: 1. Add a new topic as source Before savepoint: read from input1 and write to output Take a savepoint After savepoint: read from input1 and input2 and write to output Behavior: It did not output messages from input2 2. Remove a topic source Before savepoint: read from input1 and input2 and write to output Take a savepoint After savepoint: read from input1 and write to output Behavior: work as expected, only output messages from input1 3. Add a topic as sink Before savepoint: read from input1 and write to output1 Take a savepoint After savepoint: read from input1 and write to output1 and output2 Behavior: pipeline failed with exception  4. Remove a topic sink Before savepoint: read from input1 and write to output1 and output2 Take a savepoint After savepoint: read from input1 and write to output1 Behavior: It requires to change the sinkGroupId, otherwise get exception  So it looks like resume from savepoint does not really work when there is a change in the DAG for source or sink, I wonder if this is expected behaviour? Is this something to do with how Beam KafkaIO EOS state works or is it something that is related to flink? Thanks a lot! Eleanore |
|
|
Hi Eleanore
When adding an operator of source while savepoint not included, it would run from scratch and fetch the offset depended on your configuration of source connector.
Take the scenario of 'Add a new topic as source' for example, job would consume the new input2 source with offset based on the configuration of your kafka connector.
On the other hand, take the scenario of 'Remove a topic source' for example, job needs to enable non-restored-state to resume from savepoint and drop the useless input2.
This is the general procedure for resuming savepint, and different operator/connector/sink could have its rule to consume or write to external systems. Already cc Becket who is expert at Kafka and could offer more information about kafka source and sink.
Best
Yun Tang
From: Eleanore Jin <[hidden email]>
Sent: Monday, August 10, 2020 23:58 To: user <[hidden email]> Subject: Cannot resume from Savepoint when operator changes Hi experts,
I am using Beam 2.23.0, with flink runner 1.8.2. I am trying to explore when enabling checkpoint and beam kafkaIO EOS, different scenarios to resume a job from a savepoint. I am running Kafka and a standalone flink cluster locally on my laptop.
Below are the scenarios that I have tried out:
1. Add a new topic as source
Before savepoint: read from input1 and write to output
Take a savepoint
After savepoint: read from input1 and input2 and write to output
Behavior: It did not output messages from input2
2. Remove a topic source
Before savepoint: read from input1 and input2 and write to output
Take a savepoint
After savepoint: read from input1 and write to output
Behavior: work as expected, only output messages from input1
3. Add a topic as sink
Before savepoint: read from input1 and write to output1
Take a savepoint
After savepoint: read from input1 and write to output1 and output2
Behavior: pipeline failed with exception
 4. Remove a topic sink
Before savepoint: read from input1 and write to output1 and output2
Take a savepoint
After savepoint: read from input1 and write to output1
Behavior: It requires to change the sinkGroupId, otherwise get exception
 So it looks like resume from savepoint does not really work when there is a change in the DAG for source or sink, I wonder if this is expected behaviour? Is this something to do with how Beam KafkaIO EOS state works or is it something that is related to
flink?
Thanks a lot!
