Can't find correct JobManager address, job fails with Queryable state

Can't find correct JobManager address, job fails with Queryable state

|
When I start my flink job I get the following warning, if I am not wrong this is because it can't find the jobmanager at the given address(localhost), I tried changing:
config.setString(JobManagerOptions.ADDRESS, "localhost"); to LAN IP, 127.0.0.1 and localhost but none of it seems to work. I am not really sure what I am doing wrong here. 2017-08-02 17:20:26,137 INFO [Remoting] - Remoting started; listening on addresses :[akka.tcp://flink@169.254.65.27:53923] 2017-08-02 17:20:26,140 INFO [Remoting] - Remoting started; listening on addresses :[akka.tcp://flink@169.254.65.27:53920] 2017-08-02 17:20:26,154 INFO [Remoting] - Remoting started; listening on addresses :[akka.tcp://flink@169.254.65.27:53921] 2017-08-02 17:20:26,163 INFO [Remoting] - Remoting started; listening on addresses :[akka.tcp://flink@169.254.65.27:53922] 2017-08-02 17:20:26,166 INFO [AbstractCoordinator] - Discovered coordinator airpluspoc-hdp-dn0.germanycentral.cloudapp.microsoftazure.de:9092 (id: 2147482644 rack: null) for group flink-dqm. 2017-08-02 17:20:27,493 WARN [ReliableDeliverySupervisor] - Association with remote system [akka.tcp://flink@localhost:6123] has failed, address is now gated for [5000] ms. Reason: [Association failed with [akka.tcp://flink@localhost:6123]] Caused by: [Connection refused: no further information] 2017-08-02 17:20:27,493 WARN [ReliableDeliverySupervisor] - Association with remote system [akka.tcp://flink@localhost:6123] has failed, address is now gated for [5000] ms. Reason: [Association failed with [akka.tcp://flink@localhost:6123]] Caused by: [Connection refused: no further information] 2017-08-02 17:20:27,493 WARN [ReliableDeliverySupervisor] - Association with remote system [akka.tcp://flink@localhost:6123] has failed, address is now gated for [5000] ms. Reason: [Association failed with [akka.tcp://flink@localhost:6123]] Caused by: [Connection refused: no further information] 2017-08-02 17:20:27,493 WARN [ReliableDeliverySupervisor] - Association with remote system [akka.tcp://flink@localhost:6123] has failed, address is now gated for [5000] ms. Reason: [Association failed with [akka.tcp://flink@localhost:6123]] Caused by: [Connection refused: no further information] and then it fails while accessing the queryable state with the following error: akka.actor.ActorNotFound: Actor not found for: ActorSelection[Anchor(akka.tcp://flink@localhost:6123/), Path(/user/jobmanager)] Also, I wanted to check the jobmanager UI and for this I set up my job as follows: Configuration conf = new Configuration(); conf.setBoolean(ConfigConstants.LOCAL_START_WEBSERVER, true); StreamExecutionEnvironment env = LocalStreamEnvironment.createLocalEnvironmentWithWebUI(conf); and I couldn't even access the flink UI at localhost:8081 and other addresses as well. What would be the best way to find and access the jobmanager address and UI? Thanks and Regards Biplob |
Re: Can't find correct JobManager address, job fails with Queryable state
|
|
I managed to get the Web UI up and running but I am still getting the error with "Actor not found"
Before the job failed I got the output for the Flink config from the WebUI and it seems okay to me, this corresponds to the config I have already set. 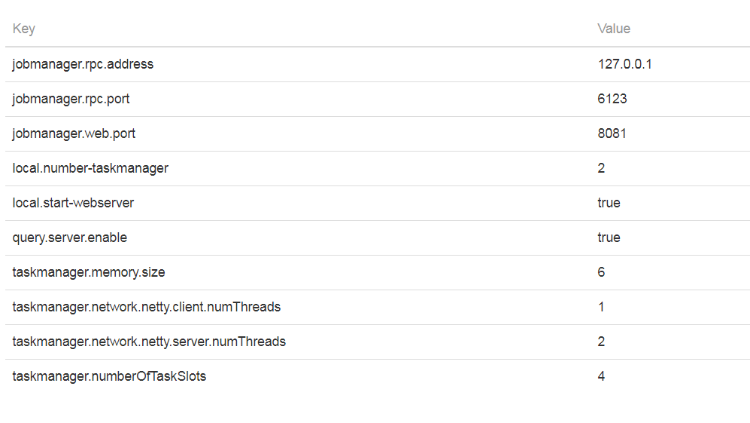 But when I try to access my shared store (from the same job), I get the error with the following stacktrace: Exception in thread "main" org.apache.flink.runtime.client.JobExecutionException: Job execution failed.