Eleanore
|
Re: Cannot resume from Savepoint when operator changes
|
|
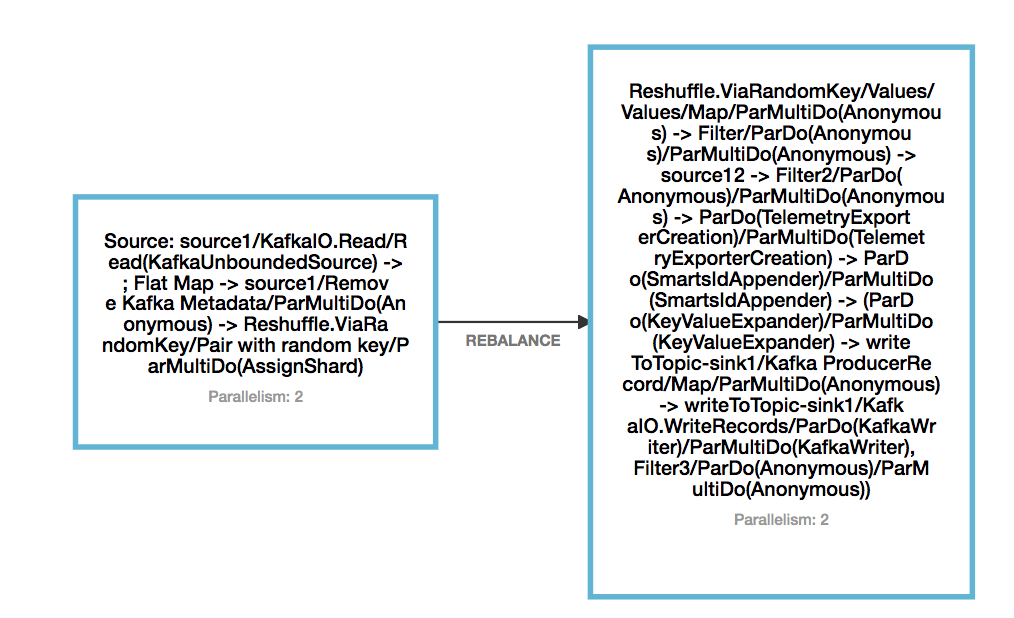
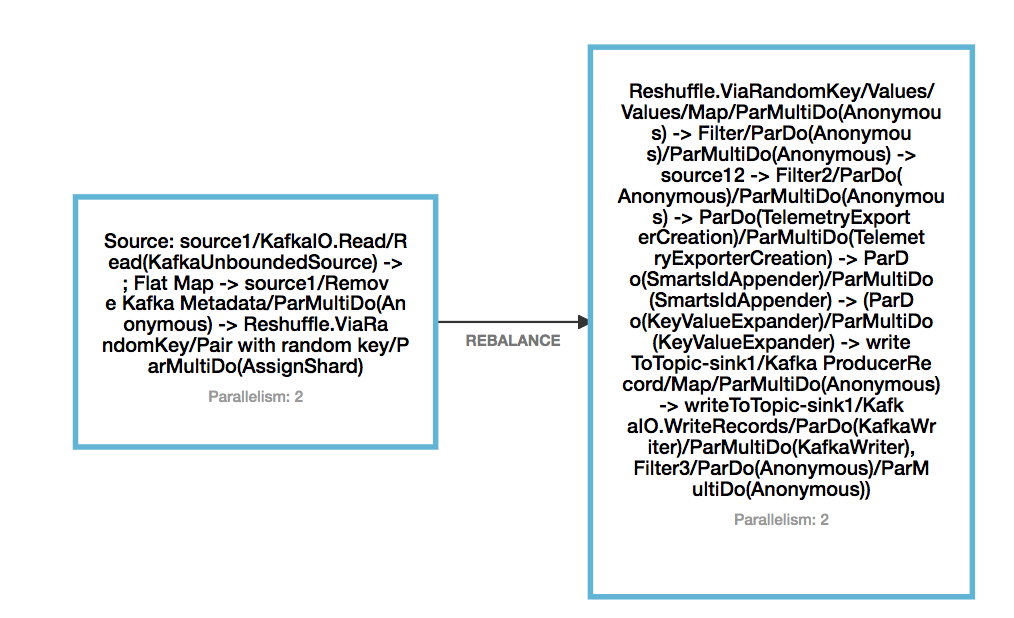
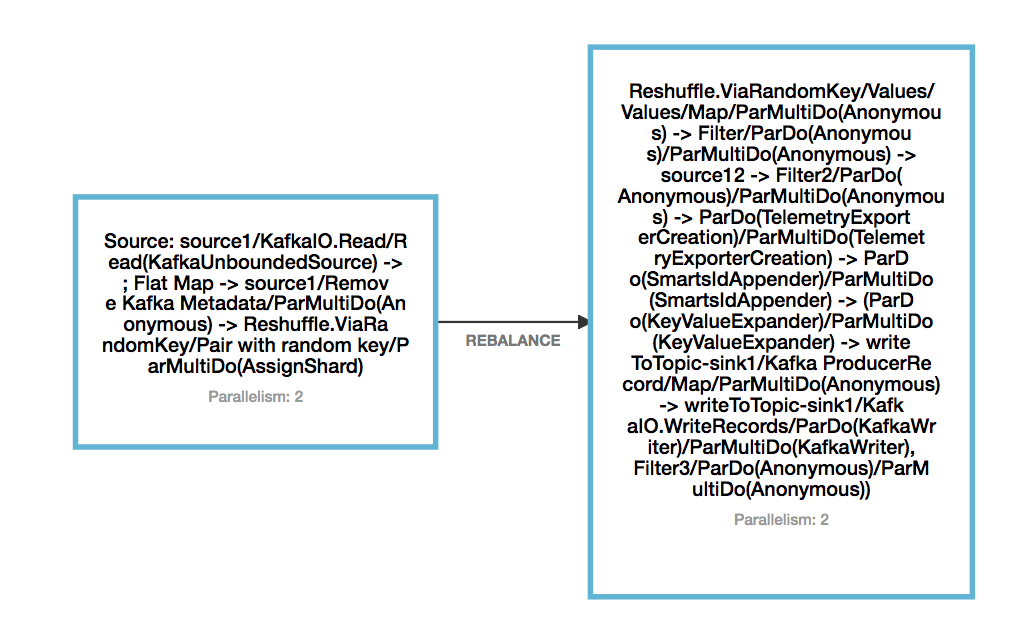
Hi Yun, Thanks a lot for the reply. Later on I was able to make adding a new kafka topic as source working, which requires to add a Reshuffle operation after the source. The reason I came up to find this is: I was trying the monitoring API: GET /jobs/<jobId> to acquire the information of vertices. What I found out is: without Reshuffle, Beam seems chaining up all the operators together, and when include another source, the DAG changed, so savepoint cannot be mapped back to the original source. I have attached the DAG for 1 source and 1 sink, without reshuffle and with reshuffle. However even by adding reshuffle, this scenario does not work: original DAG: read from topic1 and publish to topic2 Take a savepoint, cancel the job changed DAT: read from topic3 instead of topic1 and publish to topic2 Resume from savepoint. The behavior after resume is: there is no message output to topic2, and from the log, I did not see Kakfa consumer for topic3 being created. So I have an assumption: if just adding a new stateful operator, or just removing a stateful operator, it works fine when resume from savepoint. But if add a new stateful operator and remove an existing stateful operator, then cannot resume from savepoint. Can you please help me clarify my doubt? Thanks a lot! Eleanore  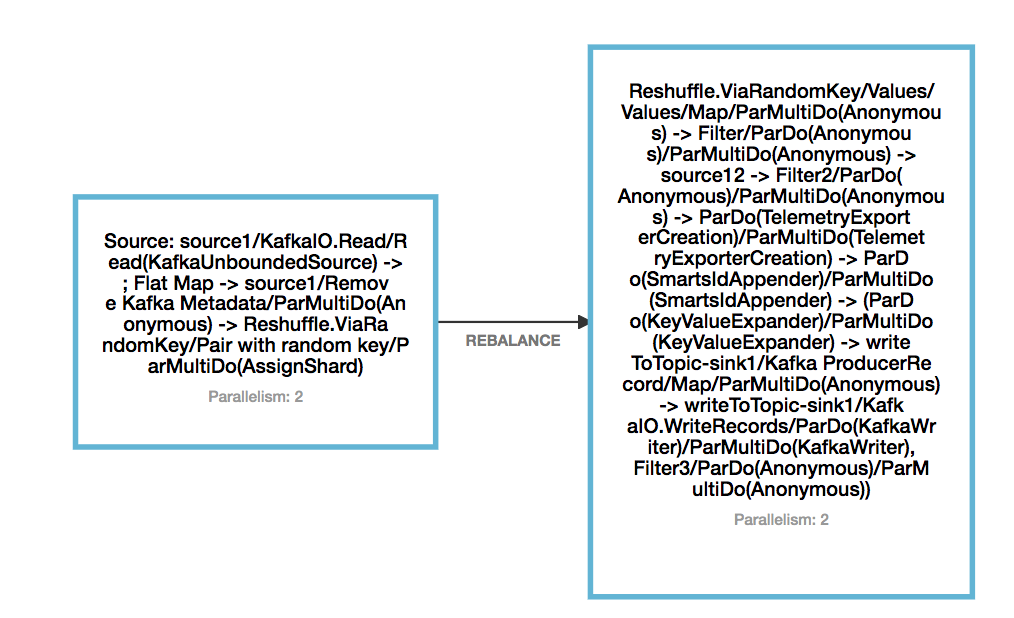 On Thu, Aug 13, 2020 at 3:34 AM Yun Tang <[hidden email]> wrote:
|


Re: Cannot resume from Savepoint when operator changes
|
|
Hi Eleanore, according to the savepoint FAQ [1], removing an operator is still possible if use the setting --allowNonRestoredState (short: -n) with the run command: $ bin/flink run -s :savepointPath -n [:runArgs] On Thu, Aug 13, 2020 at 6:29 PM Eleanore Jin <[hidden email]> wrote:
-- Arvid Heise | Senior Java Developer Follow us @VervericaData -- Join Flink Forward - The Apache Flink Conference Stream Processing | Event Driven | Real Time -- Ververica GmbH | Invalidenstrasse 115, 10115 Berlin, Germany -- Ververica GmbHRegistered at Amtsgericht Charlottenburg: HRB 158244 B Managing Directors: Timothy Alexander Steinert, Yip Park Tung Jason, Ji (Toni) Cheng |



|
|
Hi Eleanore
The prerequisite of resuming from savepoint is that we need to ensure the previous operator ids not change in the new DAG and you could think of a savepoint as holding a map of
Operator ID -> State for each stateful operator[1]. That's why we recommend to set uid for those operators [2]. As I am not familiar with Beam, and not sure whether Beam would assign the operator ids.
If the operator ids are not assigned well at the beginning, attach a new stateful operator might change those previous operator ids.
One way to check this is loading your savepoint before and after you change the DAG to see whether the operator id changed. And you could use
Checkpoints#loadCheckpointMetadata
to load savepoint meta data.
[1]
https://ci.apache.org/projects/flink/flink-docs-stable/ops/state/savepoints.html#savepoint-state
Best,
Yun Tang From: Arvid Heise <[hidden email]>
Sent: Friday, August 14, 2020 3:36 To: Eleanore Jin <[hidden email]> Cc: Yun Tang <[hidden email]>; user <[hidden email]>; Becket Qin <[hidden email]> Subject: Re: Cannot resume from Savepoint when operator changes Hi Eleanore,
according to the savepoint FAQ [1], removing an operator is still possible if use the setting --allowNonRestoredState (short: -n) with the run command:
$ bin/flink run -s :savepointPath -n [:runArgs] On Thu, Aug 13, 2020 at 6:29 PM Eleanore Jin <[hidden email]> wrote:
-- Arvid Heise | Senior Java Developer Follow us @VervericaData -- Join Flink Forward - The Apache Flink Conference Stream Processing | Event Driven | Real Time -- Ververica GmbH | Invalidenstrasse 115, 10115 Berlin, Germany -- Ververica GmbHRegistered at Amtsgericht Charlottenburg: HRB 158244 B Managing Directors: Timothy Alexander Steinert, Yip Park Tung Jason, Ji (Toni) Cheng |



Re: Cannot resume from Savepoint when operator changes
|
|
Hi Yun, Thanks a lot for the direction! I checked how Beam pipeline gets translated into the Flink job, below is the snapshot of the code, please see the highlighted red comments try { nonDedupSource = // this nonDedupSource has the uid setup, in my case, it is "source1/KafkaIO.Read/Read(KafkaUnboundedSource)" And from the Web UI, I see the nonDedupSource (which has UID), and flatMap are chained together, but only the highlighted read part has UID assigned. 1. So does that mean the chained operations are treated together as 1 operator, which is represented by "source" in the above code, which does not have an UID assigned, and that is why it is not working? 2. If the above statement is true, what I observe is that after changing the DAG to read from a different source topic, it is not getting processed by the new flink job. Actually I don't even see the Kafka consumer get created for the new source topic. Is this behaviour expected if the resume from savepoint fails? Thanks a lot for the help! Eleanore On Thu, Aug 13, 2020 at 8:20 PM Yun Tang <[hidden email]> wrote:
|




|
|
Hi Eleanore
Assigning uid to all operators is the key point to ensure state could be restored as expected no matter what changes introduced to the new DAG.
For the 2nd question, savepoint does not store previous job graph and it should not prevent you to create the Kafka consumer for the new source topic unless kafka consumer has some internal logic for this behavior.