|
Re: Can't find correct JobManager address, job fails with Queryable state
|
|
Hi Biplob,
by starting a local environment the way you described, i.e. by using LocalStreamEnvironment.createLocalEnvironmentWithWebUI(conf); you are firing up a LocalFlinkMiniCluster which, by default, has the queryable state server disabled. You can enable it via: config.setBoolean(QueryableStateOptions.SERVER_ENABLE, true); Nico On Thursday, 3 August 2017 11:40:12 CEST Biplob Biswas wrote: > I managed to get the Web UI up and running but I am still getting the error > with "Actor not found" > > Before the job failed I got the output for the Flink config from the WebUI > and it seems okay to me, this corresponds to the config I have already set. > > <http://apache-flink-user-mailing-list-archive.2336050.n4.nabble.com/file/n1 > 4653/flinkconfig.png> > > > But when I try to access my shared store (from the same job), I get the > error with the following stacktrace: > > > Exception in thread "main" > org.apache.flink.runtime.client.JobExecutionException: Job execution failed. > at > org.apache.flink.runtime.jobmanager.JobManager$$anonfun$handleMessage$1$$ano > nfun$applyOrElse$7.apply$mcV$sp(JobManager.scala:933) at > org.apache.flink.runtime.jobmanager.JobManager$$anonfun$handleMessage$1$$ano > nfun$applyOrElse$7.apply(JobManager.scala:876) at > org.apache.flink.runtime.jobmanager.JobManager$$anonfun$handleMessage$1$$ano > nfun$applyOrElse$7.apply(JobManager.scala:876) at > scala.concurrent.impl.Future$PromiseCompletingRunnable.liftedTree1$1(Future. > scala:24) at > scala.concurrent.impl.Future$PromiseCompletingRunnable.run(Future.scala:24) > at akka.dispatch.TaskInvocation.run(AbstractDispatcher.scala:40) > at > akka.dispatch.ForkJoinExecutorConfigurator$AkkaForkJoinTask.exec(AbstractDis > patcher.scala:397) at > scala.concurrent.forkjoin.ForkJoinTask.doExec(ForkJoinTask.java:260) at > scala.concurrent.forkjoin.ForkJoinPool$WorkQueue.runTask(ForkJoinPool.java:1 > 339) at > scala.concurrent.forkjoin.ForkJoinPool.runWorker(ForkJoinPool.java:1979) at > scala.concurrent.forkjoin.ForkJoinWorkerThread.run(ForkJoinWorkerThread.java > :107) Caused by: akka.actor.ActorNotFound: Actor not found for: > ActorSelection[Anchor(akka.tcp://flink@127.0.0.1:6123/), > Path(/user/jobmanager)] > at > akka.actor.ActorSelection$$anonfun$resolveOne$1.apply(ActorSelection.scala:6 > 5) at > akka.actor.ActorSelection$$anonfun$resolveOne$1.apply(ActorSelection.scala:6 > 3) at scala.concurrent.impl.CallbackRunnable.run(Promise.scala:32) > at > akka.dispatch.BatchingExecutor$AbstractBatch.processBatch(BatchingExecutor.s > cala:55) at > akka.dispatch.BatchingExecutor$Batch.run(BatchingExecutor.scala:73) at > akka.dispatch.ExecutionContexts$sameThreadExecutionContext$.unbatchedExecute > (Future.scala:74) at > akka.dispatch.BatchingExecutor$class.execute(BatchingExecutor.scala:120) at > akka.dispatch.ExecutionContexts$sameThreadExecutionContext$.execute(Future.s > cala:73) at > scala.concurrent.impl.CallbackRunnable.executeWithValue(Promise.scala:40) > at > scala.concurrent.impl.Promise$DefaultPromise.tryComplete(Promise.scala:248) > at akka.pattern.PromiseActorRef.$bang(AskSupport.scala:266) > at akka.actor.EmptyLocalActorRef.specialHandle(ActorRef.scala:533) > at akka.actor.DeadLetterActorRef.specialHandle(ActorRef.scala:569) > at akka.actor.DeadLetterActorRef.$bang(ActorRef.scala:559) > at > akka.remote.RemoteActorRefProvider$RemoteDeadLetterActorRef.$bang(RemoteActo > rRefProvider.scala:87) at > akka.remote.EndpointWriter.postStop(Endpoint.scala:583) > at akka.actor.Actor$class.aroundPostStop(Actor.scala:477) > at akka.remote.EndpointActor.aroundPostStop(Endpoint.scala:437) > at > akka.actor.dungeon.FaultHandling$class.akka$actor$dungeon$FaultHandling$$fin > ishTerminate(FaultHandling.scala:210) at > akka.actor.dungeon.FaultHandling$class.terminate(FaultHandling.scala:172) > at akka.actor.ActorCell.terminate(ActorCell.scala:369) > at akka.actor.ActorCell.invokeAll$1(ActorCell.scala:462) > at akka.actor.ActorCell.systemInvoke(ActorCell.scala:478) > at akka.dispatch.Mailbox.processAllSystemMessages(Mailbox.scala:263) > at akka.dispatch.Mailbox.run(Mailbox.scala:219) > ... 5 more > > > > > > > -- > View this message in context: > http://apache-flink-user-mailing-list-archive.2336050.n4.nabble.com/Can-t-f > ind-correct-JobManager-address-job-fails-with-Queryable-state-tp14644p14653. > html Sent from the Apache Flink User Mailing List archive. mailing list > archive at Nabble.com. |
Re: Can't find correct JobManager address, job fails with Queryable state
|
|
Hi Nico,
I had actually tried doing that but I still get the same error as before with the actor not found. I then ran on my mock cluster and I was getting the same error although I could observe the jobmanager on the yarn cluster mode with a defined port. The addres and port combination was random and as mentioned here , the the JobManager is always allocated at different machines. So to circumvent this issue, I created a flink yarn session and ran my job within this session. As the jobmanager is fixed within a yarn session, so I set my jobmanager address and port using the corresponding data. Now it can connect to jobmanager (only on cluster, still not on local mode) but the job id I specified was wrong and I don't really know how to fetch the jobid of my flink job within a running instance. Thanks, Biplob |
Re: Can't find correct JobManager address, job fails with Queryable state
|
|
Hi,
I'm afraid you are running into roughly this problem: https://issues.apache.org/jira/browse/FLINK-6689 It's not possible anymore to connect to a LocalFlinkMiniCluster, either via a RemoteExecutionEnvironment or via the queryable state client. Best, Aljoscha
|
Re: Can't find correct JobManager address, job fails with Queryable state
|
|
Thanks Aljoscha, this clarification probably ends my search of accessing local states from within the same job.
Thanks for the help :) |
«
Return to (DEPRECATED) Apache Flink User Mailing List archive.
|
1 view|%1 views
| Free forum by Nabble | Edit this page |