You could try to start the job without resuming from the savepoint to see whether the Kafka consumer is created.
Best
Yun Tang
From: Eleanore Jin <[hidden email]>
Sent: Friday, August 14, 2020 14:08 To: Yun Tang <[hidden email]> Cc: Arvid Heise <[hidden email]>; user <[hidden email]>; Becket Qin <[hidden email]> Subject: Re: Cannot resume from Savepoint when operator changes Hi Yun,
Thanks a lot for the direction! I checked how Beam pipeline gets translated into the Flink job, below is the snapshot of the code,
please see the highlighted red comments
try { nonDedupSource = // this nonDedupSource has the uid setup, in my case, it is "source1/KafkaIO.Read/Read(KafkaUnboundedSource)" And from the Web UI, I see the nonDedupSource (which has UID), and flatMap are chained together, but only the highlighted read part has UID assigned. 1. So does that mean the chained operations are treated together as 1 operator, which is represented by "source" in the above code, which does not have an UID assigned, and that is why it is not working? 2. If the above statement is true, what I observe is that after changing the DAG to read from a different source topic, it is not getting processed by the new flink job. Actually I don't even see the Kafka consumer get created for the new source topic. Is this behaviour expected if the resume from savepoint fails? Thanks a lot for the help! Eleanore On Thu, Aug 13, 2020 at 8:20 PM Yun Tang <[hidden email]> wrote:
|


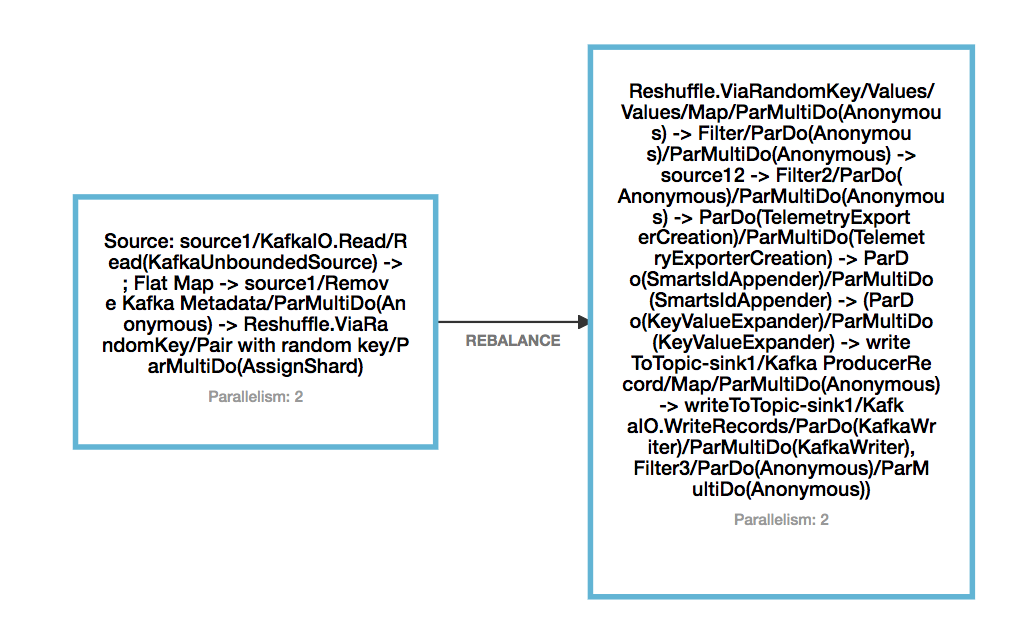


Re: Cannot resume from Savepoint when operator changes
|
|
Hi Yun, thanks for the response. I actually made it working. The missing part is: 1. if I do not introduce reshuffle from beam (which is flink rebalance partition), then it is not working, if not resume from savepoint, I see the consumer for the new source topic gets created, but when resume from savepoint, it is not. 2. if I introduce reshuffle, and assign UID for reshuffle operator, then it is able to resume from savepoint even I change the source topic from topic1 to topic2. Thanks a lot for your help! Eleanore On Tue, Aug 18, 2020 at 10:59 AM Yun Tang <[hidden email]> wrote:
|




| Free forum by Nabble | Edit this page |